Deep Reinforcement Learning for Optimal Portfolio Allocation: A Comparative Study with Mean-Variance Optimization
Abstract: Portfolio Management is the process of overseeing a group of investments, referred to as a portfolio, with the objective of achieving predetermined investment goals. Portfolio optimization is a key component that involves allocating the portfolio assets so as to maximize returns while minimizing risk taken. It is typically carried out by financial professionals who use a combination of quantitative techniques and investment expertise to make decisions about the portfolio allocation. Recent applications of Deep Reinforcement Learning (DRL) have shown promising results when used to optimize portfolio allocation by training model-free agents on historical market data. Many of these methods compare their results against basic benchmarks or other state-of-the-art DRL agents but often fail to compare their performance against traditional methods used by financial professionals in practical settings. One of the most commonly used methods for this task is Mean-Variance Portfolio Optimization (MVO), which uses historical time series information to estimate expected asset returns and covariances, which are then used to optimize for an investment objective. Our work is a thorough comparison between model-free DRL and MVO for optimal portfolio allocation. We detail the specifics of how to make DRL for portfolio optimization work in practice, also noting the adjustments needed for MVO. Backtest results demonstrate strong performance of the DRL agent across many metrics, including Sharpe ratio, maximum drawdowns, and absolute returns.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Deep Reinforcement Learning for Optimal Portfolio Allocation — A teen-friendly summary
What this paper is about (the big picture)
The paper asks a simple question: What’s a better way to decide how to split your money across different investments—using a traditional math method or using a smart computer program that learns by trying things out? The authors compare:
- A classic method used by many pros called Mean-Variance Optimization (MVO).
- A newer approach using Deep Reinforcement Learning (DRL), where an “agent” learns how to allocate money by practicing on past market data.
Their goal is to see which one builds a portfolio that earns more while taking less risk.
What questions the researchers wanted to answer
In everyday terms, they wanted to know:
- Can a learning agent (DRL) build a better, steadier investment portfolio than a traditional math-based method (MVO)?
- If both methods aim for “good return for the risk taken,” which one does better over many years?
- Does the learning approach trade less often (which would be good in real life because trading costs money)?
How they approached the problem (in simple terms)
Think of building a portfolio like packing your backpack for a long trip:
- You want useful items (returns) but don’t want it to be too heavy (risk).
- The classic method (MVO) is like using a checklist: “Based on past experiences, take this much of item A and that much of item B to balance usefulness and weight.”
- The learning method (DRL) is like a person who tries different packing choices over many practice trips, keeps score based on comfort and usefulness, and gradually learns a better packing plan.
Here’s what they did:
- Data and assets:
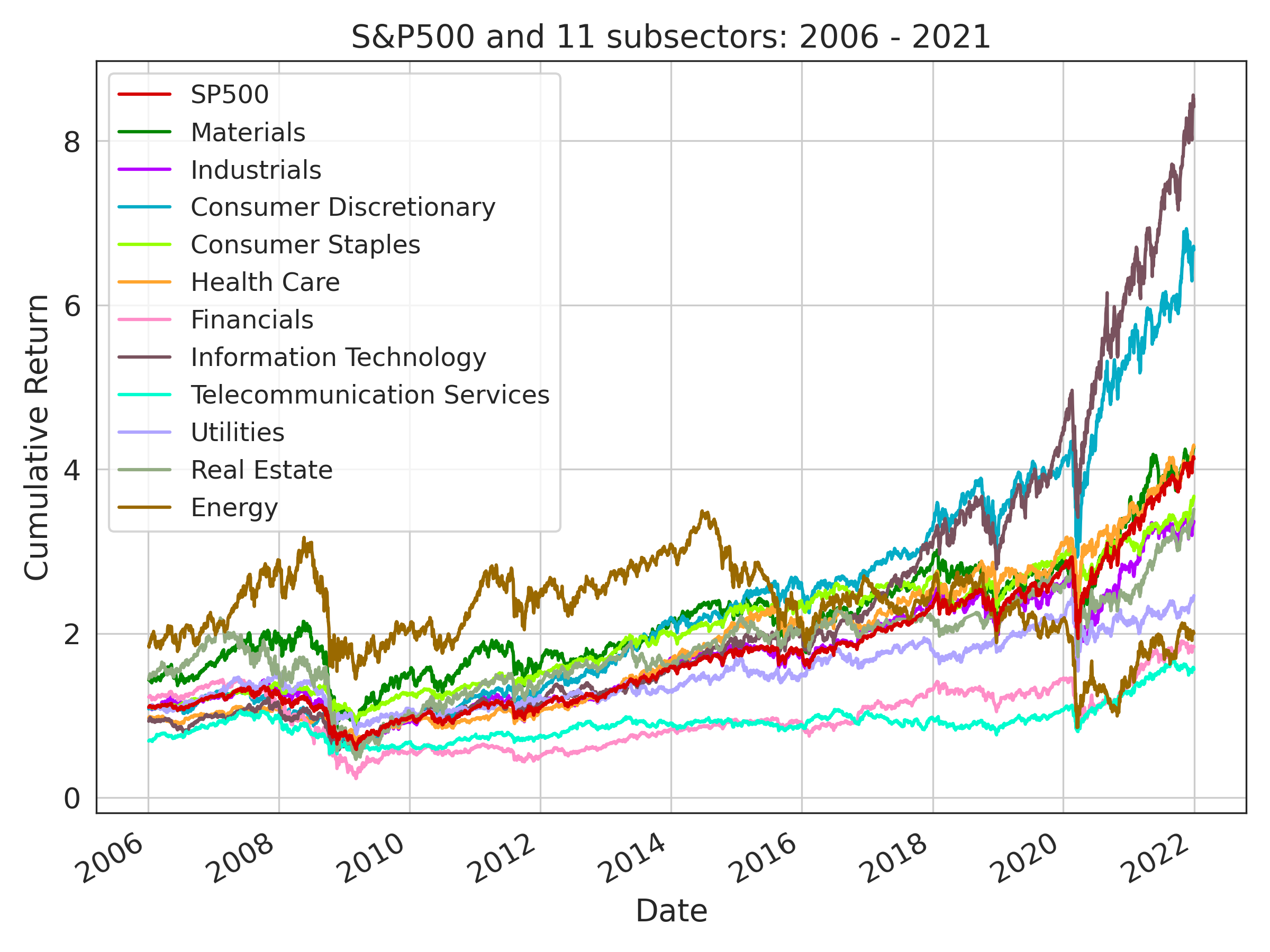
- They used daily prices for the 11 S&P 500 sector indices (like Technology, Health Care, Energy, etc.), the overall S&P 500, and the VIX (a “fear index” that reflects market volatility), from 2006 to 2021.
- The portfolio is long-only (no shorting), not leveraged, and always fully invested (weights add up to 1).
- For fairness and focus, they did not include trading costs in the tests.
- What “risk-adjusted return” means:
- Instead of just chasing high returns, they focus on how much return you get per unit of risk. A common measure for this is the Sharpe ratio. You can think of it like “points per game minute” in sports—how efficient your performance is.
- The DRL approach (the learning agent):
- The agent “sees” recent information (like 60 days of returns for each sector and some market volatility signals such as 20-day volatility, the ratio of 20-day to 60-day volatility, and the VIX).
- Each day, it chooses how to split money across sectors (the “action”).
- It gets rewarded based on a daily version of the Sharpe ratio (called the differential Sharpe), which encourages steady returns with controlled risk.
- Over time, it learns what choices tend to lead to better risk-adjusted results.
- They trained the agent using PPO (Proximal Policy Optimization), a popular, stable learning algorithm often used in games and robotics.
- The MVO approach (the classic checklist):
- MVO estimates expected returns and how the assets move together (covariances) using a 60-day lookback.
- It then solves a math problem to pick the mix that maximizes the Sharpe ratio.
- To make the math more reliable, they used a technique called Ledoit–Wolf shrinkage to improve covariance estimates.
- Training and testing (backtesting):
- They split the 2006–2021 data into 10 overlapping “train/validate/test” windows. For each window:
- Train the DRL agent on 5 years.
- Validate on 1 year (a “burn-in” period).
- Test on the next year (out-of-sample).
- MVO doesn’t “train,” but it used the same 60-day rolling window during testing for fair timing.
- Both methods started each test year with $100,000 in cash and rebalanced daily using their chosen weights.
- They tested years 2012–2021 and compared results.
What they found (the main results)
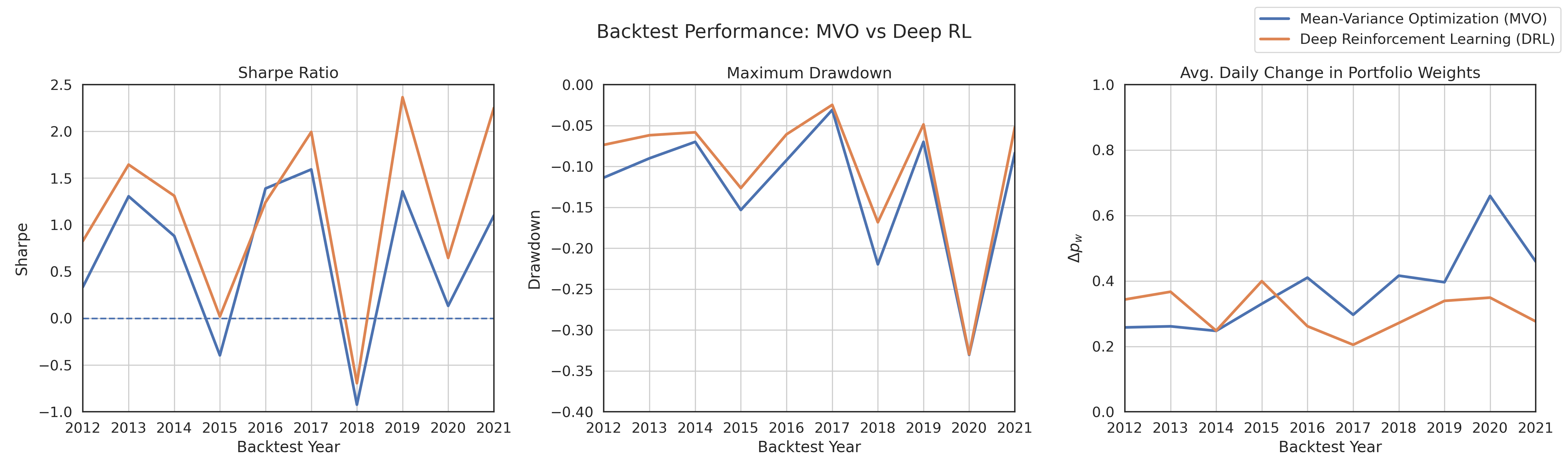
Overall, the DRL agent did better than MVO across most important measures:
- Higher returns with less “bounciness”:
- Average annual return: about 12.1% for DRL vs. 6.5% for MVO.
- Sharpe ratio (return per unit risk): about 1.17 for DRL vs. 0.68 for MVO. Higher is better.
- Annual volatility (how much it swings): lower for DRL.
- Drawdowns (big drops from a peak):
- The worst drop was similar for both (around −33%), but DRL tended to have smaller worst drops year by year.
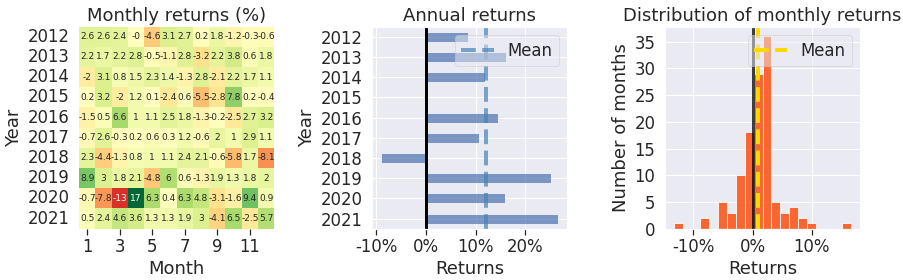
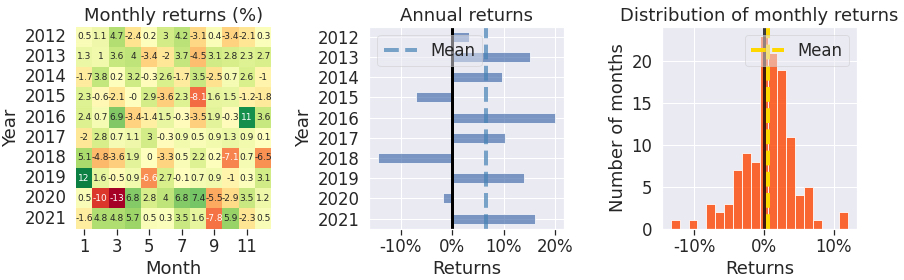
- Consistency and trading activity:
- DRL’s monthly and yearly returns were steadier.
- DRL changed its portfolio less often (lower turnover), especially during chaotic times like March 2020. In real life, this could mean lower trading costs.
Why this matters: Getting more return per unit of risk, with steadier performance and fewer trades, is exactly what many investors want.
Why this is important and what it could change
- It shows that a learning-based method can adapt to changing markets and make practical, risk-aware choices.
- DRL could help professionals build portfolios that are more stable and potentially cheaper to run (fewer trades).
- It encourages fairer comparisons in research by aligning goals (both methods aimed at maximizing risk-adjusted returns).
A few things to keep in mind
- They didn’t include real-world trading costs or delays (slippage). In live markets, costs matter; DRL’s lower trading might help here, but it still needs to be tested with costs.
- The test used sector indices (broad groups), not individual stocks. Results may differ for other assets.
- Past performance on historical data (backtesting) doesn’t guarantee future results.
Bottom line
The paper finds that a well-designed, risk-aware learning agent (DRL using PPO) can beat a classic portfolio math method (MVO) in backtests, delivering higher, steadier risk-adjusted returns with fewer portfolio changes. If confirmed with real trading costs and in more markets, this approach could help investors manage money more effectively.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of what the paper leaves missing, uncertain, or unexplored, framed to be concrete and actionable for future research.
- External validity of results: The study is restricted to long-only allocation across 11 S&P 500 sector indices and cash over 2012–2021 out-of-sample; it does not assess generalization to individual equities, other asset classes (fixed income, commodities, FX), non-US markets, or different market regimes beyond 2020.
- Investability and data realism: The backtests trade index levels (Yahoo Finance) rather than investable instruments (e.g., sector ETFs). Performance is likely sensitive to ETF tracking, distributions, and fund frictions; replicate on liquid sector ETFs (e.g., SPDRs) with actual investability constraints.
- Omission of transaction costs, slippage, and market impact: Neither strategy accounts for trading frictions. Introduce realistic cost models (commissions, bid–ask spreads, slippage, market impact, borrow costs for shorts if enabled) and compare net-of-costs performance, especially in stressed liquidity periods (e.g., March 2020).
- Information parity between DRL and MVO: The DRL agent’s state includes exogenous regime signals (VIX, vol20, vol20/vol60), while MVO uses only returns and covariances. To avoid biased benchmarking, either remove exogenous signals from DRL or supply regime-aware information to MVO (e.g., conditional estimates or regime-switching MVO).
- Objective comparability: DRL optimizes Differential Sharpe Ratio online with EMA smoothing (η ≈ 1/252); MVO solves a static Sharpe maximization per day using 60-day estimates. Quantify how these differing objective horizons and estimation mechanisms affect comparability; test MVO variants closer to the DRL reward (e.g., rolling optimization with turnover penalties).
- Training protocol fairness: DRL employs transfer learning (the best agent from one window seeds the next). MVO has no analogous prior; evaluate DRL without transfer seeding and/or allow MVO to use Bayesian priors (e.g., Black–Litterman) to balance prior information usage.
- Strength of MVO baseline: MVO uses 60-day sample means (highly noisy) and Ledoit–Wolf covariance shrinkage. Compare DRL against more robust industry baselines (Black–Litterman, resampled MVO, robust mean estimators, conditional covariance models, regime-switching MVO, turnover-constrained MVO) and perform sensitivity to lookback length and shrinkage intensity.
- Rebalancing frequency and constraint space: Results are limited to daily rebalancing, long-only, no leverage/shorting, and whole-share trading. Assess performance under weekly/monthly rebalancing, leverage and shorting permission, sector/exposure bounds, and explicit turnover constraints.
- Cash treatment and risk-free rate: Cash is assumed to earn 0% and is treated as an asset. Clarify whether cash interest is credited; evaluate sensitivity to non-zero risk-free rates and analyze average cash allocation’s contribution to DRL outperformance.
- Statistical significance: The paper reports average metrics but no confidence intervals or hypothesis tests. Apply block bootstrapping or HAC methods to test the statistical significance and robustness of Sharpe, returns, and drawdown differences.
- Robustness and sensitivity analyses: No sensitivity is provided for PPO hyperparameters, network architecture, η in DSR, state design (lookback length T), or feature set. Quantify stability of outcomes under parameter perturbations and alternative architectures/algorithms.
- Episode construction and potential data reuse: Training uses market replay with 7.5M timesteps and 600 episodes per environment, but the method for defining episode start/end points and overlap is unspecified. Detail episode generation to rule out inadvertent data leakage and assess its impact on learning stability.
- Seed variability and dispersion: DRL results are averaged over five seeds, but dispersion and worst-case outcomes are not reported. Provide distributional performance across seeds and analyze whether ensemble averaging is necessary for stability.
- Turnover measurement: Δp_w (allocation change) is an indirect proxy. Compute standard turnover metrics (e.g., traded notional as a percent of portfolio per day/month) and link them to explicit cost models; compare strategies net-of-costs under matched turnover constraints.
- Regime coverage: Out-of-sample tests exclude the 2008–2009 crisis (it is only in training). Add OOS windows covering earlier crises and diverse macro environments to stress-test generalization.
- Interpretability and policy diagnostics: The paper does not analyze how the DRL policy responds to states (e.g., feature importance, action maps by regime). Provide diagnostics to understand decision drivers and risk controls, and to detect overfitting or unintended behaviors.
- Code, data, and reproducibility: Implementation details (data pipeline, preprocessing, episode generation, PyPortfolioOpt settings, exact MVO constraints) and code artifacts are not released. Publish reproducible code and configuration to enable independent verification.
- Benchmark breadth: The comparison uses PPO vs a single MVO variant. Extend to multiple RL algorithms (A2C/A3C, SAC, DDPG, TD3) and traditional baselines (equal-weight, risk-parity, minimum variance, trend-following, momentum) under identical constraints.
- Whole-share rounding effects: Rounding may introduce bias or drift, potentially affecting MVO more if it produces extreme weights. Quantify the impact of rounding versus fractional-share trading and ensure both methods face identical implementation constraints.
- Reward horizon calibration: DSR with η = 1/252 implies a one-year EMA horizon. Verify alignment with evaluation windows and test alternative reward formulations (e.g., utility with drawdown penalties, mean–variance with turnover/cost terms) to assess trade-offs between return, risk, and stability.
Practical Applications
Immediate Applications
Based on the paper’s findings and implementation details, the following applications can be deployed now, with appropriate guardrails and minimal adaptation.
- Sector-rotation strategy for asset managers (finance)
- Use a PPO-based DRL allocator to dynamically weight S&P 500 sector ETFs plus cash, targeting maximization of risk-adjusted returns (Sharpe), with constraints: long-only, non-levered, weights sum to 1.
- Tools/workflows: StableBaselines3 PPO, PyPortfolioOpt (for classical baseline), Pyfolio for evaluation, Yahoo Finance or institutional data feeds, sliding-window retraining with a 60-day lookback, burn-year validation, seed-ensemble selection.
- Assumptions/dependencies: Integrate realistic transaction costs, slippage, and liquidity controls; adapt to whole-share constraints; compliance with mandate (e.g., long-only SMAs/UMAs); robust data engineering and MLOps for regular retraining and drift monitoring.
- Active overlay for passive portfolios (finance)
- Apply DRL as a lightweight overlay on passive sector index portfolios to adjust sector tilts daily or weekly, reducing drawdowns and turnover relative to MVO.
- Tools/workflows: Volatility features pipeline (20/60-day rolling std, vol ratio, VIX), portfolio rebalance scheduler, risk dashboard monitoring drawdown, turnover, VaR.
- Assumptions/dependencies: Transparent guardrails (max sector tilts, turnover caps); risk budgeting integration; live price and volatility data; broker execution integration; oversight for model risk.
- Lower-turnover execution planning in volatile regimes (finance, trading)
- Exploit the DRL strategy’s empirically lower turnover to cut transaction costs in stressed markets (e.g., March 2020-type events); implement turnover-aware rebalancing thresholds.
- Tools/workflows: Daily Δpw monitoring (allocation change metric), execution rules that gate rebalances by expected slippage, smart order routing.
- Assumptions/dependencies: Calibrated transaction cost model; liquidity and market impact constraints; compliance approval for automated execution rules.
- Quant research and benchmarking framework (academia and industry R&D)
- Adopt the paper’s environment, reward (Differential Sharpe), and PPO hyperparameters as a replicable baseline to compare DRL vs. MVO under aligned objectives.
- Tools/workflows: Reproducible backtesting harness with market replay, vectorized environments (SubProcVecEnv), Ledoit–Wolf covariance shrinkage, standardized evaluation with Pyfolio.
- Assumptions/dependencies: Compute resources for multi-million timestep training; reproducible data splits; model selection protocols avoiding lookahead; governance for research-to-prod transitions.
- Robo-advisory pilot for HNWI or institutional SMAs (finance, wealth management)
- Offer a long-only, risk-adjusted sector allocator as a pilot product for clients seeking dynamic exposure with drawdown-awareness; start with weekly rebalancing and strict risk overlays.
- Tools/workflows: Suitability engine, mandate constraints (e.g., max sector weights, cash floors), periodic retraining schedule, ensemble averaging across seeds for stability.
- Assumptions/dependencies: Regulatory compliance (disclosures, audit trails), robust monitoring for regime shifts and model drift, user education on backtest limitations; real-time data feed reliability.
- Curriculum modules and teaching labs (academia, education)
- Integrate a practical lab comparing DRL vs. MVO under matched Sharpe objectives; emphasize differences in turnover, drawdowns, and validation design.
- Tools/workflows: Jupyter notebooks, StableBaselines3, PyPortfolioOpt, Yahoo Finance data; assignments on feature engineering (volatility, VIX), and burn-year validation.
- Assumptions/dependencies: Clear learning objectives, access to compute and data; caution against overfitting and data leakage.
- Index licensing and custom strategy indices (finance, index providers)
- Construct and license a “DRL Sector Rotation Index” with daily published weights and compliance-friendly constraints (long-only, turnover caps).
- Tools/workflows: Index calculation engine, governance for methodology updates, live publication process.
- Assumptions/dependencies: Independent verification; clear rules for reconstitution/rebalancing; robust contingency planning for data outages.
- Risk management dashboards focused on risk-adjusted performance consistency (finance, risk)
- Deploy dashboards tracking Sharpe, Sortino, drawdowns, and turnover; use DRL’s steadier monthly returns as a signal of process stability compared to classical MVO.
- Tools/workflows: Daily analytics pipeline, anomaly detection on risk metrics, escalation runbooks.
- Assumptions/dependencies: Accurate calculation of risk metrics with updated risk-free assumptions; alignment with firm risk tolerance; governance for strategy pauses.
- Advanced retail enthusiast replication (daily life, education-focused)
- Tech-savvy retail users can replicate a simplified version with sector ETFs and public data to learn DRL vs. MVO differences (paper is not investment advice).
- Tools/workflows: Public data, open-source libraries, educational notebooks; paper-trading before any real capital.
- Assumptions/dependencies: High risk tolerance and awareness of backtest biases; strict adherence to long-only, non-levered constraints; tax and fee considerations.
Long-Term Applications
These applications require further research, scaling, regulatory alignment, or significant productization and infrastructure.
- Transaction-cost and slippage-aware RL allocators (finance, trading)
- Integrate explicit cost models into rewards (penalties for turnover and market impact) and/or constraints; optimize net returns rather than gross.
- Tools/products: Cost-aware PPO variants, execution simulators, liquidity filters; broker integration with feedback loops.
- Dependencies: Accurate and regime-sensitive cost models; real-time liquidity estimation; robust model risk management.
- Multi-asset, global allocation across equities, bonds, commodities, and FX (finance, asset management)
- Extend the framework to cross-asset allocation with richer feature sets (macro factors, yield curves, term structure, cross-asset vol regimes).
- Tools/products: Multi-asset DRL platform, feature store for macro and alt data, composite risk constraints (CVaR/drawdown caps).
- Dependencies: Data coverage and quality across assets; more complex action spaces (including shorting/leverage under strict constraints); enhanced compliance requirements.
- Regime-switching ensemble allocators (finance)
- Deploy mixture-of-experts that explicitly switch between low-volatility and high-volatility agents (as proposed in future work), or blend policies conditioned on regime probabilities.
- Tools/products: Regime classifier calibrated to vol/VIX/market stress indicators; policy orchestration layer; ensemble stability monitoring.
- Dependencies: Robust regime identification; guardrails during regime changes; complexity in monitoring and explanation.
- Explainable and auditable DRL for regulated portfolios (policy, compliance, finance)
- Develop explainability modules and audit trails (feature importance proxies, behavior summaries) to meet model risk governance and regulator expectations.
- Tools/products: Post-hoc explainers, standardized reports (reason codes for major reallocations), immutable logs.
- Dependencies: Agreement on explainability standards; acceptable proxies for black-box models; periodic independent validation.
- DRL-powered ETFs/mutual funds and model portfolios (finance)
- Launch products that systematically apply DRL allocation within stringent mandates (e.g., turnover caps, sector exposure limits, liquidity rules), targeting consistent Sharpe and drawdown control.
- Tools/products: Fund operations, real-time index replication, NAV calculation, market-making support.
- Dependencies: Multi-year live track record, seed capital, regulator approval, scalable infrastructure, robust contingency processes.
- Pension and insurance risk overlays (finance, institutional)
- Use DRL allocators as overlays to reduce drawdowns and improve risk-adjusted returns on long-horizon portfolios, with liability-aware constraints.
- Tools/products: Liability-aware reward shaping, risk budgeting modules; governance with board-level oversight.
- Dependencies: Alignment with ALM frameworks; strict stress-testing; conservative turnover and liquidity management.
- Enterprise SaaS for RL portfolio allocation (software)
- Offer a managed platform providing training pipelines, backtesting, data connectors, monitoring (drift, risk metrics), and deployment workflows.
- Tools/products: Cloud MLOps, vectorized simulation engines, reproducibility tooling, API connectors to brokers and custodians.
- Dependencies: Security and privacy compliance; SLAs for data ingestion; multi-tenant isolation and auditability.
- Standardized benchmarking protocols and guidelines (policy, academia, industry)
- Create community standards for comparing DRL vs. classical methods with aligned objectives (e.g., Sharpe), realistic cost models, and robust validation (burn periods, walk-forward).
- Tools/products: Open benchmark datasets and leaderboards; common evaluation libraries.
- Dependencies: Cross-industry and academic collaboration; governance by independent bodies; periodic updates to reflect market changes.
- Consumer-grade robo-advisors with dynamic sector allocation (daily life, finance)
- Long-term deployment to retail users with strong suitability and education layers, conservative guardrails, and tax-aware rebalancing.
- Tools/products: Mobile app, suitability engine, tax-lot optimization, educational explainers.
- Dependencies: Regulatory approval, robust support infrastructure, clear communication of risks and model limitations; low-fee execution to preserve edge.
Cross-cutting Assumptions and Dependencies
- Market realism: The paper’s backtests exclude transaction costs, slippage, market impact, and taxes; live deployment must model these explicitly.
- Constraints: Current setup is long-only, non-levered, whole-share, daily EOD data; expanding beyond these requires additional risk controls and infrastructure.
- Data and features: Reliance on accurate, timely price/volatility feeds (including VIX); standardized scaling to avoid leakage; broader assets need richer feature engineering.
- Model governance: Regular retraining with sliding windows, burn-year validation, seed ensembles for stability; drift detection, stress testing, and fallback strategies (e.g., MVO).
- Compliance: Suitability, explainability, audit trails, and oversight are necessary for institutional and retail deployments.
- Compute and engineering: Multi-million timestep training demands reliable compute and robust MLOps; reproducibility and monitoring are essential for productionization.
Glossary
- A2C/A3C: Asynchronous Advantage Actor-Critic algorithms used for on-policy reinforcement learning. "Some examples of popular policy optimization methods are A2C/A3C~\cite{mnih2016asynchronous} and PPO~\cite{schulman2017proximal}."
- Annealed learning rate: A learning rate schedule that gradually decreases during training to improve stability. "We set up the learning rate as a decaying function of the current progress remaining, starting from $3e-4$, annealed to a final value of $1e-5$."
- Attention networks: Neural architectures that weight input components to focus on relevant information. "Other proposed features use attention networks or graph structures~\cite{Wang_Huang_Tu_Zhang_Xu_2021,wang2019alphastock} to perform cross-asset interrelationship feature extraction."
- Autoencoders: Neural networks trained to compress and reconstruct data, often used for feature learning. "Recent methods focus on learning deep features and state representations, for example, through the use of embedding features derived from deep neural networks such as autoencoders and LSTM models."
- Backtest: A simulation of a strategy using historical data to assess performance before live deployment. "We evaluate the performance of both techniques through $10$ independent backtests ."
- Bias-variance trade-off: The balance between error from bias and variance affecting generalization. "We set up the learning rate as a decaying function of the current progress remaining, starting from $3e-4$, annealed to a final value of $1e-5$. We used a of , set the number of epochs when optimizing the surrogate loss to , picked the discount factor , set the bias-variance trade-off factor for Generalized Advantage Estimator and ."
- Calmar ratio: A performance metric defined as annualized return divided by maximum drawdown. "Calmar ratio & 2.3133 & 1.1608"
- Convex optimization: Optimization problems where the objective and feasible set are convex, enabling efficient solutions. "A typical procedure is to solve it as a convex optimization problem and generate an efficient frontier of portfolios such that no portfolio can be improved without sacrificing some measure of performance (e.g., returns, risk)."
- Differential Sharpe Ratio: A timestep-level measure for optimizing risk-adjusted returns suitable for online learning. "To combat this, we use the Differential Sharpe Ratio ~\cite{moody1998performance} which represents the risk-adjusted returns at each timestep and has been found to yield more consistent returns than maximizing profit~\cite{moody2001learning, dempster2006automated}."
- Discount factor: The parameter in reinforcement learning that down-weights future rewards relative to immediate rewards. " is a discount factor between that represents the difference in importance between present and future rewards"
- Efficient frontier: The set of optimal portfolios offering the highest expected return for a given risk level. "A typical procedure is to solve it as a convex optimization problem and generate an efficient frontier of portfolios such that no portfolio can be improved without sacrificing some measure of performance (e.g., returns, risk)."
- Eigenvalues: Values indicating the magnitude of variance along eigenvectors; used to ensure covariance matrices are valid. "Additionally, we enforce non-singular and positive-semi-definite conditions on the covariance matrices, setting negative eigenvalues to $0$, and then rebuilding the non-compliant matrices."
- Endogenous information: Features derived from the assets themselves (e.g., technical indicators) used for modeling. "Other work explores frameworks that inject information in the RL agent's state by incorporating asset endogenous information such as technical indicators~\cite{liu2020finrl, sun2021deepscalper,du2020stock}"
- Exogenous information: External signals (e.g., news) used to augment asset modeling. "as well as exogenous information such as information extracted from news data~\cite{ye2020reinforcement, lima2021intelligent}."
- Generalized Advantage Estimator (GAE): A technique to reduce variance in policy gradient methods when estimating advantages. "We set up the learning rate as a decaying function of the current progress remaining, starting from $3e-4$, annealed to a final value of $1e-5$. We used a of , set the number of epochs when optimizing the surrogate loss to , picked the discount factor , set the bias-variance trade-off factor for Generalized Advantage Estimator and ."
- Graph structures: Graph-based models capturing relationships among assets for feature extraction. "Other proposed features use attention networks or graph structures~\cite{Wang_Huang_Tu_Zhang_Xu_2021,wang2019alphastock} to perform cross-asset interrelationship feature extraction."
- Kurtosis: A measure of the “tailedness” of a distribution compared to the normal distribution. "Kurtosis & 2.7054 & 2.6801"
- Ledoit-Wolf Shrinkage: A covariance estimation technique that reduces estimation error by shrinking towards a structured target. "However, we do not directly use the sample covariance, as this has been shown to be subject to estimation error that is incompatible with MVO. To tackle this, we make use of the Ledoit-Wolf Shrinkage operator~\cite{ledoit2004honey}."
- Leverage: Using borrowed capital to increase the size of a position; results in weights exceeding 1. "w_i > 1 indicates a leveraged position."
- Long-only: A portfolio constraint where positions can only be positive (no short selling). "However, for our case, we restrict actions to non-leveraged long-only positions."
- LSTM: Long Short-Term Memory neural networks, used to model sequences and time series. "such as autoencoders and LSTM models."
- Markov Decision Process (MDP): A mathematical framework for modeling decision-making with states, actions, transitions, and rewards. "An environment is typically formalized by means of a Markov Decision Process (MDP)."
- Market replay: Simulating an environment by stepping through historical market data to train or test strategies. "The environment serves as a wrapper for the market, sliding over historical data in an approach called market replay."
- Maximum drawdown: The largest peak-to-trough decline in portfolio value over a period. "Backtest results demonstrate strong performance of the DRL agent across many metrics, including Sharpe ratio, maximum drawdowns, and absolute returns."
- Mean-Variance Optimization (MVO): A portfolio selection method balancing expected return against variance (risk). "Mean-Variance Optimization (MVO) is the mathematical process of allocating capital across a portfolio of assets (optimizing portfolio weights) to achieve a desired investment goal"
- Modern Portfolio Theory (MPT): The foundational theory for quantifying trade-offs between risk and return via diversification. "Markowitz introduced the modern portfolio theory (MPT)~\cite{markowitz}, a framework that allows an investor to mathematically balance risk tolerance and return expectations to obtain efficiently diversified portfolios."
- Multiprocessing: Running computations concurrently across processes to speed up training. "to collect experience rollouts through multiprocessing across independent instances of our environment."
- Non-stationarity: Statistical properties of a time series changing over time. "Additionally, financial time series exhibit non-stationarity~\cite{cont2001empirical}; this can be tackled by retraining or fine-tuning models by utilizing the most recently available data."
- Omega ratio: A performance metric measuring the ratio of gains to losses beyond a threshold. "Omega ratio & 1.2360 & 1.1315"
- On-policy: Reinforcement learning setting where the policy is improved using data generated by the current policy. "This optimization is almost always performed on-policy since the experiences are collected using the latest learned policy, and then using that experience to improve the policy."
- Policy Gradient: A class of RL methods that directly optimize the policy parameters via gradient ascent. "Model-free algorithms seek to learn the outcomes of their actions through collecting experience via algorithms such as Policy Gradient, Q-Learning, etc."
- Portfolio turnover: The degree of trading activity, often approximated by changes in allocation weights. "We compare the performance of the DRL strategy against MVO through a series of systematic backtests, and observe improved performance along many performance metrics, including risk-adjusted returns, max drawdown, and portfolio turnover."
- Positive semi-definite: A property of matrices (e.g., covariances) indicating non-negative quadratic forms; required for valid risk models. "Additionally, we enforce non-singular and positive-semi-definite conditions on the covariance matrices, setting negative eigenvalues to $0$, and then rebuilding the non-compliant matrices."
- Proximal Policy Optimization (PPO): A robust on-policy RL algorithm using clipped objective functions for stable updates. "Some examples of popular policy optimization methods are A2C/A3C~\cite{mnih2016asynchronous} and PPO~\cite{schulman2017proximal}. For our experiments we use PPO."
- Pyfolio: A Python library for analyzing financial portfolio performance. "These are computed with the aid of the Python library Pyfolio."
- PyPortfolioOpt: A Python library for portfolio optimization, including mean-variance methods. "We use the implementation in PyPortfolioOpt~\cite{martin2021pyportfolioopt} to aid us with this process."
- Rebalancing: Adjusting portfolio positions to target weights or constraints at given intervals. "For the purposes of this study, we assume that there are no transaction costs in the environment, and we allow for immediate rebalancing of the portfolio."
- Regime switching: Modeling approaches that adapt strategies based on different market states (e.g., high vs. low volatility). "Another area of exploration is training a regime switching model which will balance its funds amongst two agents depending on market volatility (low vs high)."
- Reinforcement Learning (RL): Learning by interacting with an environment to maximize cumulative rewards. "Reinforcement Learning (RL) is a sub-field of machine learning that refers to a class of techniques that involve learning by optimizing long-term reward sequences obtained by interactions with an environment~\cite{sutton2018reinforcement}."
- Risk-adjusted returns: Returns scaled by risk to assess performance quality (e.g., via Sharpe). "The agents optimize for risk-adjusted returns, similar to the traditional MVO methods."
- Risk-free rate: The theoretical return on an investment with zero risk, used in Sharpe ratio calculations. "where is a constant risk-free rate (e.g., US Treasuries, approximated by 0.0\% in recent history)."
- Risk tolerance: The investor’s acceptable level of uncertainty or loss. "Markowitz introduced the modern portfolio theory (MPT)~\cite{markowitz}, a framework that allows an investor to mathematically balance risk tolerance and return expectations to obtain efficiently diversified portfolios."
- Rolling window standard deviation: A volatility measure computed over a sliding time window. "The first one, , is the $20$-day rolling window standard deviation of the daily S{paper_content}P 500 index returns"
- Sharpe Ratio: Return per unit of risk, defined as excess return divided by standard deviation. "Another common objective is the Sharpe Ratio~\cite{sharpe1998sharpe, chen2011all}, which measures the return per unit risk."
- Shorting: Taking a negative position in an asset by selling borrowed shares to profit from price declines. "In extensions of this framework, would allow for shorting an asset"
- Skew: A measure of asymmetry in a return distribution. "Skew & -0.4063 & -0.3328"
- Slippage: The difference between expected and actual execution price due to market frictions. "This has implications for live-deployment, where transaction costs and slippage affect P{paper_content}L."
- Softmax function: A normalization function that converts raw scores to a probability distribution summing to one. "These constraints can be enforced by applying the softmax function to an agent's continuous actions."
- Sortino ratio: A risk-adjusted performance measure using downside deviation instead of total volatility. "Sortino ratio & 1.7208 & 1.0060"
- StableBaselines3: A library of RL algorithms and tools for Python. "We use the StableBaselines3~\cite{stable-baselines3} implementation of PPO, and report the hyperparameters used in Table~\ref{table:hyperparameters}."
- Stochastic control: Methods for decision-making under uncertainty using probabilistic models. "Given its success in stochastic control problems, RL extends nicely to the problem of portfolio optimization."
- Surrogate loss: An objective used in PPO to approximate and stabilize policy updates. "We used a of , set the number of epochs when optimizing the surrogate loss to "
- Tail ratio: A performance metric comparing the magnitudes of gains to losses in the tails of the return distribution. "Tail ratio & 1.0423 & 0.9448"
- Transaction costs: Fees and frictions (e.g., commissions, spreads) incurred when trading. "For the purposes of this study, we assume that there are no transaction costs in the environment"
- Value at Risk: A measure of potential loss at a given confidence level over a specified period. "Daily value at risk & -0.0152 & -0.0181"
- Vectorized SubProcVecEnv: A StableBaselines3 wrapper that runs multiple environment instances in parallel subprocesses. "Additionally, we make use of the Vectorized SubProcVecEnv environment wrappers provided by StableBaselines3 to collect experience rollouts through multiprocessing across independent instances of our environment."
- VIX: The CBOE Volatility Index, a market expectation of near-term volatility. "We use the first and third metrics in the observation matrix, along with the value of the VIX index."
- Volatility: A statistical measure of dispersion of returns, often proxied by standard deviation. "Risk is usually measured by the volatility of a portfolio (or asset), which is the variance of its rate of return."
Collections
Sign up for free to add this paper to one or more collections.