- The paper presents Query-as-Anchor, a framework that refactors static user models into dynamic, query-conditioned representations using large language models.
- It integrates a dual-tower architecture with shared LLM weights and joint contrastive–generative training to align multi-modal behavior logs with semantic queries.
- Experimental results across 10 industrial scenarios demonstrate significant performance improvements in AUC and KS, underscoring scalability and practical impact.
Query-as-Anchor: Scenario-Adaptive User Representation via LLM
Introduction and Motivation
Robust and adaptive user representation learning is foundational to modern large-scale applications in recommendation, risk modeling, and digital marketing. Prevailing paradigms encode heterogeneous user behaviors into universal, static embeddings, generally via contrastive learning or sequential PLMs. However, static representations pose significant limitations: they are inflexible to scenario-specific objectives, ill-equipped to bridge the modality and semantic gaps across behavioral logs and language-centric pre-training, and inefficient at downstream adaptation. The "Query as Anchor" framework directly addresses these industrial bottlenecks by refactoring user modeling into a dynamic, query-conditioned process centered around LLMs and industrial-scale pretraining.
Methodological Contributions
UserU Pretraining Dataset Construction
The authors introduce the UserU pretraining dataset, which aligns multi-modal behavioral traces with meaningful user understanding. This dataset is composed of (1) a behavior-based interaction dataset, aggregating user behaviors over three months and targeting future behavior prediction, and (2) a synthetic LLM-generated query-answer dataset, where user profiles are coupled with diverse, semantically rich queries and answers via self-reflective LLM prompting. The second dataset ensures decoupling between pretraining and downstream tasks, injecting semantic priors for better generalization.
Hierarchical Coarse-to-Fine User Encoder
The input pipeline projects each user's recent multi-modal events (bills, app usage, navigation paths, search, tabular features) through modality-specific encoders, synthesizing event-, modality-, and user-level representations. This structured embedding, concatenated and fed to the LLM, enables both granular (per-event) and holistic (per-user) evidence aggregation, supporting downstream adaptation.
Query-as-Anchor Dual-Tower Architecture
The core innovation is the Query-as-Anchor mechanism, operationalized via a dual-tower architecture. The Anchor Tower extracts user embeddings by appending a scenario-specific natural language query to the sequence, prompting the LLM to attend selectively to relevant aspects of the user profile. A Semantic Tower encodes the query answer for contrastive alignment. Notably, both towers share LLM weights, ensuring a unified latent geometry for user behaviors and semantic targets.
Joint Contrastive–Generative Optimization
The model is jointly trained via (i) a query-conditioned InfoNCE contrastive loss, enforcing that query-anchored user embeddings align with target answers, and (ii) an autoregressive next-token prediction task, grounding the embeddings in fine-grained generative semantics. Margin-based filtering eliminates false negative samples by measuring embedding similarity, enhancing robustness against noise and mode collapse.
Cluster-Based Soft Prompt Tuning
For downstream scenario adaptation, the framework deploys cluster-based soft prompt tuning. Learnable prompt tokens modulate the scenario-specific geometry in the latent embedding space, guided by prototypical contrastive learning to maximize intra-class compactness and inter-class separation. This approach enables low-cost and interpretable specialization without retraining the full model, preserving base representational universality.
KV-Cache–Accelerated Multi-Scenario Inference
To meet industrial inference demands, the framework exploits LLM KV-cache mechanisms. The slow-encoded hierarchical user prefix is cached and shared, while lightweight query suffixes are recomputed per scenario with minimal latency, amortizing computational cost across diverse tasks.
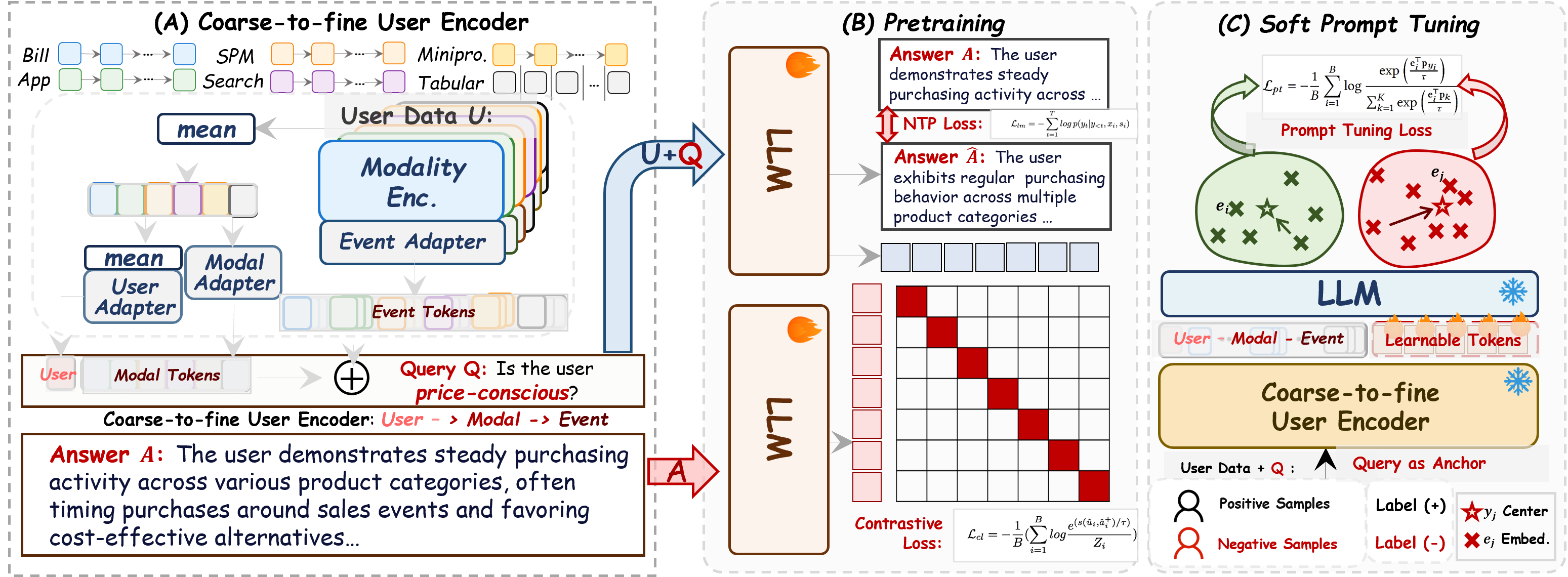
Figure 1: Overview of the Query-as-Anchor framework integrating coarse-to-fine encoders with a dual-tower LLM structure and query-based dynamic re-anchoring.
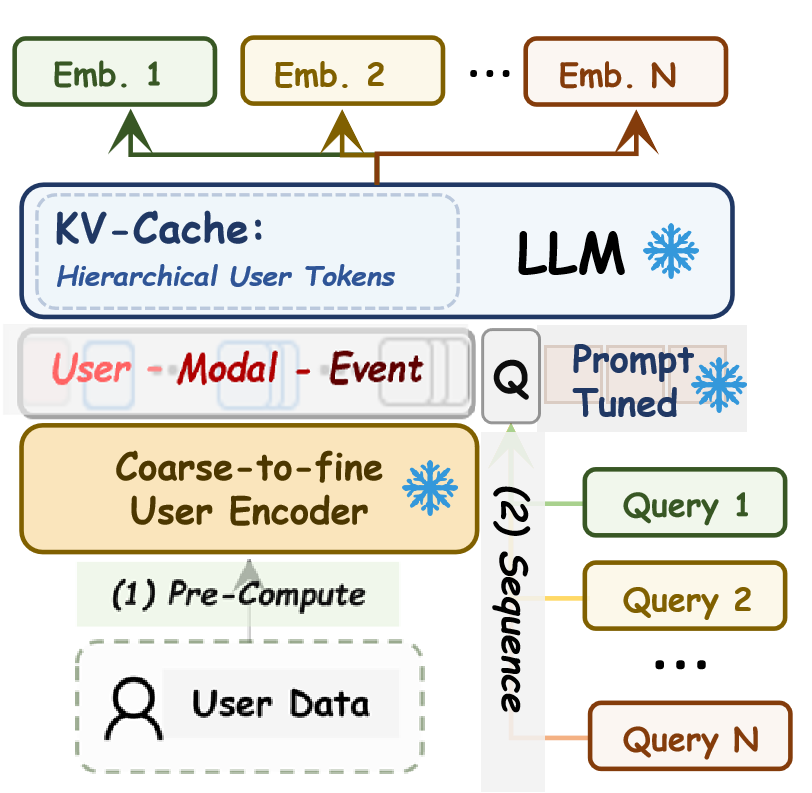
Figure 2: KV-Cache optimized inference: precomputed user representations enable fast, low-latency adaptation to multiple downstream queries.
Experimental Evaluation
Benchmarks and Baselines
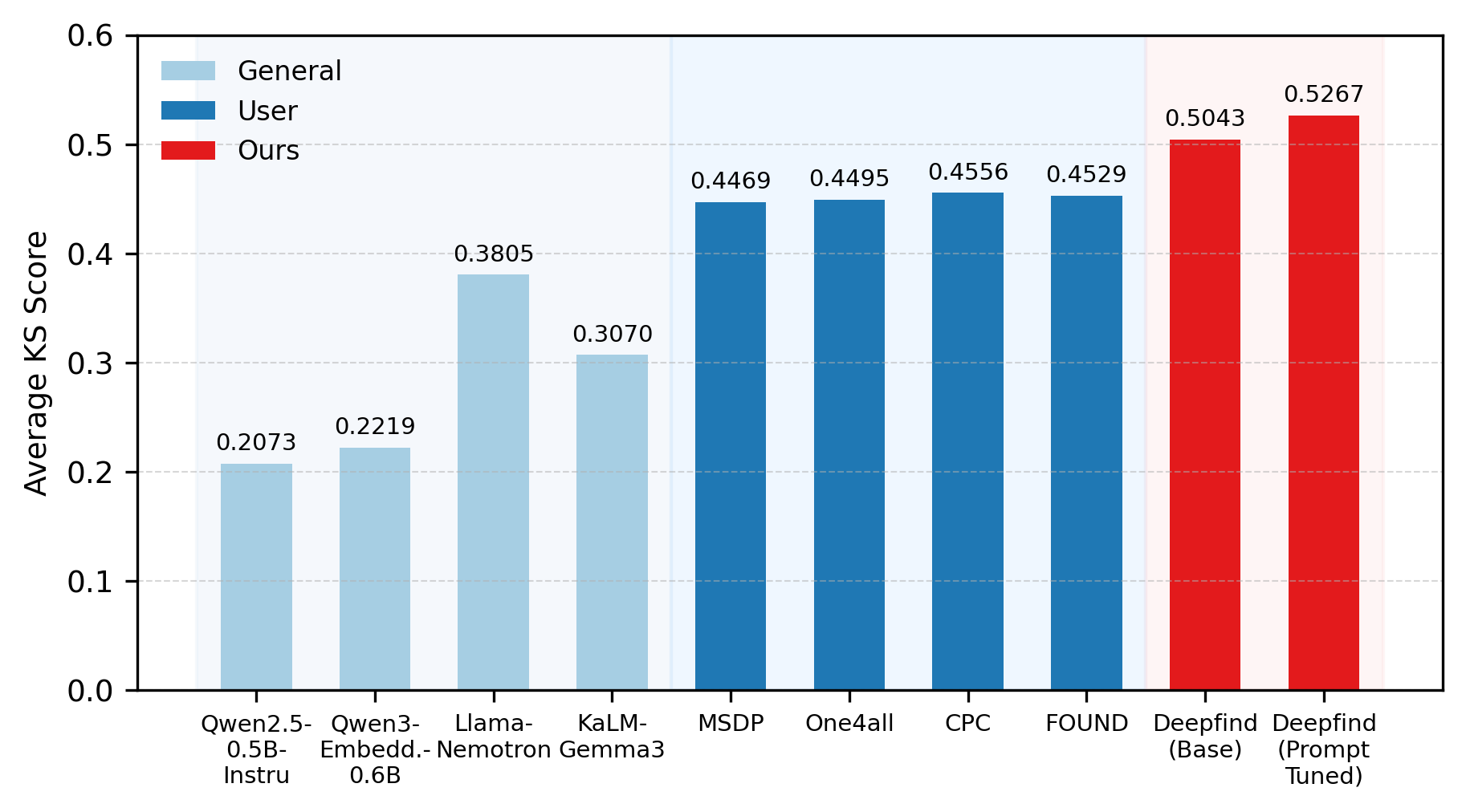
Evaluation encompasses 10 real-world Alipay binary classification scenarios (across engagement, risk, and marketing tasks) and large-scale online A/B tests. Baselines span general-purpose LLM embeddings (Qwen2.5-0.5B-Instruct, KaLM-Embedding, Llama-Embed-Nemotron-8B) and specialized user models (MSDP, One4all, FOUND).
Main Numerical Results
Substantial performance lifts are documented:
Scaling Analyses
- Performance scales strongly with pretraining data size (AUC: 0.8029→0.8105 as data size increases); model scaling to larger LLMs yields no consistent benefit, exhibiting diminishing gradients and potential over-parameterization for the discriminative alignment task.
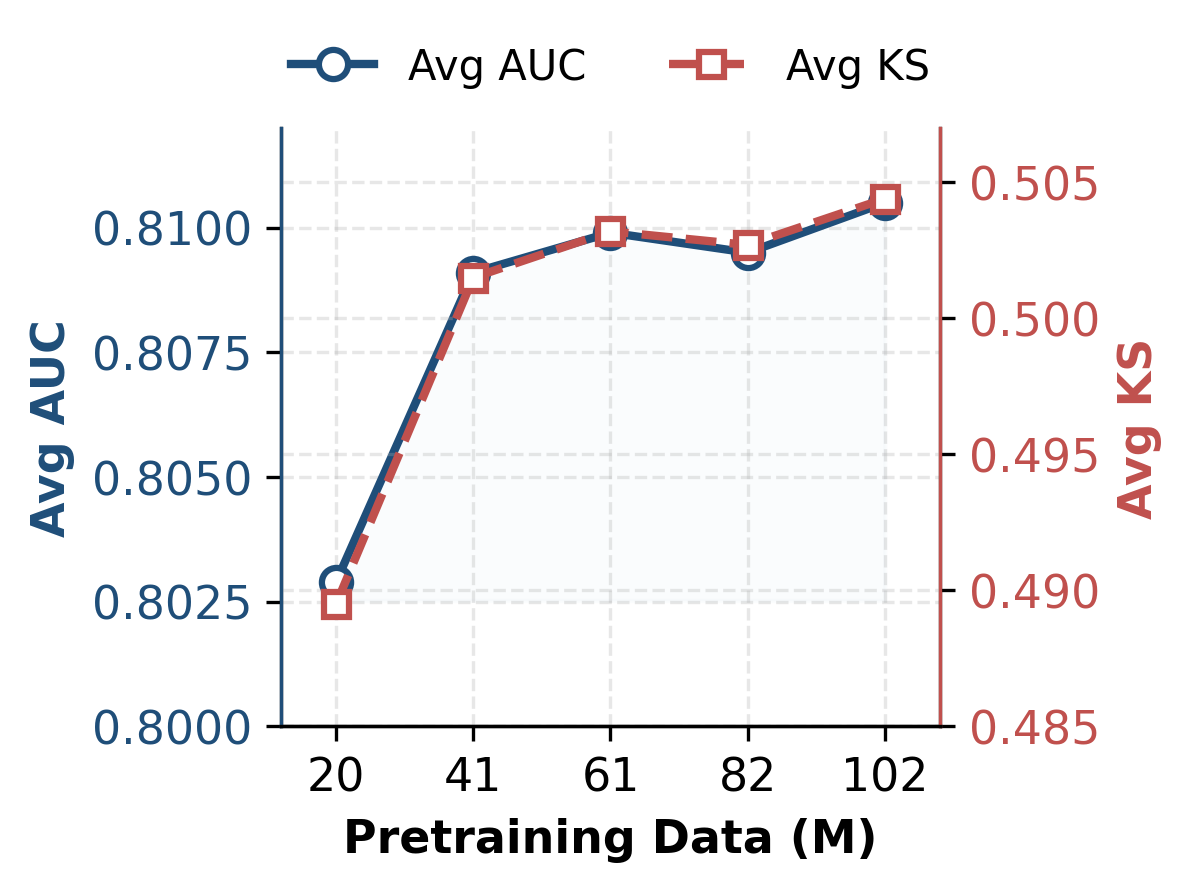
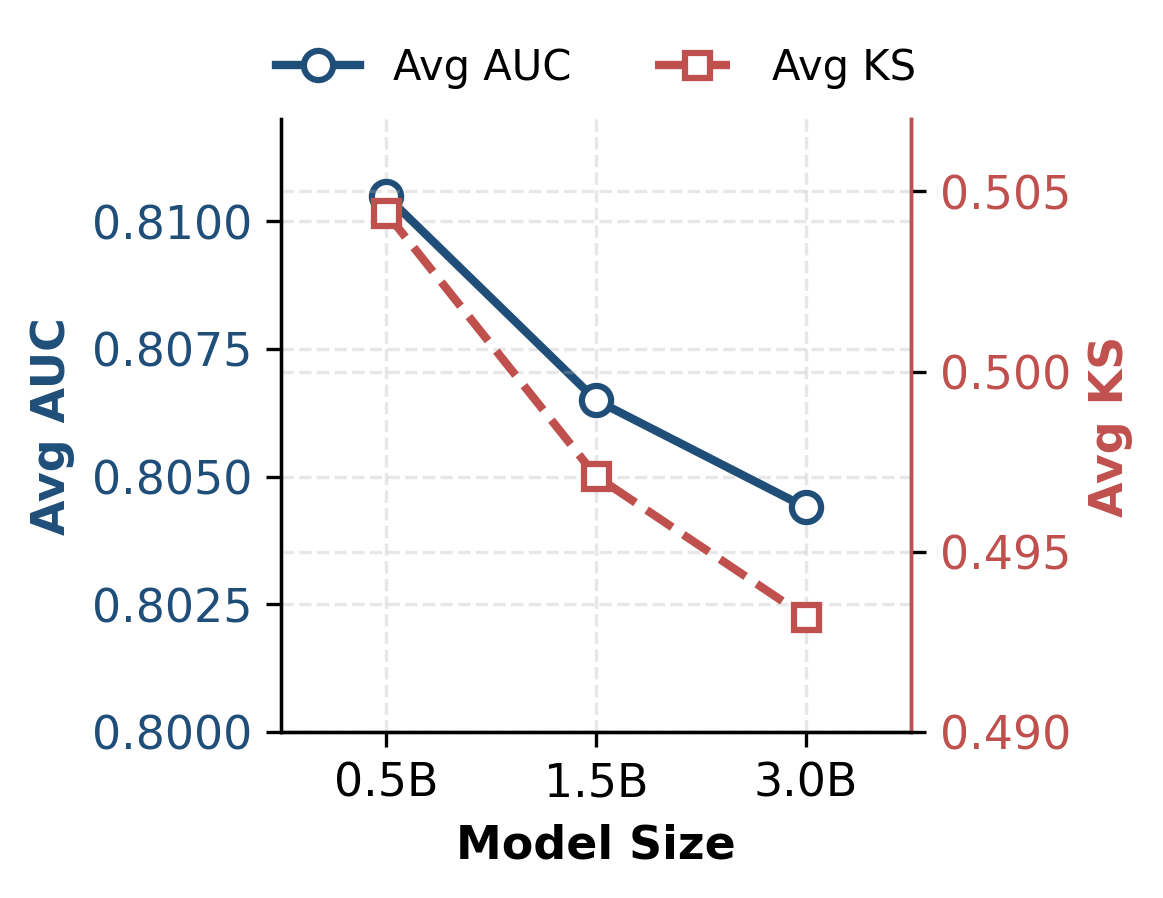
Figure 4: Pretraining Data Scale — increasing pretraining data yields monotonic performance improvements.
- Prompt tuning saturates quickly: 6 tokens and 500 steps suffice for optimal adaptation, representing an efficiency-friendly setting for industrial-scale deployment.
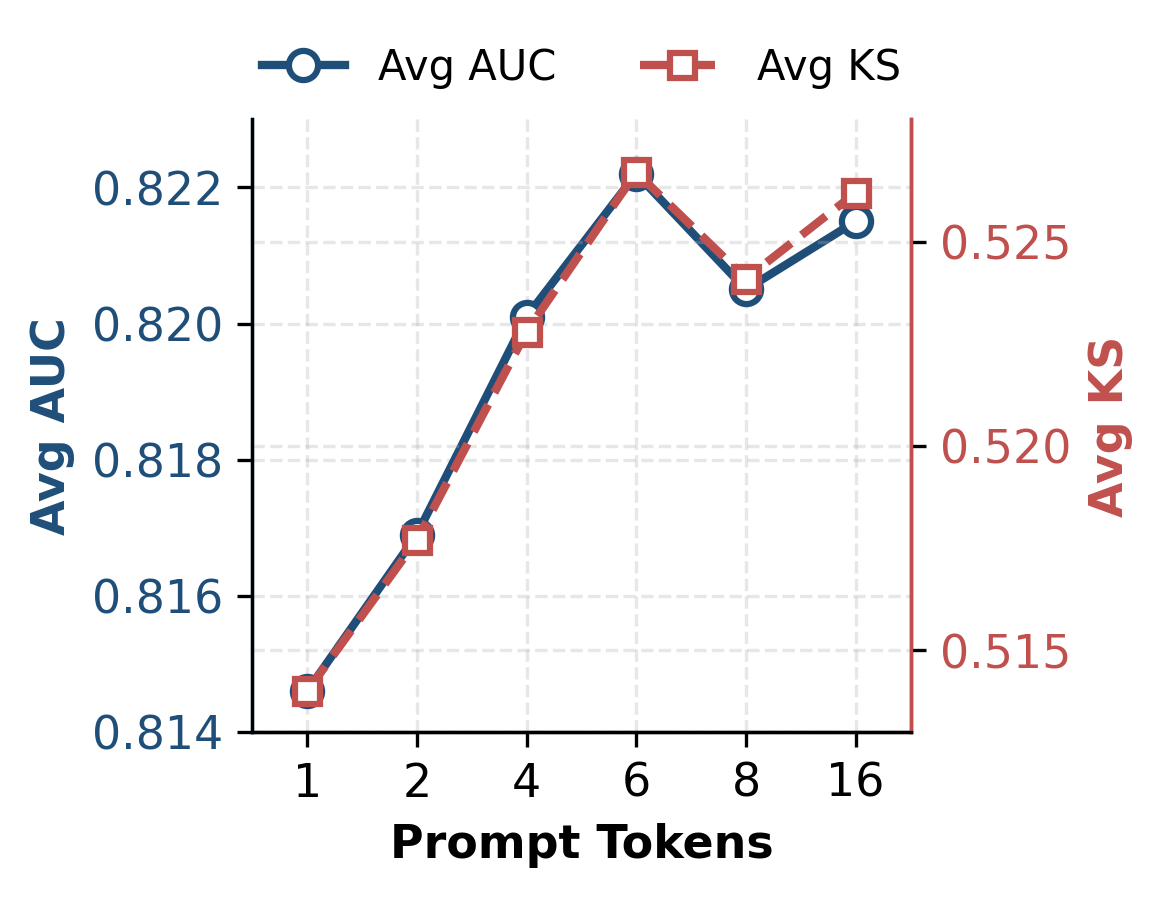
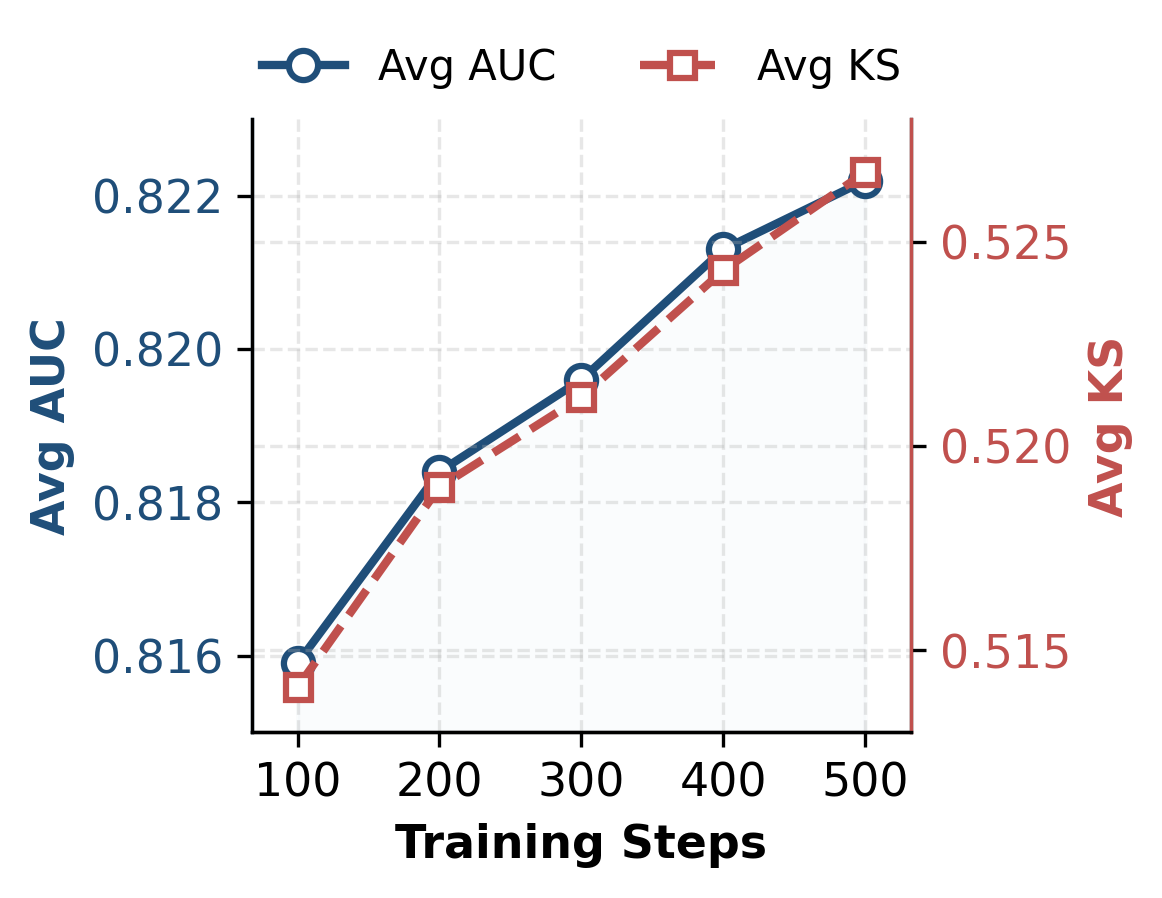
Figure 5: Prompt Tokens Scale — incremental gains saturate beyond 6 tokens, suggesting minimal setup suffices for scenario adaptation.
Interpretability and Adaptability
Analysis of modal attention shifts after prompt tuning illustrates that Q-Anchor not only adapts numerically but also structurally re-anchors attention according to task relevance (e.g., increased Bill modality weight in takeout interest; heightened SPM attention in Ant Forest scenarios).
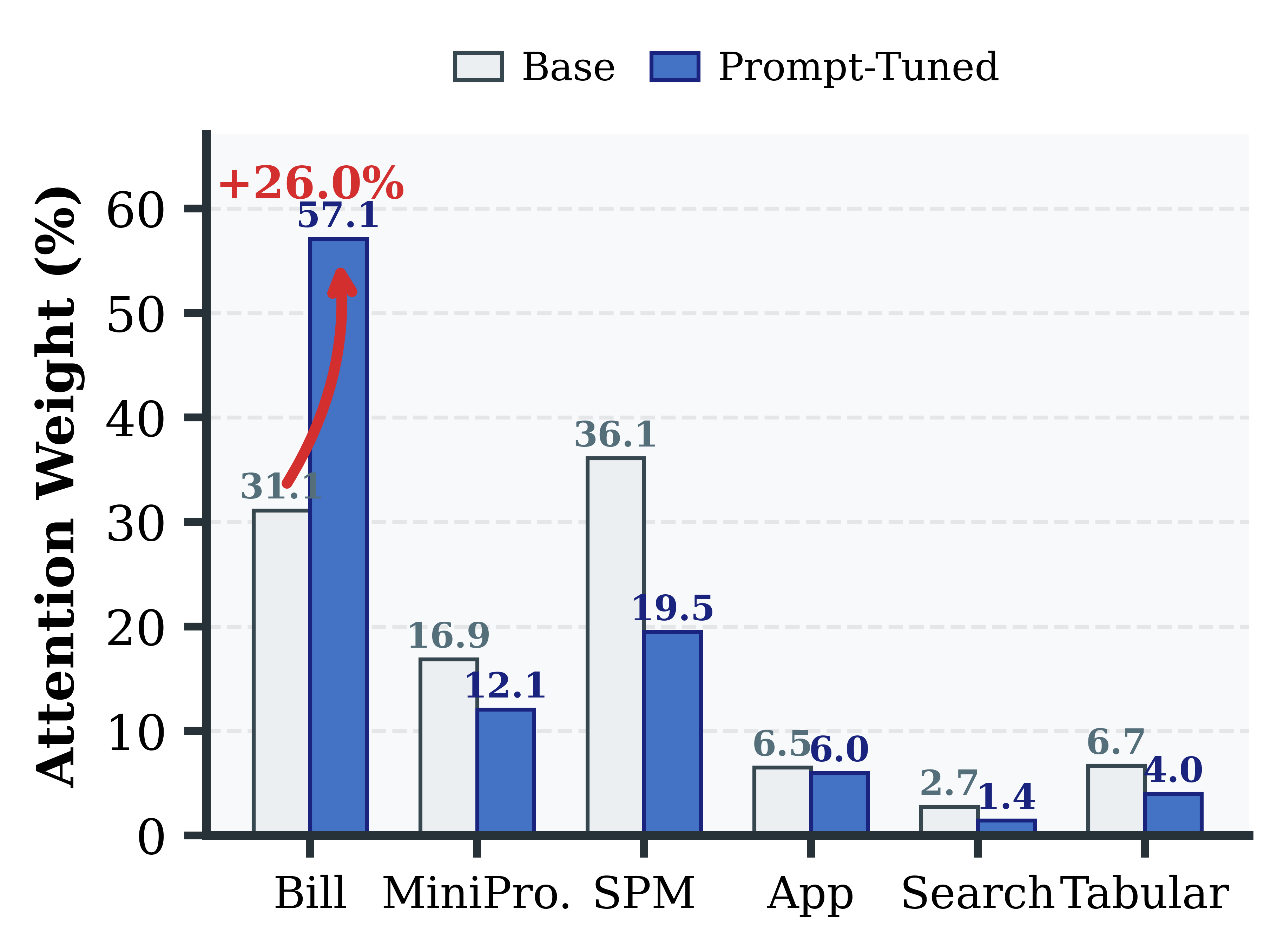
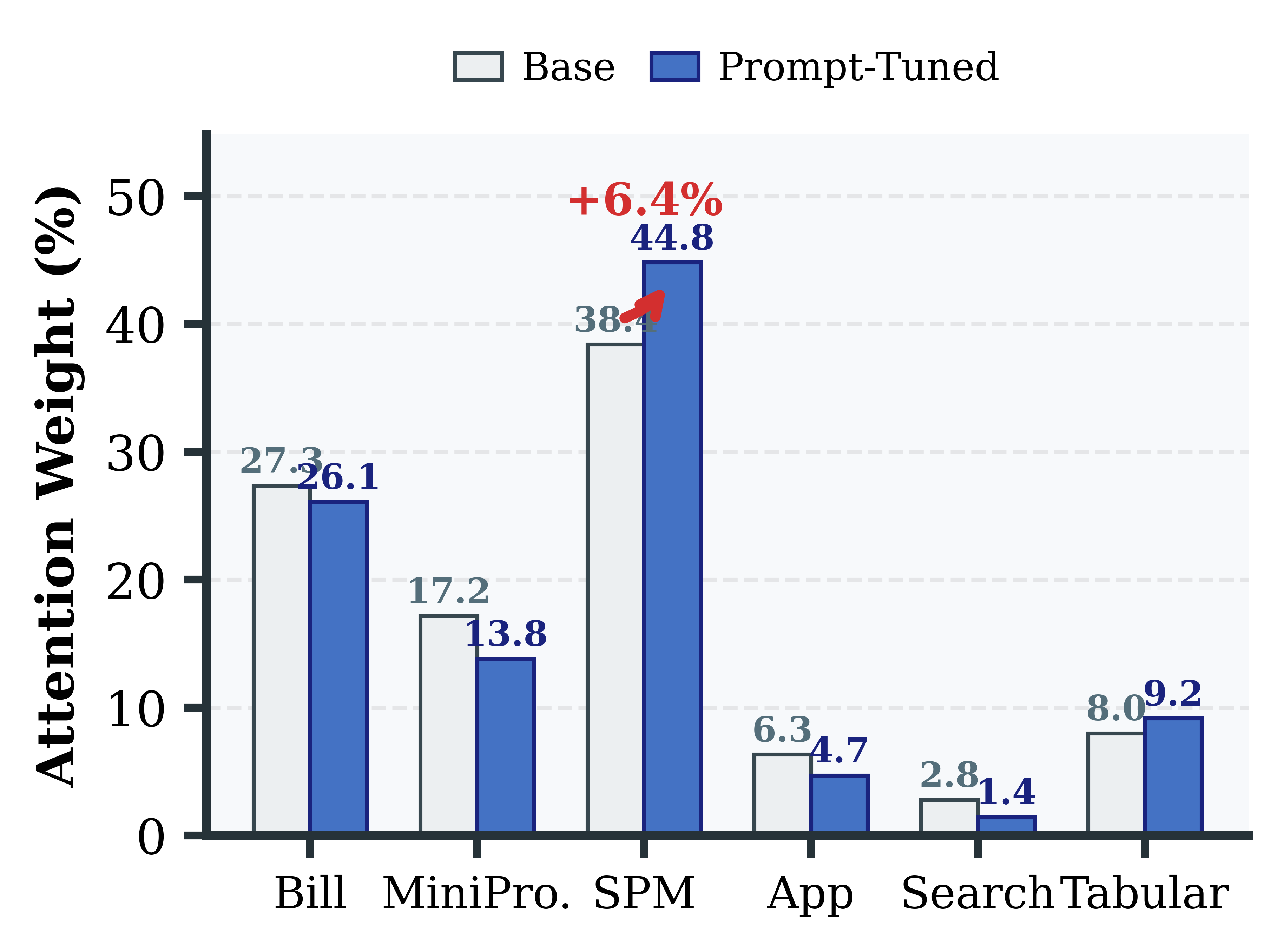
Figure 6: Attention shift after prompt tuning highlights interpretable, scenario-consistent evidence re-weighting.
t-SNE and PCA visualizations further validate that prompt-tuned embeddings form clear, scenario-aligned clusters, confirming that soft-prompting shapes context-sensitive geometries without catastrophic forgetting.
Industrial-Scale Online Deployment
Deployment at Alipay scale demonstrates:
- Embedding-driven policies (e.g., cash reserve outreach timing, credit delinquency risk) improve critical business KPIs—drawdown rate (+12.5%), average balance (+5.3%), product visit rates, and KS risk separation (+1.96%).
- The KV-cache optimized architecture amortizes expensive user encoding across hundreds of millions of users and scenarios, maintaining strict latency SLAs while allowing scenario addition with only suffix computation overhead.
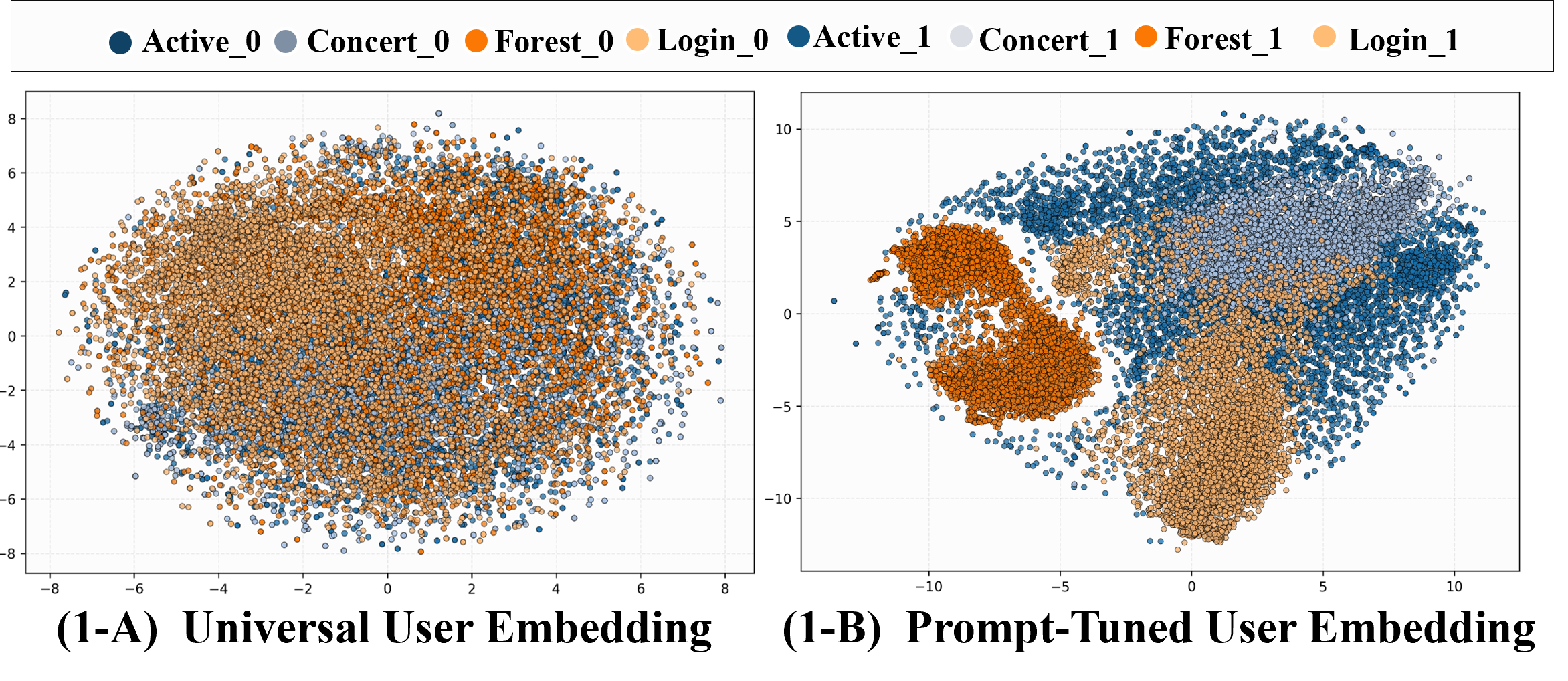
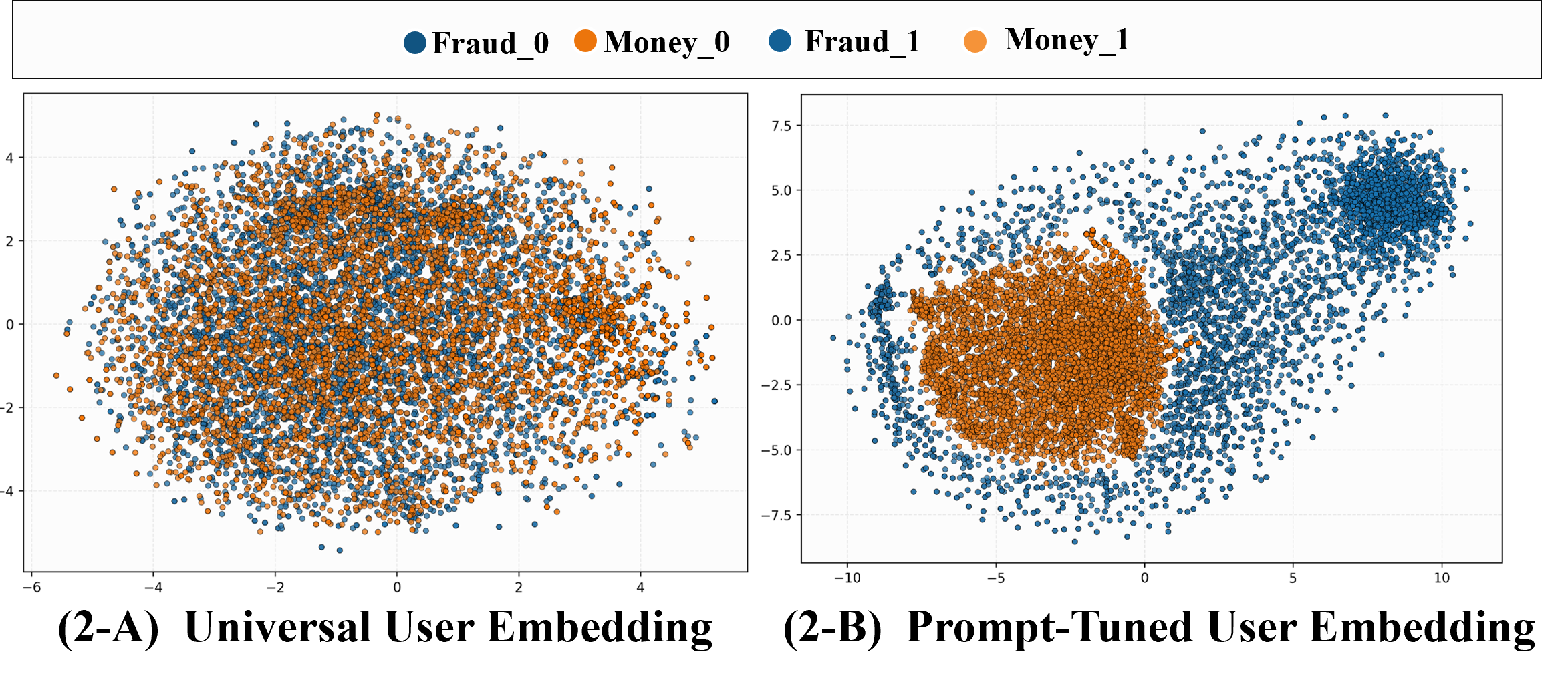
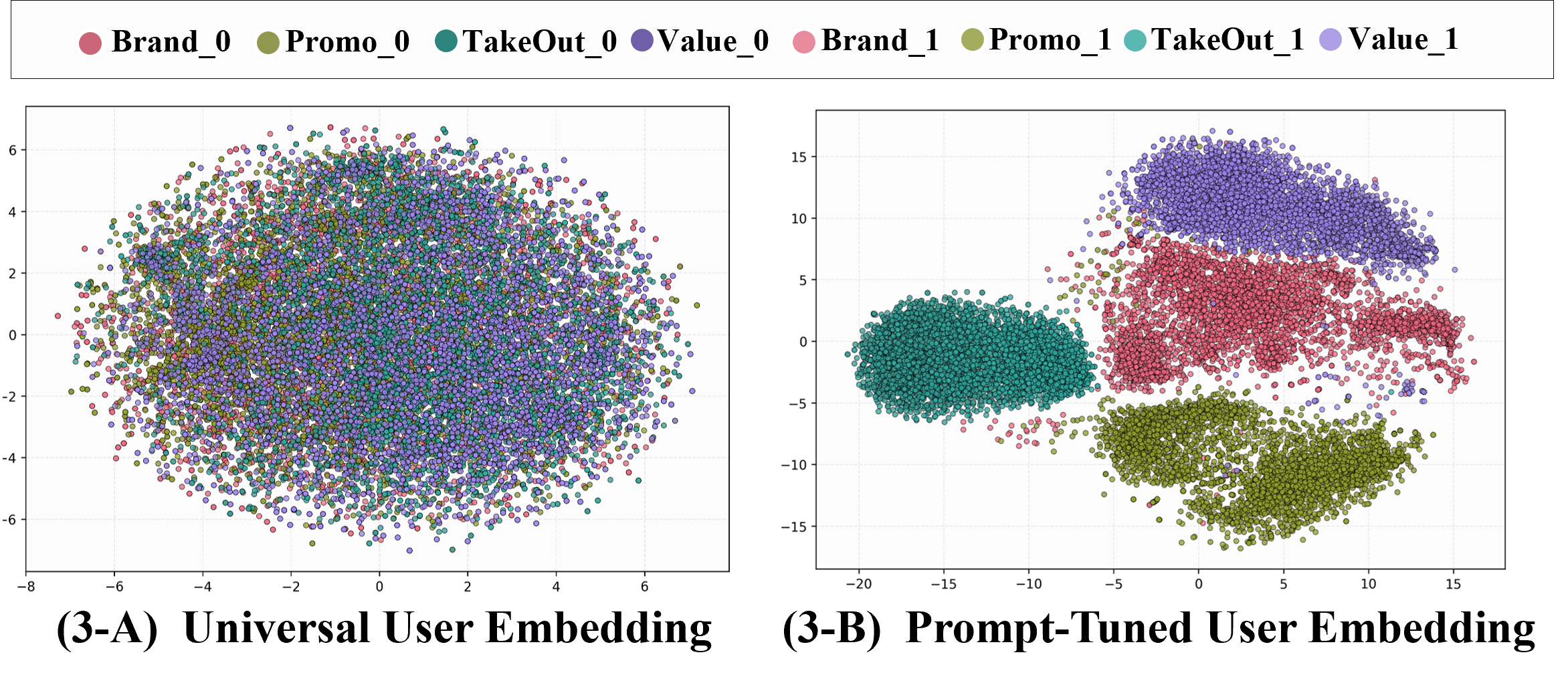
Figure 7: User Engagement — online A/B testing confirms embedding-based policies consistently improve high-impact business metrics.
Ablation Studies
Ablation studies show:
- Removing user/modal tokens slightly degrades AUC and KS, especially in modality-sensitive scenarios—structural inductive bias aids evidence aggregation.
- Contrastive alignment is critical: dropping it causes sharp performance regression, showing discriminative geometry is essential for query-based adaptation.
- Pretraining is mandatory: omitting it results in catastrophic loss of transferability, indicating that robust semantic priors are non-negotiable for downstream intent discovery.
Theoretical and Practical Implications
The Query-as-Anchor framework reframes user modeling in LLM systems as a dynamic, context-sensitive process. Key theoretical advancements include the formal decoupling of user evidence from scenario objectives and the demonstration that discriminative pretraining, rather than model scale, governs downstream transferability in multi-modal user embedding tasks.
Practically, the framework offers:
- Linear cost scaling with scenario number due to KV-caching
- Minimized adaptation overhead via soft prompt tuning
- Universal, interpretable, low-maintenance user representation for high-throughput, multi-scenario industrial deployments
Future Directions
Potential research extensions include:
- Addressing the scaling paradox wherein larger LLMs plateau/disappoint for discriminative embedding (suggesting investigation into optimization dynamics and curriculum strategies)
- Exploring richer query anchoring strategies (beyond natural language)
- Systematically evaluating generalization across domains with mismatched behavior distributions
Conclusion
Query-as-Anchor advances industrial user representation by integrating coarse-to-fine hierarchical encoding, dual-tower query-based alignment, and lightweight, interpretable scenario adaptation via prompt tuning. The empirical results unequivocally validate strong performance, sample efficiency, and industrial scalability over a comprehensive and challenging suite of tasks. These findings position the framework as a robust foundation for future scenario-adaptive representation systems in complex, real-world user modeling environments.