Inverse Depth Scaling From Most Layers Being Similar
Abstract: Neural scaling laws relate loss to model size in LLMs, yet depth and width may contribute to performance differently, requiring more detailed studies. Here, we quantify how depth affects loss via analysis of LLMs and toy residual networks. We find loss scales inversely proportional to depth in LLMs, probably due to functionally similar layers reducing error through ensemble averaging rather than compositional learning or discretizing smooth dynamics. This regime is inefficient yet robust and may arise from the architectural bias of residual networks and target functions incompatible with smooth dynamics. The findings suggest that improving LLM efficiency may require architectural innovations to encourage compositional use of depth.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tries to answer a simple question about big LLMs: when you stack more layers in the model (increase its “depth”), how much does that actually help? The authors find a clear pattern: the model’s error (called “loss”) tends to go down roughly like 1 divided by the number of layers. In other words, if you double the number of layers, the part of the error that depends on depth is cut about in half.
They also explain why this happens: many layers in the middle of an LLM act in very similar ways. Instead of each layer building a new level of understanding (like chapters in a book), lots of layers seem to do small, similar corrections. When you average the effects of many similar layers, random mistakes cancel out, which lowers error. This is called “ensemble averaging.”
What questions are the authors asking?
- How does adding more layers (depth) change an LLM’s performance?
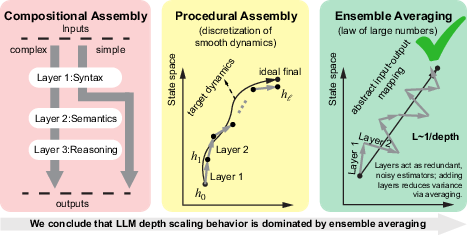
- Do LLMs use layers to build complex ideas step by step (“compositional assembly”), to follow a smooth path of tiny adjustments (“procedural assembly”), or mostly as a group of similar layers that average out errors (“ensemble averaging”)?
- Can we measure and model the exact way loss depends on depth, separate from width (how wide layers are) and data size?
How did they study it?
The authors use two approaches: real LLM measurements and controlled toy experiments.
- Real LLMs:
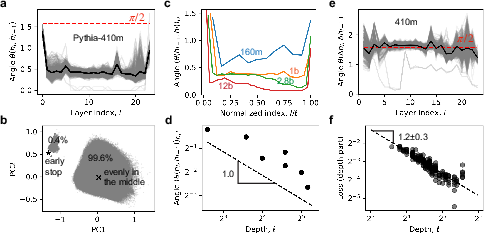
- They look inside LLMs (like Pythia models) and track how the “hidden state” (the internal representation of a token) changes from one layer to the next.
- They measure the “angle” between neighboring hidden states. Think of the hidden state like a pointing arrow; the angle shows how much direction the arrow changes from one layer to the next.
- They use simple statistics (like PCA, a way to find patterns) to see whether most tokens are updated evenly or stop changing early.
- They fit a “scaling law” that breaks loss into parts that depend on width, depth, and dataset size to see how each part contributes.
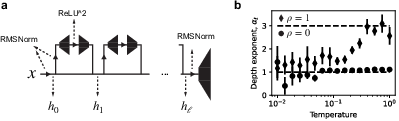
- Toy model experiments:
- They build a small “teacher–student” neural network with residual connections. Residual connections are like saying, “each layer adds a small correction to what’s already there.”
- The teacher (a deeper model) generates training data; the student (a shallower model) tries to learn from it.
- They test two worlds:
- Smooth world: all teacher layers use the same functions (weights are “tied”), like taking many tiny, consistent steps along a trail (“procedural assembly”).
- Noisy world: each teacher layer uses different functions (weights are independent), like many workers each giving a similar estimate with some random error (“ensemble averaging”).
- They also change the teacher’s “temperature.” Low temperature makes the teacher’s outputs very sharp—like strongly favoring one answer—which can make training slower.
By comparing the toy model’s behavior to real LLMs, they figure out which idea best matches reality.
What did they find, and why does it matter?
- Most middle layers make small, similar changes:
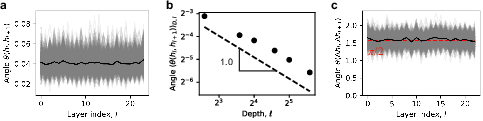
- In real LLMs, the first and last layers change the hidden state a lot (big angles), but the middle layers change it only a little (small angles), and fairly evenly across tokens.
- The average size of these middle-layer changes gets smaller as you add more layers, roughly like 1/depth. This suggests fine-grained adjustments rather than building new concepts at each layer.
- The updates aren’t “smooth” across layers:
- If the model were following a smooth path (procedural assembly), neighboring updates would look very similar. Instead, the authors find low correlation between updates in neighboring layers—more like independent small corrections.
- The loss scaling matches inverse depth:
- When they fit a scaling law that separates width, depth, and data size, they find:
- Width part scales like about 1/width (exponent ~1).
- Depth part scales like about 1/depth (exponent ~1).
- Data part matches known results (exponent ~0.3).
- This fit closely matches real data from the Chinchilla study.
- Toy models confirm the picture:
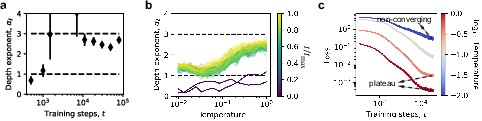
- In the “noisy world” (independent teacher layers), the student’s loss scales almost exactly like 1/depth, and hidden-state behavior looks just like real LLMs: small, uniform updates and low correlation between neighboring layers.
- In the “smooth world” (tied teacher layers), if training fully converges, you’d expect a stronger depth effect (loss scaling closer to 1/depth3), not 1/depth. When training is slow (especially at low temperature), the model looks like 1/depth for a while—but that’s a training effect, not the final behavior.
Overall, this strongly suggests that most layers in LLMs act like an ensemble of similar layers whose errors average out, rather than building a neat hierarchy of concepts or following a perfectly smooth path.
What does this mean for the future?
- Depth is used “inefficiently” but robustly:
- Many layers do similar things, which is safe and stable—errors cancel—but may not be the most efficient way to use depth.
- Designing better models:
- If width and depth both help similarly (each roughly like 1 divided by their size), then under a fixed parameter budget, making width and depth grow in proportion might be a good rule of thumb.
- To get more “bang for your buck” from depth, we may need new architectures that encourage compositional use of layers—so deeper models truly add new levels of understanding, not just more averaging.
- Ideas like recurrent depth (reusing layers smartly) may help models leverage hierarchy better.
- Limitations and caution:
- The exact loss formula they use is a practical fit, not a proof from first principles.
- Other mechanisms could also produce similar inverse-depth behavior.
- Early/last layers still seem special; the middle layers are where averaging mostly happens.
In short: adding more layers helps, mainly because many similar layers average out their errors. To make deeper models more efficient, future designs should push layers to build on each other in a more clearly structured, compositional way, instead of mostly doing similar small corrections.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following specific gaps remain unresolved and suggest concrete directions for future research:
- Lack of first-principles derivation of the decomposed scaling law L = c_m/mα_m + c_ℓ/ℓα_ℓ + c_D/Dα_D + L₀; rigorously derive this decomposition (including the separation into representation-limited and transformation-limited error) and its regime of validity.
- Limited empirical validation of inverse depth scaling across diverse LLM families and training setups; replicate the hidden-state and loss-scaling analyses on multiple architectures (e.g., GPT-NeoX, Llama, Mistral), training datasets, and depths/widths to assess generality.
- Confounding factors in the Chinchilla-based fit due to reconstructed data and sparse coverage of width and depth; obtain original logs or prospectively train models with systematically varied width/depth to robustly fit αm, αℓ, and α_D.
- Unmeasured cross-terms between width and depth (and dataset size) in the scaling law; quantify interaction terms empirically, especially for small and medium models where they may not be negligible.
- Unverified claim that PDE-like attention dynamics preserve the same depth scaling as ODE-like residual dynamics; explicitly analyze attention-mediated (spatially coupled) dynamics and test whether α_ℓ changes when attention is present or modified.
- Absence of mechanistic explanation for why ensemble averaging emerges in LLMs; disentangle contributions of architecture (residual connections, normalization), optimization (optimizer, LR schedules), initialization, and data distribution to the formation of layer similarity.
- No quantitative test of layer-wise error independence assumed in central-limit arguments; estimate per-layer error covariances in trained LLMs and test whether diffusive accumulation (1/√ℓ hidden error, 1/ℓ loss) holds.
- Hidden-state analysis relies heavily on angular metrics with RMS/LayerNorm; validate conclusions with additional representational measures (e.g., CCA/SVCCA, mutual information, probing tasks, functional similarity) and test sensitivity to normalization schemes.
- Incomplete characterization of token-level heterogeneity; link “early stopping” vs “evenly updated” trajectories to token types, positions, and semantic complexity, and assess how complexity governs depth utilization.
- Unresolved role of first and last layers with large rotations; functionally characterize these layers (e.g., via probes or causal interventions) to determine what operations are depth-independent and why.
- Unverified prediction that procedural assembly yields αℓ ≈ 3 post-convergence in realistic LLMs; track αℓ over training for real models and test whether depth-scaling exponents increase with training progress toward discretization-dominated regimes.
- No test of higher-order integration analogs in LLMs; introduce architectural changes (e.g., gating, multi-step residuals, learned integrators) to emulate higher-order schemes and measure whether α_ℓ increases beyond ≈1.
- Toy model omits attention and uses small widths (m=32); scale toy experiments (wider networks, attention blocks, larger vocabularies) to assess whether ensemble averaging persists and whether α_ℓ remains ≈1.
- Mapping between “teacher temperature” and real LLM training is unclear; identify real-world analogs of distribution sharpness (e.g., label entropy, output calibration) and quantify their impact on training speed and depth scaling.
- Unsubstantiated assertion that next-token prediction is incompatible with smooth dynamics; theoretically analyze conditions under which autoregressive objectives yield non-smooth depth dynamics and empirically test with curricula/tasks emphasizing compositional structure.
- Unresolved question of whether layers form a single ensemble or multiple functional ensembles; cluster layers by function and measure how the number/size of ensembles scales with total depth.
- No systematic evaluation of architectural variants affecting depth use (e.g., Pre-LN vs Post-LN, residual scaling factors, parameter tying, ALBERT-style sharing, Mixture-of-Experts); test how these choices modulate layer similarity and α_ℓ.
- Limited task coverage; assess whether tasks requiring deeper reasoning (math, code, long-context chaining) exhibit more compositional assembly and different α_ℓ than standard next-token prediction on natural text.
- Dataset dependence is underexplored; repeat analyses across corpora with different entropy/structure (e.g., code, synthetic hierarchical data) to test how data properties shape depth utilization regimes.
- Incomplete validation of the optimal width-depth trade-off (m ∝ ℓ under N ∝ m²ℓ and αm ≈ αℓ ≈ 1); perform controlled scaling studies under fixed parameter and compute budgets to empirically determine optimal allocation.
- Assumption that cross terms are subdominant at large m, ℓ is untested; quantify their magnitude across scales and training stages to bound when the decomposed form is predictive.
- No intervention demonstrating a shift from ensemble averaging to compositional assembly; design and test architectures/training procedures (e.g., recurrent depth, hierarchical objectives, layer-wise targets) that encourage compositional depth use and measure changes in α_ℓ and hidden-state signatures.
- Limited robustness checks for layer permutation/deletion effects in relation to inverse depth scaling; systematically ablate or reorder layers and quantify how loss and α_ℓ respond.
- Insufficient analysis of context length and prompt structure; test whether longer contexts or specific prompting patterns alter depth utilization and the proportion of tokens showing early stopping.
- Lack of causal tests for the role of residual scaling (e.g., 1/√ℓ) in producing ensemble behavior; vary residual scales during training and measure impacts on layer similarity and depth scaling.
- No direct separation of representation- vs transformation-limited error in real LLMs; develop diagnostics or controlled teacher–student setups to quantify each component in trained models.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the paper’s findings that LLM loss scales approximately inversely with depth due to ensemble averaging across functionally similar layers.
- Width–depth planning for model scaling (software/AI, finance, energy)
- Use the decomposed scaling law with αm ≈ 1 and αℓ ≈ 1 to plan architectures under a fixed parameter budget N ∝ m2ℓ, targeting m ∝ ℓ for near-optimal trade-offs.
- Workflow: incorporate a “scaling planner” that predicts loss vs. width, depth, and dataset size to guide model families and SKU diversification.
- Assumptions/Dependencies: residual Transformer-like architectures; typical regime with diffusive error accumulation; fit quality may vary by family/training recipe.
- Inference cost reduction via dynamic depth gating and early exit (software/AI, energy, daily life)
- Skip middle layers for tokens that exhibit early stopping or very small per-layer updates; gate depth based on per-token metrics such as angle θ(h_l, h_{l+1}).
- Tools/Products: runtime “AngleGate” module that halts layer updates when θ falls below a threshold; flexible SLO-aware inference for on-device models.
- Assumptions/Dependencies: access to activations; robust gating thresholds; small fraction of tokens show early stop strongly (often first tokens), but most show small and even updates—use conservative gating policies.
- Layer merging/averaging to compress middle blocks (software/AI, energy)
- Replace sets of functionally similar middle layers with fewer averaged layers (e.g., compute an average transformation and distill into a single block).
- Tools/Products: “LayerMerge” pipeline for post-training compression; batch offline averaging with validation-based rollback.
- Assumptions/Dependencies: ensemble-like middle layers dominate; first/last layers should remain intact; careful verification to avoid task-specific regressions.
- Precision targeting and selective quantization (software/AI, hardware)
- Quantize the middle layers more aggressively than the first/last layers (which perform larger, depth-independent updates), shaving latency and energy without large loss increases.
- Tools/Products: “Depth-aware QAT” profiles that map precision to layer index; mixed-precision kernels optimized for middle blocks.
- Assumptions/Dependencies: angle-based update magnitudes correlate with error sensitivity; verify downstream quality on reasoning or long-context tasks.
- Training diagnostics and monitoring of hidden-state dynamics (academia, software/AI)
- Track θ(h_l, h_{l+1}) and θ(Δh_l, Δh_{l+1}) during training to detect ensemble averaging, low inter-layer correlation, and depth inefficiency early.
- Tools/Products: “AngleMeter” logging and dashboards; alarms when middle-layer updates stop improving (flat θ trend) to trigger curriculum or architecture changes.
- Assumptions/Dependencies: training pipeline access; overhead manageable; metrics calibrated per model family.
- Distillation and ensembling strategies tuned to ensemble-like layers (software/AI)
- Exploit ensemble averaging explicitly: average predictions or intermediate representations across middle layers during distillation to improve robustness and reduce variance.
- Tools/Products: “Middle-layer ensemble distillation” recipes; variance-reduction regularizers encouraging uncorrelated layer errors.
- Assumptions/Dependencies: student/teacher access; stabilization for very low-temperature teachers to avoid slow convergence.
- Teacher-temperature tuning in distillation (academia, software/AI)
- Avoid overly low temperatures in teacher distributions that slow optimization and keep students in training-dominated regimes with α_ℓ ≈ 1; choose temperatures that promote convergence toward higher-order (procedural) behavior if desired.
- Workflow: temperature sweeps with convergence-time monitoring; integrate into hyperparameter search.
- Assumptions/Dependencies: distillation setting; task-dependent optimal temperature; low temperature reduces gradient signal magnitude.
- Compute budgeting, cost forecasting, and SKU selection (finance, policy, energy)
- Use the decomposed loss model to forecast cost/performance when scaling dataset size vs. width vs. depth; align procurement and energy usage with diminishing returns from deeper ensembles.
- Tools/Products: “Loss forecaster” for portfolio planning; guidance for data center energy efficiency via depth-aware inference policies.
- Assumptions/Dependencies: fit derived from Chinchilla-like data; differences across families/training may require per-org calibration.
Long-Term Applications
The following applications require further research, scaling, or development to achieve reliable deployment.
- Architectures that encourage compositional depth over ensemble averaging (software/AI, robotics)
- Design modules and residual pathways that enforce hierarchical transformations (e.g., recurrent depth, gated residuals, multi-step integrators, explicit hierarchy-building blocks).
- Tools/Products: “Compositional Transformers” with depth-specialization objectives and hierarchical routing.
- Assumptions/Dependencies: new training objectives, curricula, and datasets; risk of reduced robustness without ensemble effects.
- Depth-aware auxiliary losses for layer specialization (academia, software/AI)
- Introduce hierarchical targets or supervision at multiple depths to induce progressive abstraction (moving away from evenly incremental updates).
- Tools/Products: “HierarchyLoss” packages; multi-depth distillation schemes.
- Assumptions/Dependencies: label availability or synthetic targets; tuning to avoid optimization instability.
- Angle-guided neural architecture search (software/AI)
- Use θ(h_l, h_{l+1}) and inter-layer correlation patterns as NAS signals for selecting depth, block types, and routing to increase compositionality.
- Tools/Products: “AngleNAS” frameworks combining proxy metrics with search algorithms.
- Assumptions/Dependencies: reliable proxy metrics; transferability across tasks/domains.
- Adaptive depth allocation per task, context length, and token type (software/AI, energy)
- Develop policies that dynamically adjust depth per input complexity and position in sequence to balance quality and cost.
- Tools/Products: SLO- and token-complexity-aware schedulers; enterprise inference services with per-request depth budgets.
- Assumptions/Dependencies: robust complexity estimators; safety guardrails; user experience constraints.
- Hardware–software co-design for elastic depth execution (hardware, energy, cloud ops)
- Build kernels and memory hierarchies that support fine-grained skipping, merging, or re-weighting of middle layers at runtime with minimal overhead.
- Tools/Products: “ElasticDepth” runtimes; accelerator primitives for layer ensemble operations.
- Assumptions/Dependencies: vendor support; compiler/runtime integration; workload characterization.
- Dataset design to foster compositional learning (academia, education)
- Curate training corpora emphasizing hierarchical structures and reasoning curricula that reward deeper, progressive abstraction rather than averaging.
- Tools/Products: curriculum generators; compositional benchmarks.
- Assumptions/Dependencies: measurable gains over ensemble-like baselines; alignment with target domains.
- Revised scaling-law standards and benchmarks (academia, policy)
- Establish community benchmarks and reporting standards that separate width, depth, and dataset-size contributions, enabling more accurate compute-optimal planning and regulation.
- Tools/Products: open datasets, evaluation harnesses, and reporting templates for decomposed scaling.
- Assumptions/Dependencies: consensus building; broad participation across model families.
- Cross-modal extensions and validation (vision, speech, multimodal)
- Test whether inverse depth scaling from ensemble averaging generalizes to ViTs and speech transformers; port immediate efficiencies to multimodal systems.
- Tools/Products: multimodal “AngleMeter”; depth-aware compression toolkits for non-text domains.
- Assumptions/Dependencies: comparable residual architectures; domain-specific quirks (e.g., spatial coupling).
General Assumptions and Dependencies
- Findings are strongest for residual Transformer-like LLMs with layer norms; behavior in non-residual or highly modified architectures may differ.
- The inverse depth exponent α_ℓ ≈ 1 is an empirical typical-case result; edge cases, small models, or highly specialized tasks can deviate.
- Many proposed efficiencies rely on access to internal activations and retraining or distillation capacity; black-box deployment limits applicability.
- First and last layers contribute large, depth-independent updates and should be preserved or treated cautiously in compression/pruning.
- Cross terms among width, depth, and dataset size are minimized in the large m, ℓ regimes but can matter in small models or atypical training settings.
Glossary
- Adam: An adaptive gradient-based optimizer commonly used to train neural networks. "Students are trained for $40000$ steps using Adam"
- central limit theorem: A statistical result implying that the average of many independent errors tends to a normal distribution, yielding error reduction proportional to 1/sqrt(n). "due to the central limit theorem \cite{bahri2024explaining, song2024resourcemodelneuralscaling}."
- compositional assembly: The regime where deeper layers compose increasingly abstract features or operations. "We will call this perspective on depth usage as compositional assembly (\cref{fig:abstract})."
- cross-entropy: A loss measuring the difference between two probability distributions; for classification it equals negative log-likelihood. "KL-divergence is cross-entropy subtracting the entropy of target distributions, which is constant, and has no difference in scaling behaviors."
- cross terms: Loss contributions arising from interactions between depth- and width-dependent errors. "Cross terms arise from the interplay between imperfect representation and imperfect transformation, and are expected to be higher order and subdominant when both and are large."
- depth scaling exponent: The exponent αℓ characterizing how loss scales as a power of depth ℓ. "The depth scaling exponent is near $1$ in the early stage of training but increases to $3$ after training."
- discretization error: Error introduced when approximating continuous dynamics with discrete layers or time steps. "Once training converges, the loss is dominated by discretization error."
- ensemble averaging: A regime where many similar layers act like an ensemble, reducing error through averaging of independent errors. "In this regime of depth utilization, which we call ensemble averaging, the loss will be a power law with depth due to the central limit theorem"
- first-order integration scheme: A numerical ODE method (e.g., forward Euler) whose local truncation error scales with the first power of the step size. "The residual stream corresponds to a first-order integration scheme, and for smooth we have"
- hidden state: The internal vector representation that is updated by each layer and propagated through the network. "we design experiments to probe how hidden states evolve across layers."
- irreducible loss: The loss floor determined by the target distribution’s entropy that cannot be reduced by scaling model or data. "and is the irreducible loss associated with the entropy of the target distribution."
- KL-divergence: Kullback–Leibler divergence; a measure of how one probability distribution diverges from another, often used as a training objective. "train the student by minimizing the KL-divergence"
- LLM head: The final linear projection that maps hidden states to vocabulary logits for next-token prediction. "the LLM head to generate logits for next-token prediction."
- layer norm: A normalization technique applied per token that stabilizes and standardizes activations within a layer. "Due to the wide use of layer norms in LLMs"
- logits: The raw, unnormalized scores output by a model before applying softmax to form probabilities. "generate logits for next-token prediction."
- MLP (Multilayer Perceptron): A feedforward neural network consisting of linear layers and nonlinear activations. "Each residual block consists of a two-layer MLP,"
- neural ODEs: A viewpoint that treats deep residual networks as continuous-time dynamical systems governed by ordinary differential equations. "discrete approximations of smooth dynamical systems, i.e., neural ODEs \cite{chen2018neural,sander2022residual,chizat2025hidden}"
- neural scaling laws: Empirical relationships showing how loss improves predictably with increases in model size and data. "Neural scaling laws relate loss to model size in LLMs, yet depth and width may contribute to performance differently"
- PCA (Principal Component Analysis): A technique that projects data onto orthogonal directions of maximal variance to analyze dominant patterns. "We perform principal component analysis (PCA) of these vectors (\cref{app:hid})"
- PDEs: Partial differential equations; continuous models capturing spatially coupled dynamics. "are better described by PDEs rather than ODEs."
- power law: A functional relationship where one quantity varies as a constant times a power of another variable. "loss is found to have power-law relationships with these factors"
- procedural assembly: The regime where depth discretizes and follows smooth transformation dynamics (neural ODE perspective). "which we refer to as procedural assembly."
- residual block: A network module that adds its input to the block’s transformation output (skip connection). "The hidden state then propagates through residual blocks,"
- residual connections: Skip connections that add inputs to outputs, improving optimization and stability in deep networks. "Our toy model captures a key architectural ingredient of Transformers: residual connections."
- residual networks: Deep architectures built from residual blocks (ResNets), often enabling very deep models. "A second perspective views deep residual networks as discrete approximations of smooth dynamical systems"
- RMSNorm: Root Mean Square Layer Normalization; normalizes activations by their root mean square without centering. "h_0 = \mathrm{RMSNorm}(x)."
- softmax: A function that converts logits into a probability distribution over classes. "before applying softmax to obtain the target distribution."
- teacher-student setup: A training paradigm where a student model learns to match outputs generated by a (usually larger or deeper) teacher model. "We adopt a teacher-student setup, in which the teacher generates training data for the student."
- temperature: A scaling factor on logits that controls the sharpness of the softmax probability distribution. "the teacher ``temperature'' strongly affects training dynamics"
- Transformer: A neural architecture based on attention and feedforward layers, widely used in LLMs. "In each Transformer layer, e.g., layer , information about previous tokens can be grabbed"
- width-depth trade-off: The balance between network width and depth under a fixed parameter budget to optimize performance. "the optimal width-depth trade-off under a fixed parameter budget implies depth scaling logarithmically with width"
Collections
Sign up for free to add this paper to one or more collections.

