- The paper introduces a unified feed-forward framework that explicitly couples 3D trajectories with per-frame pointmaps to enhance multi-frame alignment.
- It enforces geometric consistency via bidirectional trajectory-pointmap and pose constraints, reducing drift and overlap artifacts in dynamic scenes.
- Experimental results show state-of-the-art performance in 3D tracking, camera pose, and depth estimation across diverse benchmarks.
TrajVG: 3D Trajectory-Coupled Visual Geometry Learning
Recent feed-forward multi-frame 3D reconstruction models have demonstrated impressive performance in visual geometry tasks, but encounter substantial degradation when applied to videos with object motion patterns or complex dynamics. Existing global-reference methods (e.g., VGGT) are brittle in multi-motion scenarios due to ambiguous anchoring, while local-frame approaches depend heavily on estimated relative poses, leading to drift and overlapping artifacts. TrajVG addresses these limitations by elevating cross-frame 3D correspondence from an implicit computation to an explicit prediction, leveraging camera-coordinate 3D trajectories as geometric tie points for robust multi-frame alignment.
Methodology
TrajVG introduces a unified feed-forward reconstruction framework that combines three core branches: sparse 3D tracking, per-frame local point maps, and relative camera poses. The model is engineered to enforce geometric consistency through explicitly designed objectives: bidirectional trajectory–pointmap consistency and pose consistency anchored by static tracks. These objectives are operationalized with controlled gradient flows to isolate error signals and suppress instability, particularly from dynamic regions.
In detail, the 3D tracking branch predicts camera-coordinate trajectories conditioned jointly on multi-frame visual features and the current geometric estimates. These predicted tracks are coupled to the pixel-aligned point maps via bidirectional losses, regularizing both pointmap fusion and track estimation. Pose estimation is further constrained by transforming tracks into a common reference frame using predicted relative motions, applying static-point gating to reduce the impact of dynamic points.
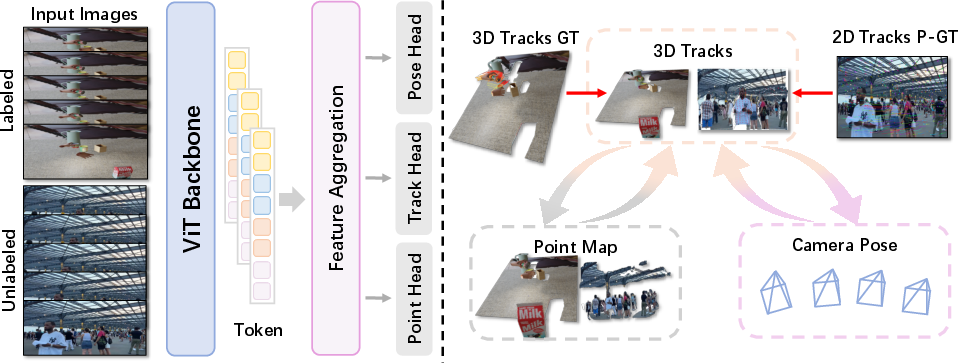
Figure 1: TrajVG’s architecture enables joint tracking, pointmap, and pose estimation, with explicit coupling for improved geometry reconstruction and camera motion.
This pipeline enables robust optimization on static as well as dynamic scenes. To scale to in-the-wild video, TrajVG reformulates coupling constraints into self-supervised objectives, leveraging pseudo 2D tracks for correspondence signals in scenarios lacking ground-truth 3D trajectory labels.
Semi-Supervised Training and Generalization
A major contribution of TrajVG is its mixed-supervision training paradigm. Self-supervised coupling terms are used, drawing correspondence signals from off-the-shelf 2D trackers. These pseudo tracks are sampled to generate 3D pointmap observations, enabling the same consistency objectives to train the model without explicit metric annotations. Correspondence-driven losses refine alignment between tracking and geometry heads, while static anchor consistency guides relative pose estimation. This design achieves superior generalization, especially in real-world, uncontrolled video.

Figure 2: Semi-supervised training significantly improves pointmap detail and eliminates overlap artifacts in in-the-wild video data.
Experimental Evaluation
TrajVG is rigorously benchmarked across five tasks: 3D tracking, camera pose estimation, point map estimation, video depth, and monocular depth. Evaluation is performed on diverse datasets (TAPVid-3D, Sintel, ScanNet, DTU, ETH3D, 7-Scenes, NRGBD), including dynamic and static environments, indoor and outdoor field scenarios.
3D Point Tracking: TrajVG achieves superior performance over modular pipelines and native 3D trackers. On the TAPVid-3D benchmark, TrajVG outperforms existing methods in AJ$_{\text{3D}$, APD$_{\text{3D}$, and OA metrics, demonstrating robust trajectory accuracy and visibility prediction.
Camera Pose Estimation: TrajVG ranks at or near the top across all pose metrics on RealEstate10K, Co3Dv2, Sintel, TUM-dynamics, and ScanNet. The method consistently minimizes local pose errors and achieves high global trajectory accuracy, outperforming prior state-of-the-art feed-forward models.
Point Map Estimation: On scene-centric ETH3D and complex long video sequences (7-Scenes, NRGBD), TrajVG demonstrates the best or competitive results across Accuracy, Completion, and Normal Consistency metrics, confirming stable performance even over extended trajectories.
Video Depth Estimation: TrajVG sets new standards in dynamic environments, achieving the lowest Abs Rel errors in scale-only and scale-and-shift protocols, excelling particularly in the challenging Sintel and Bonn datasets.
Monocular Depth Estimation: TrajVG delivers state-of-the-art zero-shot results, ranking first on Bonn and NYU-v2, and remains highly competitive on Sintel and KITTI benchmarks.

Figure 3: Visualization results of TrajVG on in-the-wild videos, showing improved geometry quality, detail preservation, and reduced duplication artifacts.

Figure 4: Qualitative comparison of field scenario multi-view 3D reconstruction; TrajVG achieves superior reconstruction fidelity, while baselines suffer from overlaps and detail loss.
Ablation Analysis
Comprehensive ablation studies validate the impact of each architectural component and training strategy. The addition of the 3D tracking branch improves point-map estimation, reflecting the synergy of geometry and correspondence learning. Camera consistency and bidirectional coupling provide complementary constraints, yielding further gains. Semi-supervised losses enhance performance in real-world settings, as evidenced by improved trajectory and pose metrics, as well as visual quality (see Figure 2). Tracking-related losses are particularly effective in dynamic scenes, substantially boosting trajectory accuracy.
Implications and Future Directions
TrajVG's explicit geometric coupling improves both theoretical understanding and practical robustness in multi-frame 3D reconstruction. The architecture enables error signals to directly inform both geometry and pose branches, eliminating misalignment artifacts and drift. Mixed-supervision training translates strong geometric priors to natural videos, scaling correspondence learning effectively.
The approach implications are broad for spatially-aware systems in AR, robotics, and navigation. Explicit 3D trajectory coupling may inspire further architectures in visual geometry, including more advanced cross-frame data association, adaptive gating for dynamic regions, and unsupervised geometric learning. Future work may extend TrajVG to non-Euclidean and more richly dynamic environments, explore further integration of semantic cues, or optimize for real-time deployment.
Conclusion
TrajVG provides an explicit, trajectory-coupled framework for feed-forward 3D reconstruction, coupling sparse tracks, dense geometry, and pose, with robust semi-supervised training for in-the-wild generalization. The method achieves consistently superior performance across multiple visual geometry tasks, validating its architectural and optimization principles, and establishing a new paradigm for geometric consistency and multi-frame spatial reasoning (2602.04439).

