Efficient Estimation of Kernel Surrogate Models for Task Attribution
Abstract: Modern AI agents such as LLMs are trained on diverse tasks -- translation, code generation, mathematical reasoning, and text prediction -- simultaneously. A key question is to quantify how each individual training task influences performance on a target task, a problem we refer to as task attribution. The direct approach, leave-one-out retraining, measures the effect of removing each task, but is computationally infeasible at scale. An alternative approach that builds surrogate models to predict a target task's performance for any subset of training tasks has emerged in recent literature. Prior work focuses on linear surrogate models, which capture first-order relationships, but miss nonlinear interactions such as synergy, antagonism, or XOR-type effects. In this paper, we first consider a unified task weighting framework for analyzing task attribution methods, and show a new connection between linear surrogate models and influence functions through a second-order analysis. Then, we introduce kernel surrogate models, which more effectively represent second-order task interactions. To efficiently learn the kernel surrogate, we develop a gradient-based estimation procedure that leverages a first-order approximation of pretrained models; empirically, this yields accurate estimates with less than $2\%$ relative error without repeated retraining. Experiments across multiple domains -- including math reasoning in transformers, in-context learning, and multi-objective reinforcement learning -- demonstrate the effectiveness of kernel surrogate models. They achieve a $25\%$ higher correlation with the leave-one-out ground truth than linear surrogates and influence-function baselines. When used for downstream task selection, kernel surrogate models yield a $40\%$ improvement in demonstration selection for in-context learning and multi-objective reinforcement learning benchmarks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
Modern AI systems learn many things at once (like translating, coding, doing math, and understanding text). This paper asks a simple question: when an AI is trained on many different tasks, how much does each task actually help (or hurt) the AI’s performance on something we care about? The authors call this task attribution.
What questions did the authors ask?
- Can we measure how much each training task helps a target task without retraining the whole AI many times?
- Why do simple “add-things-up” methods miss important interactions between tasks?
- Can we build a smarter, still-efficient method that captures teamwork effects between tasks (like when two tasks together help a lot, or cancel each other out)?
- Will this new method work across different areas, like math problems for transformers, in-context learning for LLMs, and multi-task reinforcement learning?
How did they try to answer them?
The authors use the idea of surrogate models and a trick with gradients to make things fast.
The simple idea of surrogate models
Think of the training process like a black box: you pick a set of tasks to train on, and you get a performance score on the target task. A surrogate model is a small, easy-to-run model that learns to predict that score for any chosen set of tasks. Once this surrogate is trained, you can quickly ask “what happens if I include task A but not task B?” without retraining the big AI.
Why linear surrogates miss “teamwork”
A linear surrogate says: “the total effect is just the sum of individual task effects.” That’s like saying “adding more study subjects always helps by a fixed amount,” which ignores teamwork. In reality:
- Two tasks might help each other (synergy).
- One task might hurt another (antagonism).
- Some effects only appear when certain tasks are combined (XOR-type behavior).
Linear models miss this. The authors also show mathematically that when the world is almost linear, linear surrogates behave like a classic tool called influence functions (which estimate how much the result changes if you give a tiny extra weight to a task). But when interactions are strong, both linear surrogates and basic influence functions fall short.
Kernel surrogate models: capturing teamwork
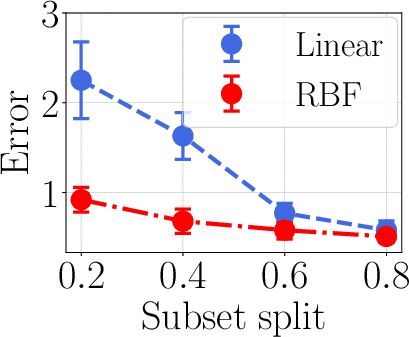
To handle teamwork effects, the authors use kernel surrogate models (specifically with an RBF kernel). You can think of a kernel like a flexible ruler that can bend to fit curves rather than just straight lines. This lets the surrogate model represent complex, non-additive relationships between tasks.
They train this kernel surrogate using kernel ridge regression: it learns a smooth, non-linear function that maps any chosen set of tasks to a predicted performance score.
Making it efficient with gradients
A big challenge: training a surrogate usually means training many versions of the large AI on many different task sets—which is too slow.
The authors avoid this by using a first-order (straight-line) approximation around a fixed model (like a pretrained checkpoint). In plain terms:
- The model’s gradients are like “fingerprints” that tell you how its output would change if its parameters moved a little.
- Compute the model’s outputs and gradients once at the start.
- Use these gradients to quickly estimate how the model would perform if it had been trained on different task combinations.
- Compress these gradients with random projections so it runs quickly, even on large models.
They check that this approximation is accurate (on average, under about 2% relative error across tasks), which makes the whole pipeline fast and practical.
What did they find?
Across several experiments—modular arithmetic reasoning, in-context learning with a LLM (Qwen3-8B), and multi-objective reinforcement learning—the kernel surrogate method consistently beat the baselines.
Key takeaways:
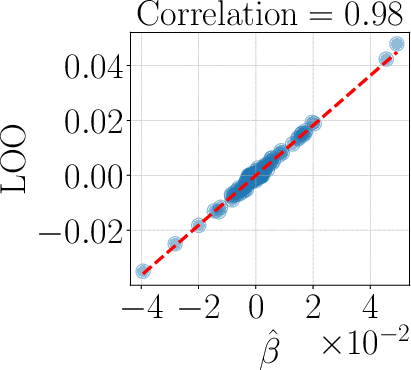
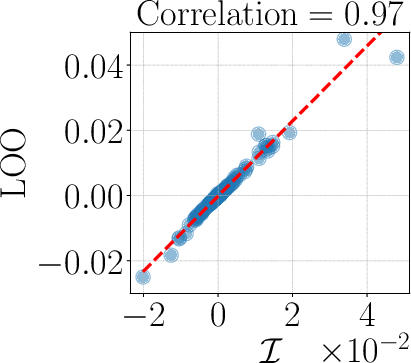
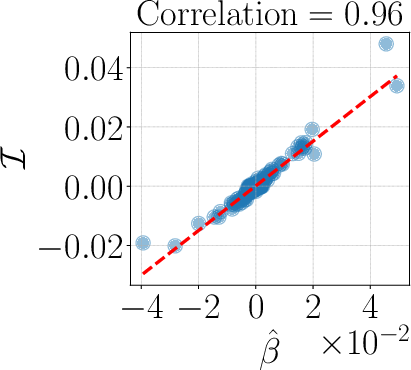
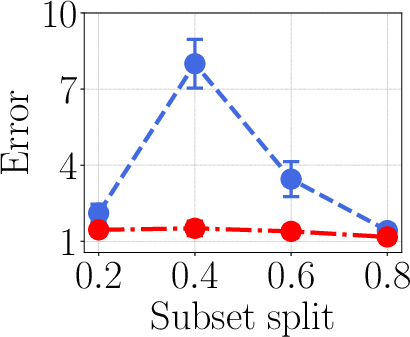
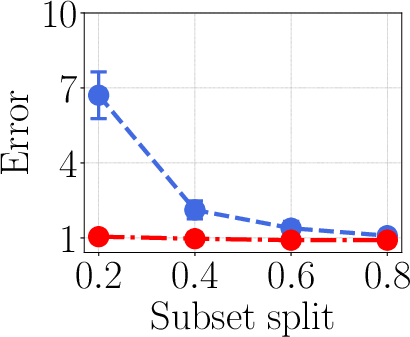
- Compared to linear surrogates and influence-function-style baselines, kernel surrogates had about 25% higher correlation with the “ground truth” leave-one-out scores (the gold-standard measure where you actually retrain without one task).
- The gradient-based shortcut gave accurate estimates with under about 2% relative error, without retraining the big model many times.
- For choosing which tasks or examples to include (downstream selection):
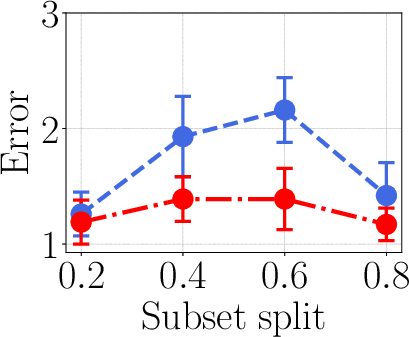
- In in-context learning, picking demonstrations guided by the kernel surrogate reduced loss by about 40% compared to baselines.
- In multi-objective reinforcement learning, it improved performance (rewards) while keeping runtime low.
- On tricky setups (like XOR-like relationships in modular arithmetic), the kernel surrogate improved attribution accuracy by up to about 42% over linear methods.
Why does this matter?
- Better decisions about training: If you know which tasks help (and which combinations help the most), you can design smarter training curricula, avoid negative transfer, and save time and compute.
- Improved in-context learning: You can choose better example prompts for LLMs, leading to more accurate answers.
- Stronger multi-task RL: You can select task sets that boost each other, leading to better policies with less trial and error.
- Scalable interpretability: This method gives a practical way to understand how different training pieces shape model behavior, without the cost of retraining for every scenario.
In short, the paper shows that modeling teamwork between tasks really matters, and it provides a practical, efficient tool—kernel surrogate models with gradient-based estimation—to measure it at scale.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, prioritized for actionable follow-up by future researchers.
- Differentiability of F(s): The analysis treats binary task indicators s as continuous weights and assumes F(s) is twice differentiable via Ŵ(s). Precise conditions ensuring smoothness (e.g., uniqueness of minimizers, strong convexity, stability of implicit-function relationships) in non-convex deep networks are not established.
- Influence-function prerequisites: The derivation requires an invertible Hessian. How to robustly handle singular/ill-conditioned Hessians in modern deep nets (e.g., damping, low-rank preconditioning) and the impact on attribution accuracy is not studied.
- Tightness of the “small curvature” assumptions: Bounds hinge on small second- and third-order terms (c2, c3). There is no characterization of when these constants are small in practice and how to diagnose or control them across architectures, datasets, and training regimes.
- Theoretical generalization of kernel surrogates: No sample complexity or generalization bounds are provided for kernel ridge regression over {0,1}K, relating m (number of subsets), K, kernel hyperparameters, curvature of F, and noise to prediction error.
- Adaptive subset sampling: Subsets are i.i.d. Bernoulli(p). The choice of p and m is not optimized; there is no active/experimental design strategy to select informative subsets or minimize second-order bias terms identified in the linear analysis.
- Scalability of KRR: The kernel approach requires solving a linear system in m with O(m2) memory and O(m3) time. Practical limits and remedies (e.g., Nyström approximations, random features, conjugate gradients) are not benchmarked for large m (thousands to tens of thousands).
- Kernel choice and task geometry: RBF with Hamming distance may be misaligned with true task relationships. Designing and evaluating task-aware kernels (e.g., based on gradient/Fisher similarities, representation distances, or learned metric) is not explored.
- Hyperparameter selection: Kernel length-scale γ and ridge λ are chosen via cross-validation without guidance. Principled tuning strategies, stability analyses, and sensitivity studies are absent.
- From global surrogate to individual attributions: The paper averages predictions over subsets containing an item to derive per-task scores. Formal connections to Shapley values (efficiency, symmetry, additivity) and unbiased Monte Carlo estimators are not established or compared.
- First-order gradient approximation validity: The “GradEx” estimator assumes small first-order Taylor error. Conditions (step sizes, optimization trajectories, proximity to NTK regime), failure modes, and remedies (e.g., second-order corrections, local relinearization) are not analyzed.
- Projection dimension trade-offs: Gradient features are randomly projected; JL-based claims lack explicit dimensionality requirements vs. desired error. Empirical ablations on projection dimension vs. accuracy, memory, and runtime are missing, especially for LLMs.
- Memory and compute on large models: Computing and storing gradients for all training samples on 34B-parameter models is potentially prohibitive. Concrete memory footprints, batching strategies, checkpointing, and distributed implementations are not reported.
- Path dependence in RL and ICL: Mapping subsets s to performance in RL (SAC, non-stationary environments) and ICL (prompt-specific dynamics) may be highly path-dependent. A theoretical justification for using gradients at W0 to predict outcomes after full training is lacking; counterexamples and mitigation strategies are not discussed.
- Attribution under fractional task weights: Training often uses continuous task reweighting or curriculum schedules. Extending the framework from binary inclusion to continuous s (and validating differentiability and estimation quality) remains open.
- Loss- and metric-agnostic claims: The approach is tested primarily on prediction losses and average rewards; applicability to non-decomposable objectives (contrastive, preference learning), generative metrics, and long-horizon planning is unverified.
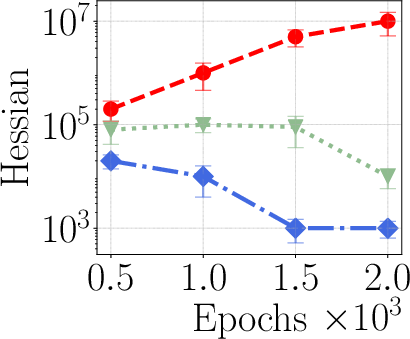
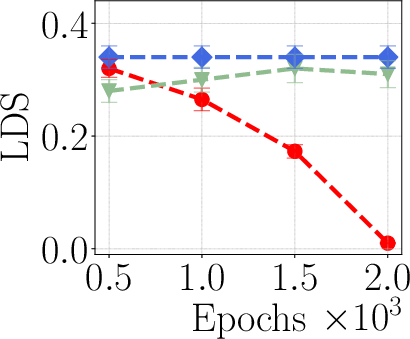
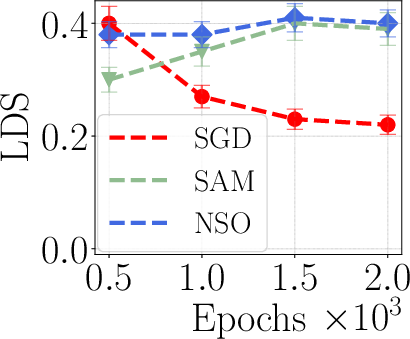
- Robustness across optimizers: Beyond a small Hessian-regularization ablation (SGD vs. SAM/NSO), comprehensive studies across optimizers (AdamW, Lion), regularization (weight decay, label smoothing), and training noise (batch size, data order) are absent.
- Choice of task-level normalization: Eq. (1) averages over selected tasks, but how task sample size n_k, imbalance, or per-task loss scaling affect attribution is not analyzed; alternative normalizations (e.g., size-weighted, variance-weighted) may change results.
- Ground-truth baselines and fairness: LDS relies on retraining on m subsets; it is unclear whether all methods (including \algo) are trained/evaluated under identical budgets and whether approximations introduce unfair advantages. A standardized, cost-matched protocol is needed.
- Statistical reporting and calibration: Beyond Spearman correlations and residual errors, there is no analysis of calibration, absolute errors, confidence intervals, or error decomposition (bias vs. variance), limiting interpretability of practical reliability.
- Sensitivity to initialization W0: The method’s reliance on gradients at a single pretrained W0 raises concerns about robustness to different inits or checkpoints; ensemble over inits or checkpoint selection criteria is not investigated.
- Distribution shift in test tasks: Attributions are computed for a fixed T_test; sensitivity to shifts in test distributions/domains and the stability of task influence under such shifts are not explored.
- Formal proof of RBF universality on {0,1}K: The paper claims universal expressivity but does not provide rates or constructive guidance on kernel length scales needed to approximate typical attribution functions in this discrete space.
- Privacy implications: Storing per-sample gradients can leak sensitive information. Privacy risks and mitigations (e.g., DP-noise, secure aggregation) are not addressed.
- Negative and antagonistic interactions: While claiming to capture non-additivity, the method lacks diagnostics to detect, quantify, and visualize antagonism/XOR effects and to guide actionable interventions (e.g., task removal or curriculum changes).
- Application breadth: Multi-group fairness and demographic-group attribution are mentioned but not empirically studied; ethics, fairness implications, and safeguards in real deployments remain open.
Practical Applications
Overview
Based on the paper’s findings—kernel surrogate models for task attribution, a gradient-based estimation procedure, and empirical gains over linear surrogates and influence-function baselines—the following applications translate the research into real-world impact. Each item notes use cases across sectors, potential tools or workflows, and assumptions or dependencies that affect feasibility.
Immediate Applications
- Multi-task training optimization and negative transfer detection
- Sector: software/AI, healthcare, finance, e-commerce
- Use case: quantify synergy/antagonism among training tasks; reweight, include, or exclude tasks to boost target performance without expensive retraining
- Tool/workflow: “Kernel Surrogate Attribution (KSA) library” for PyTorch/TF; integrate into MLOps to run GradEx once (logits + gradients at initialization), fit kernel ridge regression (RBF), then run “what-if” evaluations
- Assumptions/dependencies: access to model parameters and gradients; first-order approximation error is small; subset sampling m is sufficient; kernel matrix memory scales with m
- Prompt demonstration selection for in-context learning (ICL)
- Sector: education, customer support, productivity software
- Use case: pick top-k examples that maximize LLM accuracy or minimize loss for specific prompts; reduces inference errors and boosts task-specific performance
- Tool/workflow: “Prompt Optimizer” service that ranks candidate demonstrations via KSM predictions; plug into retrieval-augmented generation pipelines
- Assumptions/dependencies: open-weight LLMs or finetune-able models for gradient access; stable mapping from demo choice to performance; representative subset sampling
- Multi-objective reinforcement learning (RL) co-training selection
- Sector: robotics, operations research, industrial automation
- Use case: select companion tasks that yield positive transfer for a target task (e.g., Meta-World MT10); improve cumulative reward with minimal extra training
- Tool/workflow: “RL Task Synergy Planner” that uses KSM to recommend task mixes and reward weightings; schedule co-training experiments
- Assumptions/dependencies: stable RL training protocol (e.g., SAC), ability to define tasks/environments as groups, modest non-stationarity, gradient/logit extraction from policy/value networks
- Data curation and cleansing for fine-tuning
- Sector: data engineering, software/AI
- Use case: identify datasets or task groups that degrade target performance; deduplicate antagonistic data; prioritize high-value sources
- Tool/workflow: “Attribution Dashboard” highlighting task-level influence scores; automated filters to exclude harmful subsets
- Assumptions/dependencies: clear task grouping, chosen performance metric F for the target domain, trustworthy gradient computation
- Group-level fairness analysis and model auditing
- Sector: policy/regulation, academia, public sector
- Use case: quantify how training on different demographic or subgroup tasks shapes downstream behavior; identify groups that unduly sway predictions
- Tool/workflow: “Fairness Attribution Dashboard” combining KSM with group labels; compare subgroup influence on metrics like accuracy, calibration, or error rates
- Assumptions/dependencies: high-quality group annotations; selected test metrics reflect fairness goals; caution in interpreting approximations for regulatory use
- Curriculum learning and scheduling
- Sector: education AI, enterprise ML teams
- Use case: order tasks to maximize learning by exploiting predicted synergies; avoid early exposure to antagonistic tasks
- Tool/workflow: “Curriculum Scheduler” querying KSM for task sequences with predicted gains
- Assumptions/dependencies: relatively stationary learning dynamics across phases; consistent task definitions and loss functions
- Rapid “what-if” training simulation for experiment design
- Sector: research, MLOps
- Use case: simulate performance effects of changing task mixtures before committing compute; prune low-yield experiments
- Tool/workflow: “Task Attribution Simulator” using GradEx and KRR; experiment selection interface in internal platforms
- Assumptions/dependencies: surrogate trained on representative subset distributions; care when extrapolating beyond sampled compositions
- Knowledge distillation dataset selection
- Sector: software/AI
- Use case: pick student-training subsets that most improve target tasks, guided by KSM influence estimates; reduce distillation time
- Tool/workflow: “Distillation Data Selector” integrated with teacher/student pipelines
- Assumptions/dependencies: teacher/student gradients available; reliable metric linkage to distillation objectives
- Continual/domain adaptation task inclusion
- Sector: MLOps, enterprise AI
- Use case: decide which new domain tasks to incorporate during continual learning without full retraining; manage catastrophic forgetting risk
- Tool/workflow: “Adaptation Advisor” using KSM to forecast impact of new tasks
- Assumptions/dependencies: incremental access to gradients/logits; consistent target metric; modest domain shift
- Training resource allocation and compute budgeting
- Sector: enterprise AI, cloud/DevOps
- Use case: select task subsets that yield target performance under limited compute; reduce LOO retraining costs
- Tool/workflow: “Compute-Aware Task Planner” that optimizes task mix via KSM predictions
- Assumptions/dependencies: accurate surrogate under chosen sampling regime; known compute constraints and costs
Long-Term Applications
- Data valuation, licensing, and compensation
- Sector: legal/finance, data marketplaces
- Use case: assign economic value to datasets/tasks based on their estimated contribution to downstream performance; inform licensing fees and revenue-sharing
- Tool/workflow: “Data Valuation Engine” combining KSM influence with economic models (e.g., Shapley-like methods adapted to tasks)
- Assumptions/dependencies: robust valuation framework, standardized metrics, accepted approximations; potential legal scrutiny of estimation uncertainty
- Regulatory auditing for foundation models
- Sector: policy/regulation, public sector
- Use case: systematic attribution of model behavior to training sources; support transparency and accountability requirements
- Tool/workflow: “Attribution Audit Suite” embedding KSM in compliance workflows and data cards
- Assumptions/dependencies: access to training provenance, gradients for large models, reproducible pipelines; standardization across organizations
- Federated learning client contribution and incentives
- Sector: distributed AI, privacy-preserving learning
- Use case: quantify client task contributions to target performance; design fair incentives and participation policies
- Tool/workflow: “Federated Incentive Estimator” integrating KSM under secure aggregation
- Assumptions/dependencies: privacy-preserving gradient access, robust noise handling, secure computation; non-i.i.d. client distributions
- Robotics lifelong learning curricula
- Sector: robotics, autonomous systems
- Use case: plan multi-task skill acquisition with positive transfer; avoid antagonistic task pairs; reduce real-world trial costs
- Tool/workflow: “Lifelong Curriculum Planner” using KSM over evolving skill/task graphs
- Assumptions/dependencies: hardware constraints, non-stationarity, safety verification; surrogate stability in highly dynamic settings
- Energy and infrastructure control via RL
- Sector: energy, transportation, smart grids
- Use case: choose training tasks/scenarios that improve deployment objectives (e.g., grid stability) without exhaustive retraining
- Tool/workflow: “Infrastructure RL Planner” applying KSM for scenario/task selection
- Assumptions/dependencies: domain-specific reward definitions, rigorous simulation fidelity, safety-critical validation
- Extending attribution beyond prediction to planning and agentic behaviors
- Sector: advanced AI research
- Use case: attribute training tasks to emergent capabilities (planning, tool-use) where interactions are highly nonlinear
- Tool/workflow: “Agent Attribution Lab” adapting KSM to sequential decision-making and non-decomposable losses
- Assumptions/dependencies: methodological extensions (e.g., to preference/contrastive losses), richer behavioral metrics, longitudinal studies
- Large-scale foundation model training optimization
- Sector: AI labs, hyperscalers
- Use case: optimize massive task mixes (code, math, multilingual) by modeling higher-order interactions at scale
- Tool/workflow: “FM Task Optimizer” with approximate kernels (e.g., Nyström, random features) and distributed GradEx
- Assumptions/dependencies: scalable kernel approximations, memory-efficient projections, engineering integration; access to full training stack
- Standardization of dataset/task provenance and attribution reporting
- Sector: industry consortia, standards bodies
- Use case: create common schemas and benchmarks for reporting task influences; facilitate interoperability and audits
- Tool/workflow: “Attribution Reporting Standard” built around KSM-compatible metrics and APIs
- Assumptions/dependencies: cross-organizational coordination, governance, evolving best practices
- Safety and risk mitigation via attribution-guided filtering
- Sector: AI safety, compliance
- Use case: detect training tasks correlated with undesirable behaviors (e.g., misinformation, bias) and reduce their influence
- Tool/workflow: “Risk Filter” that flags and down-weights high-risk tasks based on KSM scores
- Assumptions/dependencies: robust mapping from influence to safety outcomes, ongoing red-teaming; policy alignment
- Marketplace and procurement optimization for training data
- Sector: procurement, data vendors
- Use case: select vendors/datasets that deliver best marginal gains for targeted capabilities
- Tool/workflow: “Data Procurement Optimizer” using KSM projections to rank offers
- Assumptions/dependencies: consistent task definitions across vendors; legal/contractual frameworks; surrogate generalization across sources
Cross-cutting assumptions and dependencies
- Model access: many applications require access to model parameters, logits, and gradients at initialization; closed-source models limit applicability.
- Approximation quality: the method depends on small first-order Taylor errors and representative subset sampling; strong distribution shifts or highly curved loss landscapes reduce accuracy.
- Kernel scalability: RBF kernel matrices scale as O(m²); large m (many subsets) needs approximations (Nyström, random features) and careful memory management.
- Metric selection: performance metric F must reflect real-world objectives (accuracy, reward, safety) and be interpretable for stakeholders (e.g., regulators).
- Task definition: clear grouping of data into tasks or cohorts is essential; mis-specified tasks can degrade attribution quality.
- Reliability and governance: for policy and licensing, statistical estimation uncertainty must be quantified (confidence intervals, sensitivity analyses) and incorporated into decision-making.
Glossary
- Bayesian influence functions (BIF): A Bayesian extension of influence functions that measures influence as a covariance under a localized posterior, estimated via sampling. "Bayesian influence functions (BIF)"
- Bernoulli distribution: A distribution over binary outcomes with a single success probability, often used to sample inclusion indicators. "Bernoulli distribution"
- Binomial distribution: The distribution of the number of successes in a fixed number of independent Bernoulli trials. "the Binomial distribution"
- contrastive loss: A loss function used to bring similar examples closer and dissimilar ones apart in representation space. "contrastive loss"
- data attribution: Methods that quantify how elements of the training data affect model behavior or predictions. "data attribution"
- Datamodels: Surrogate functions that predict model outputs from data subsets by fitting a mapping from inclusion indicators to performance. "datamodels"
- delta method: An asymptotic technique for approximating the distribution (or moments) of a function of random variables, used here to linearize covariance statistics. "applying the delta method"
- Gauss-Newton Hessian approximation: An approximation to the Hessian using Gauss-Newton structure to reduce computation in second-order methods. "Gauss-Newton Hessian approximation"
- Gaussian random convolutions: Randomized linear projections (here applied to gradients) using Gaussian filters to reduce dimensionality. "Gaussian random convolutions"
- heat kernels: Diffusion-based kernels on graphs/manifolds that capture connectivity patterns; used as an analogy for RBF biases on subset spaces. "heat kernels"
- Hessian trace: The sum of the Hessian’s eigenvalues, used as a scalar measure of curvature or sharpness. "Hessian trace"
- Hessian-vector products: Operations computing the product of the Hessian with a vector without forming the full Hessian matrix. "Hessian-vector products"
- in-context learning: The ability of a model (e.g., an LLM) to learn from examples provided in the prompt at inference time without parameter updates. "in-context learning"
- influence functions: Analytical tools that estimate how infinitesimal changes to the training data affect model parameters or predictions. "influence functions"
- inverse Hessian: The matrix inverse of the Hessian of the loss; used in influence calculations to account for curvature. "inverse Hessian"
- Johnson-Lindenstrauss lemma: A result guaranteeing approximate distance preservation under random projections into lower dimensions. "Johnson-Lindenstrauss lemma"
- kernel matrix: The Gram matrix of pairwise kernel evaluations among samples used in kernel methods. "kernel matrix"
- kernel ridge regression: A regularized kernel method that fits functions in an RKHS by minimizing squared error with an L2 penalty. "kernel ridge regression"
- kernel surrogate models: Nonlinear surrogate models defined in an RKHS to capture higher-order interactions among tasks or data subsets. "kernel surrogate models"
- leave-one-out (LOO) retraining: A brute-force attribution approach that retrains the model after removing one task to measure its impact. "leave-one-out (LOO) retraining"
- LISSA: A stochastic algorithm for approximating the inverse Hessian via iterative series expansion. "LISSA"
- linear surrogate models: Additive surrogate models that approximate performance as a linear function of task inclusion, capturing first-order effects. "linear surrogate models"
- Meta-World MT10 benchmark: A suite of 10 robotic manipulation tasks used to evaluate multi-task and RL methods. "Meta-World MT10 benchmark"
- meta-gradient computation: Gradients of the training process itself (e.g., through optimization steps), used to assess data influence across training. "meta-gradient computation"
- multinomial logistic regression: A generalized linear model for multi-class classification using the softmax link. "multinomial logistic regression"
- multi-objective reinforcement learning: RL settings with multiple (possibly competing) reward signals; attribution examines task interactions. "multi-objective reinforcement learning"
- noise stability optimization (NSO): A regularization method that promotes parameter solutions stable to noise, reducing curvature. "noise stability optimization (NSO)"
- non-decomposable loss functions: Losses that cannot be expressed as a sum over independent example-level terms (e.g., ranking losses). "non-decomposable loss functions"
- Pearson correlations: A measure of linear association between two variables. "Pearson correlations"
- preference loss: A loss measuring alignment with pairwise preferences (e.g., in RLHF-style settings). "preference loss"
- Radial Basis Function (RBF) kernel: A kernel based on squared Euclidean distance that induces smooth, distance-sensitive similarity. "Radial Basis Function (RBF) kernel"
- representer theorem: A result stating that the minimizer in an RKHS admits a finite expansion in terms of training kernel evaluations. "representer theorem"
- Reproducing Kernel Hilbert Space (RKHS): A Hilbert space of functions where evaluation functionals are continuous and represented via a kernel. "Reproducing Kernel Hilbert Space (RKHS)"
- seed set expansion: A graph mining procedure that grows a community from a small set of seed nodes. "seed set expansion"
- sharpness-aware minimization (SAM): An optimizer that seeks parameters robust to perturbations by minimizing worst-case neighborhood loss. "sharpness-aware minimization (SAM)"
- soft actor-critic: An off-policy RL algorithm that maximizes a trade-off between reward and entropy to encourage exploration. "soft actor-critic"
- spectral norm: The largest singular value of a matrix, measuring its maximal amplification of vectors. "the spectral norm"
- Spearman correlation: A rank-based correlation measure assessing monotonic association between variables. "Spearman correlation ρ"
- Tikhonov regularization: L2 regularization applied in linear/kernel regression to control model complexity and ill-posedness. "Tikhonov regularization"
- TracIn: A trajectory-based influence method that sums gradient similarity between training and test points across training steps. "TracIn"
- Trak: A retraining-free approximation of datamodels using random projections and one-step Newton updates. "Trak"
- universal expressivity: The capability of a function class (e.g., RBF kernels) to approximate a wide range of functions on a domain. "universal expressivity"
Collections
Sign up for free to add this paper to one or more collections.

