- The paper introduces Modular Gradient Surgery, a novel method that locally resolves gradient conflicts in transformers for multi-domain RL.
- It demonstrates superior performance improvements across math, chat, and instruction tasks compared to conventional training methods.
- Empirical results reveal consistent gains with up to 4.5 point improvements, emphasizing the method’s scalability and module-specific benefits.
Modular Gradient Surgery for Multi-Domain Reasoning Model Optimization
Introduction
Recent advances in Large Reasoning Models (LRMs) have been driven by Reinforcement Learning (RL) techniques, particularly RL with Verifiable Rewards (RLVR), which has substantially improved open-ended and verifiable reasoning abilities across domains such as mathematics, code synthesis, chat, and instruction following. However, extending these gains to a general-purpose LRM that consistently performs well on heterogeneous domains remains nontrivial due to domain-specific reward structures and conflicting optimization objectives. This paper systematically analyzes sequential and mixed RL training paradigms, identifies quantifiable forms of cross-domain interference—mode interference, catastrophic forgetting, and gradient conflicts—and introduces Modular Gradient Surgery (MGS), a gradient-level conflict resolution algorithm at the modular granularity of transformers.
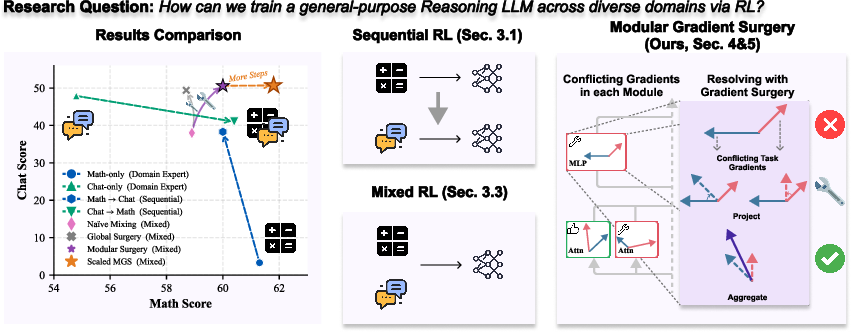
Figure 1: Modular Gradient Surgery (MGS) outperforms naive multi-domain RL by resolving local gradient conflicts, achieving state-of-the-art balanced capability across math, chat, and instruction tasks.
Experimental Framework and Failure Modes in Multi-Domain RL
Experimental Setup
Experiments utilize Qwen-2.5-7B and Llama-3.1-8B backbones over three representative domains: mathematics, open-ended chat, and instruction following. Each domain incorporates domain-specific RLVR or model-based reward signals, and evaluation is conducted across in-domain and generalization benchmarks.
Sequential RL Training: Forgetting and Rigidity
Sequential RL, where domains are optimized in succession, is shown to suffer from two detrimental behaviors:
- Forgetting: Training on a second domain degrades previously acquired competency (catastrophic interference).
- Rigidity: Prior optimization on one domain impedes learning efficiency on subsequent tasks, often due to reduced policy entropy inhibiting exploration.
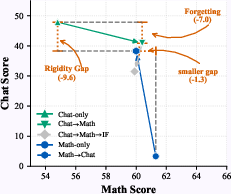
Figure 2: Sequential RL demonstrates severe forgetting and rigidity effects, limiting cross-domain transfer.
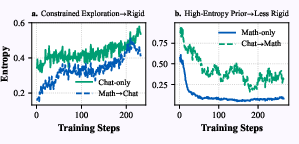
Figure 3: Entropy dynamics illustrate rigidity, with Math-first training constraining response diversity in chat tasks.
Empirical results show significant asymmetric degradation; Chat→Math preserves math skill better than Math→Chat preserves chat ability. The sequencing of domains significantly impacts the resultant Pareto frontier, and entropy analysis confirms that initial training on high-entropy tasks best supports subsequent structured learning.
Mixed RL integrates batches from multiple domains, applying gradients from all tasks in each step, which induces persistent gradient conflicts.
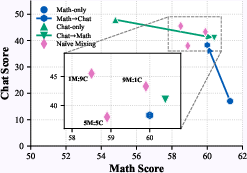
Figure 4: Data mixing ratios reveal Math performance scaling monotonically with math data, but chat performance exhibits complex non-monotonic correlation.
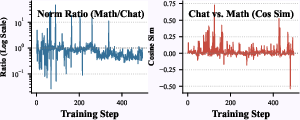
Figure 5: Gradient cosine similarity and norm ratios highlight pronounced conflicts between math and chat gradients during training.
Adjusting mixing ratios yields limited improvements. Even heavily task-skewed batches do not match single-domain expert models, substantiating that mere batch proportionality cannot eliminate interference. The negative cosine similarity between gradients for different domains confirms destructive gradient interactions and motivates algorithmic interventions.
Modular Gradient Surgery: Algorithmic Advances
Motivation and Mechanism
Transformer models are highly modular; distinct layers and blocks often specialize in different computational functions. Standard global gradient manipulation may be overly conservative or ineffective due to non-uniform conflict localization. MGS builds upon PCGrad [yu2020gradient] but applies projection operations independently within each detected module (attention, MLP, layer normalization).
By partitioning model parameters and resolving conflicts locally where negative gradient interactions are detected, MGS preserves beneficial updates while suppressing incompatible directions only in affected subspaces.
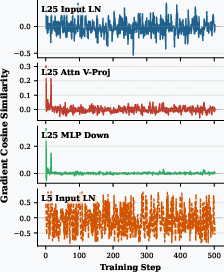
Figure 6: Modular gradient cosine similarity analysis reveals module-specific conflict patterns, underscoring the necessity of local interventions.
Empirical Validation
MGS consistently outperforms baseline model merging, normalized advantage normalization, global gradient surgery (GGS), and naive mixing across all evaluated multi-domain reasoning metrics.
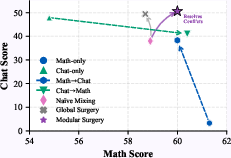
Figure 7: MGS delivers the best averaged performance in both balanced math and chat scores, outperforming global surgery and naive approaches, even surpassing single-task baselines on chat.
Key numerical results include 4.3/4.5 point average improvements for Llama and Qwen over standard multi-task RL, with peak scores achieved in all principal domains. Notably, global gradient surgery is less effective than modular surgery, as conflicts existing only in specialized modules unnecessarily constrain optimization of the entire parameter space.
Scalability and Mechanistic Analysis
Multi-Task and Prolonged Training Scalability
MGS benefits increase with expanded domain inclusion and longer training budgets, maintaining robust performance gains in settings with three or more domains and scaling positively with additional epochs.
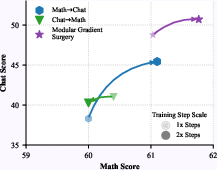
Figure 8: Scaling training steps further enhances MGS performance while sequential methods plateau or regress due to compounding interference.
Ablation and Module Sensitivity
Ablation studies reveal differential module importance:
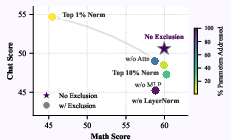
Figure 9: Exclusion of LayerNorm, Attention, or MLP modules from MGS impacts capabilities variably; LayerNorm is critical for both math and chat, while MLP exclusion degrades chat disproportionately.
Applying MGS only to top-norm modules affects chat but is insufficient for math, which requires distributed coherence across model modules.
Practical and Theoretical Implications
MGS establishes a principled framework for efficient multi-domain RL post-training of LRMs, leveraging the modular architecture of transformers for fine-grained conflict resolution. The approach eliminates the necessity for complex domain scheduling or reward engineering pipelines, enabling parallelized, compute-efficient multi-task training through FSDP and similar high-performance infrastructure. The clarity of modular interference loci expands interpretability of RL dynamics, informing future research on targeted adaptation, unlearning, LLM safety, and agentic system construction.
Future Directions
Potential extensions include exploring alternative heuristics for module selection (beyond gradient norm magnitude), refining task-to-module attribution, and adapting modular gradient manipulation for broader settings (vision-language, multimodal, supervised, or offline RL). Integrating MGS with advanced reward modeling and distillation protocols could further propel general-purpose reasoning models towards higher reliability and adaptability.
Conclusion
This work rigorously diagnoses multi-domain RL interference in language reasoning models and introduces Modular Gradient Surgery—a scalable, transformer-aware gradient conflict resolution method. MGS surpasses global projection and conventional mixing strategies, advancing the empirical and conceptual frontier for general-purpose reasoning RL post-training. These results motivate continued development of modular optimization schemas for dynamically heterogeneous learning objectives.

