Decoding Speech Envelopes from Electroencephalogram with a Contrastive Pearson Correlation Coefficient Loss
Abstract: Recent advances in reconstructing speech envelopes from Electroencephalogram (EEG) signals have enabled continuous auditory attention decoding (AAD) in multi-speaker environments. Most Deep Neural Network (DNN)-based envelope reconstruction models are trained to maximize the Pearson correlation coefficients (PCC) between the attended envelope and the reconstructed envelope (attended PCC). While the difference between the attended PCC and the unattended PCC plays an essential role in auditory attention decoding, existing methods often focus on maximizing the attended PCC. We therefore propose a contrastive PCC loss which represents the difference between the attended PCC and the unattended PCC. The proposed approach is evaluated on three public EEG AAD datasets using four DNN architectures. Across many settings, the proposed objective improves envelope separability and AAD accuracy, while also revealing dataset- and architecture-dependent failure cases.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Decoding Speech Envelopes from EEG with a Contrastive PCC Loss — Explained Simply
What is this paper about?
This paper is about teaching computers to tell which person you’re listening to in a noisy room (like a busy party) by reading your brain waves. The researchers use EEG (electroencephalogram), which measures tiny electrical signals on your scalp, and try to reconstruct the “shape” of the sound you’re paying attention to. They then introduce a new way to train these systems so they can more clearly tell apart the voice you’re focusing on from the others.
What questions are the researchers asking?
In simple terms, the paper asks:
- Can we make brain-reading models better at telling which speaker you’re paying attention to?
- Is it better to train the model to not only match the “right” speaker but also to avoid matching the “wrong” speakers?
- Does this new training idea work across different datasets and different types of neural networks?
How did they do it? (Methods in everyday language)
Here’s the basic idea using everyday analogies:
- EEG as microphones for your brain: EEG sensors are like tiny microphones on your head that record the brain’s activity while you listen to two people talking at once.
- Speech envelope as the “outline” of sound: The “speech envelope” is the smooth outline of how loud or soft speech is over time—think of it as the wave’s outer shape rather than all the tiny details. If your brain activity rises and falls in sync with a speaker’s envelope, it suggests you’re attending to that speaker.
- Correlation as “how in-sync two lines move”: The Pearson correlation coefficient (PCC) measures how similarly two signals go up and down. A higher correlation between the model’s predicted envelope (from EEG) and a given speaker’s envelope means a better match.
- The usual way (old loss): maximize matching with the attended speaker Many models try to make the predicted envelope look as similar as possible to the attended speaker’s envelope. That’s like saying, “Match the right voice well.”
- The new idea (contrastive loss): increase the gap The authors argue it’s not enough to match the attended speaker well—you also need to make sure the prediction does NOT match the other (unattended) speakers. Their training target focuses on the difference:
ΔPCC = attended PCC − average unattended PCC
In other words: “Pull the right speaker closer and push the wrong speakers farther away.”
- Models and data:
- Three public datasets (KUL, DTU, KUL-AV-GC), all with two speakers in the listener’s environment.
- Four modern neural network models (two CNN-based and two Transformer-like) to make sure the idea wasn’t tied to just one architecture.
- Processing and training basics:
- EEG was cleaned (filtered to 1–32 Hz, artifacts like eye blinks reduced, and resampled to 128 Hz).
- Speech envelopes were extracted so they align with EEG.
- Models were trained and validated carefully so that no test data leaked into training.
- They evaluated performance using windows as short as 1 second and up to 10 seconds.
What did they find, and why does it matter?
The key findings are:
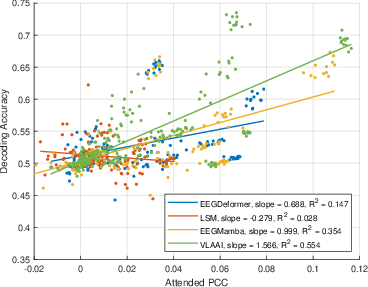
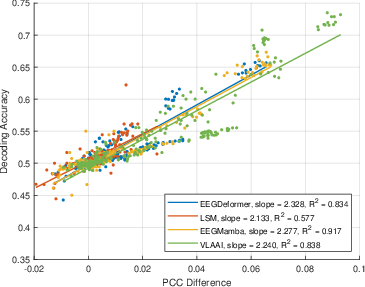
- The gap matters more than the match: They found that decoding accuracy (correctly identifying the attended speaker) is more strongly related to the gap between attended and unattended correlations (ΔPCC) than to the attended correlation alone. In short, “how much better you match the right voice than the wrong ones” predicts success better than “how well you match the right voice” by itself.
- The new contrastive loss often improves results:
- Higher decoding accuracy (more correct attention detections)
- Larger separation between the attended and unattended speakers (bigger ΔPCC)
- Longer time windows help: Improvements were often stronger when using longer EEG segments (like 10 seconds), giving the model more context.
- Not perfect in all cases: The new method didn’t help every model on every dataset. For example, in some model–dataset combinations (like one Transformer-like model on the DTU dataset), performance didn’t improve or even decreased. This shows that the benefit can depend on the data and the neural network used.
- How it improves: less confusion with the wrong speaker: The boost mainly comes from reducing the model’s similarity to the unattended speakers rather than just increasing similarity to the attended one. That means the method helps avoid “confusing” the distractors with the target.
Why is this important? (Implications)
- Better brain-guided hearing help: This kind of attention decoding could help future hearing aids or audio devices automatically turn up the person you’re listening to and turn down others—making it easier to follow a conversation in noisy places.
- Smarter training objectives: The paper shows that choosing the right training goal (loss function) can be just as important as fancy model designs. Focusing on separation (contrast) can directly improve the decision the system needs to make.
- Next steps:
- Making the contrastive training more robust across different recording conditions and languages.
- Improving performance on shorter time windows (for faster, real-time use).
- Combining architectural advances with better losses for even stronger results.
In summary, the paper introduces a simple but powerful idea: don’t just match the “right” speaker—also actively “unmatch” the wrong ones. This contrastive approach often leads to clearer, more reliable attention decoding from EEG, moving us closer to practical, brain-driven audio tools.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address:
- Generalization to multi-talker settings beyond two speakers remains untested; how does the contrastive PCC loss scale with 3–4+ concurrent talkers, and should the loss use mean, max (hard negative), or weighted negatives when N grows?
- Latency–accuracy trade-offs are underexplored: improvements are more pronounced at 10 s windows, but real-time AAD needs 0.25–2 s; what is the minimal window that retains gains, and how does performance degrade as latency is reduced?
- Subject generalization is unclear: the paper does not report subject-independent or cross-subject transfer; how well do models trained on some subjects generalize to unseen participants without calibration?
- Cross-dataset robustness is not evaluated (train on dataset A, test on B); can the proposed loss mitigate domain shift across languages, recording protocols, and experimental paradigms?
- Failure cases are not analyzed mechanistically (e.g., EEGMamba on DTU); what dataset factors (noise, narrative structure, attention compliance), architectural traits (state-space vs CNN), or preprocessing differences drive these failures?
- Only 64-channel cap EEG is considered; how does performance change with reduced channel counts, wearable layouts (ear-EEG, cEEGrid), or channel selection strategies?
- Real-time feasibility is unquantified: what are inference latency, throughput, and memory footprints for each architecture and loss on CPU/embedded hardware typical of hearing devices?
- The loss design space is only partially explored: do margin-based variants (e.g., hinge on ΔPCC), triplet losses, InfoNCE-style objectives, or Fisher z-transformed correlations improve stability and separability over the current mean-unattended PCC formulation?
- Degenerate anticorrelation solutions are discussed but not rigorously prevented or studied; would explicit constraints (e.g., margin on attended PCC, non-negativity regularizers, sign-consistency penalties) avoid trivial sign flips while retaining separability?
- Decision–objective alignment is incomplete: decoding decisions are based on PCC comparisons, but training does not optimize a classification surrogate (e.g., pairwise hinge/logistic on ΔPCC); does directly optimizing a decision-aware loss further improve AAD accuracy?
- Correlation computation details (e.g., time-lag optimization common in AAD) are not reported; does allowing a physiologically plausible lag window (e.g., 0–250 ms) for each PCC improve ΔPCC and accuracy under both losses?
- The acoustic target feature is fixed to a broadband envelope; do results hold for alternative targets (e.g., subband envelopes, mel-spectrograms, phonetic/semantic features), and how does the contrastive loss transfer across feature types?
- Envelope fidelity vs separability trade-off is unmeasured: contrastive training often lowers attended PCC; how does this affect downstream tasks requiring absolute envelope fidelity (e.g., speech reception threshold estimation)?
- Only two window lengths (1 s, 10 s) are tested; performance at intermediate windows (0.25, 0.5, 2, 5 s) and with overlapping/sliding windows remains unknown.
- The preprocessing pipeline is fixed; how sensitive are results to band-pass range, referencing (CAR vs mastoid), artifact handling (ICA/EOG), and resampling choices across datasets?
- No ablations on EEG–speech alignment and lag structure (e.g., causal vs non-causal context, temporal context width) are provided; what temporal receptive fields best support ΔPCC gains?
- Evaluation metrics are limited to accuracy and PCC; do ROC/AUC, calibration, decision consistency over time, and subject-level effect sizes corroborate the reported gains?
- Statistical testing details are incomplete (test type, unit of analysis, multiple-comparison correction); re-analysis with subject-level paired tests and corrections would strengthen claims of significance.
- Classic linear baselines (e.g., mTRF/linear decoder) are absent; benchmarking against strong linear baselines is needed to quantify the incremental benefit of both DNNs and the contrastive loss.
- Domain robustness to acoustic conditions (varying SNR, reverberation, competing talker characteristics) is not studied; does the contrastive objective confer noise robustness compared to PCC-only training?
- The audiovisual dataset (KUL-AV-GC) is used with audio-only inputs; how would incorporating visual cues (lip/gaze) interact with the contrastive objective, and does it enhance envelope separability?
- The number and nature of negatives are constrained by the dataset (one unattended talker); can augmenting negatives via mixing, distractor banks, or hard-negative mining improve training in two-talker corpora?
- Model training stability and reproducibility are underreported (random seeds, variance across runs, training curves); do ΔPCC models exhibit higher variance or mode collapse, and what regularizers mitigate this?
- Code and trained models are promised “upon acceptance”; immediate public release of code, exact data splits, seeds, and preprocessing scripts is needed for independent replication.
- Some equations contain typographical/formatting errors (e.g., accuracy definition, missing brackets), creating ambiguity in the exact objective and metric computation; a clarified mathematical specification and reference implementation are needed.
- Applicability to single-talker scenarios is undefined (ΔPCC denominator N−1=0); how should the loss be adapted for one-speaker settings or for variable N during training/inference?
- Interpretability is not explored; which channels, time-lags, or frequency bands drive ΔPCC improvements, and do learned patterns align with known neurophysiology of speech tracking?
- Potential label noise (imperfect attention) is unaddressed; can robust objectives (e.g., noise-tolerant losses, curriculum learning) stabilize training when attention compliance varies?
- Cross-session/day generalization and session adaptation are not evaluated; how much recalibration is required to maintain ΔPCC gains across sessions for the same subject?
Practical Applications
Practical Applications of “Decoding Speech Envelopes from EEG with a Contrastive PCC Loss”
This paper introduces a contrastive Pearson correlation coefficient (ΔPCC) loss that explicitly maximizes the separability between attended and unattended speech envelopes reconstructed from EEG, leading to improved auditory attention decoding (AAD) in many settings. Below are actionable applications that leverage the findings, methods, and workflow choices reported, organized by deployment horizon and linked to relevant sectors.
Immediate Applications
- EEG speech-envelope reconstruction research toolchain upgrades
- Sectors: academia, software/ML
- What: Use the contrastive ΔPCC loss as a drop-in replacement for standard PCC loss when training EEG-to-envelope regression models (e.g., VLAAI, LSM-CNN, Mamba/Transformer-like models).
- Tools/workflows:
- Implement ΔPCC loss in PyTorch/TF; integrate into existing training scripts alongside AdamW, early stopping, and leave-one-trial-out CV.
- Add ΔPCC as a validation/early-stopping metric; report attended PCC, unattended PCC, and ΔPCC during model selection.
- Assumptions/dependencies: Requires access to attended and unattended reference envelopes during training; improvements are model- and dataset-dependent and typically more pronounced on longer (≈10 s) decision windows.
- Improved benchmarking and evaluation protocols for AAD
- Sectors: academia, standards/benchmarking consortia
- What: Adopt ΔPCC as a primary development metric given its stronger correlation with decoding accuracy than attended PCC alone; include ΔPCC in ablations and cross-dataset comparisons.
- Tools/workflows: Extend existing EEG-AAD leaderboards/scripts to log ΔPCC; perform paired hypothesis testing on ΔPCC alongside accuracy.
- Assumptions/dependencies: Public datasets must include multi-talker speech references; ensure consistent preprocessing (1–32 Hz band-pass, ICA/EOG artifact mitigation, 128 Hz resampling).
- Lab prototypes for neuro-steered target speaker extraction (TSE)
- Sectors: healthcare (hearing research), audio/software
- What: Use reconstructed envelope + ΔPCC-based discriminability to select the attended speaker among candidate streams and steer a TSE/beamforming module.
- Tools/workflows:
- Pipeline: EEG → envelope reconstruction → correlation to candidate envelopes → select target → apply TSE (e.g., M3ANet, TFGA-Net) to enhance the attended stream.
- Real-time-capable prototypes for 5–10 s decision windows in controlled labs.
- Assumptions/dependencies: Requires access to separated candidate speech envelopes (microphone array + separation front-end); EEG-audio synchronization; performance degrades with short windows and uncontrolled artifacts.
- Clinical and translational research assessments
- Sectors: healthcare (audiology, neuroengineering)
- What: Enhance research-grade tools for EEG-based speech reception threshold (SRT) estimation and attention-tracking tests by leveraging ΔPCC to increase separability and decision reliability.
- Tools/workflows: Integrate ΔPCC-trained models into lab protocols for assessing hearing-aid candidacy or attentional function; analyze longer segments for higher accuracy.
- Assumptions/dependencies: Not yet validated for clinical-grade reliability; 64-channel EEG setups (or carefully designed ear-EEG substitutes) and artifact control are needed.
- Cognitive neuroscience experiments of selective attention
- Sectors: academia (cognitive neuroscience, auditory neuroscience)
- What: Use ΔPCC-trained decoders as more sensitive probes of attended vs. unattended tracking in multi-talker paradigms.
- Tools/workflows: Leverage the unified preprocessing pipeline and leave-one-trial-out CV to reduce trial fingerprinting; analyze ΔPCC-time courses in attention switching tasks.
- Assumptions/dependencies: Gains vary by language/protocol; requires careful counterbalancing and dataset-specific tuning.
- Software components for AAD development
- Sectors: software, ML tooling
- What: Release/consume an open-source module that implements ΔPCC loss and example configs for VLAAI/LSM/Transformer-like decoders with standardized preprocessing.
- Tools/products: “EEG-AAD ΔPCC” package (loss, metrics, training recipe, scripts for KUL/DTU/KUL-AV-GC datasets).
- Assumptions/dependencies: Community adoption and maintenance; reproducible data access and consistent license compliance.
Long-Term Applications
- Neuro-steered hearing aids and hearables
- Sectors: healthcare/medical devices, consumer electronics
- What: Commercial devices that use EEG (ear-EEG/dry electrodes) to steer noise reduction and TSE toward the attended talker in real-world “cocktail party” environments.
- Tools/products: Embedded AAD module using ΔPCC-trained models + on-device beamforming/TSE; calibration app to optimize per-user performance; low-latency inference optimized for 1–2 s decisions.
- Assumptions/dependencies: Miniaturized, comfortable EEG hardware; robust artifact suppression with motion; on-device compute/energy budget; regulatory approval; subject-specific or robust subject-independent generalization; robust access to candidate speech streams.
- Attention-aware AR/VR audio mixing
- Sectors: AR/VR, gaming, media
- What: Headsets adjust audio mix to the talker or source the user attends to (e.g., NPC dialogs, meeting avatars), guided by EEG-driven envelope reconstruction and ΔPCC discrimination.
- Tools/products: SDKs for AR/VR engines to consume attention signals and modulate audio rendering; integration with spatial audio and source separation.
- Assumptions/dependencies: Integrated EEG sensors in HMDs; latency constraints (<1–2 s) demand further model optimization; privacy-by-design for neural signals.
- Intelligent teleconferencing and assistive communication systems
- Sectors: enterprise collaboration, accessibility tech
- What: Optional neuro-steering for users with hearing difficulties to focus on the desired speaker in hybrid meetings; attention-driven transcription/closed captioning of the attended stream.
- Tools/products: Meeting platforms offering an assistive mode that ingests a user’s EEG from certified devices to enhance a selected audio channel.
- Assumptions/dependencies: Strong privacy and consent frameworks; integration with multi-speaker separation; user willingness to wear sensors; institutional accessibility policies.
- In-vehicle attention-driven voice interaction
- Sectors: automotive, mobility
- What: Voice assistants or intercoms that prioritize the driver’s attended talker (passenger, call participant) amid cabin noise.
- Tools/products: Ear-EEG-integrated headrests/earbuds; fusion with beamforming and source separation.
- Assumptions/dependencies: Motion and EMG artifacts; safety and regulatory approvals; low-latency performance with short decision windows.
- Clinical decision support and digital biomarkers
- Sectors: healthcare (neurology, psychiatry, audiology)
- What: ΔPCC-derived measures as candidate biomarkers for attention deficits, auditory scene analysis impairments, or hearing-aid benefit prediction.
- Tools/workflows: Standardized tasks that quantify ΔPCC under controlled conditions; longitudinal monitoring.
- Assumptions/dependencies: Large normative datasets; sensitivity/specificity validation; clinical utility and reimbursement pathways.
- Education and training analytics (ethically governed)
- Sectors: education, edtech
- What: Research-led pilots that explore whether attention tracking improves lecture capture personalization or language-learning in noisy environments.
- Tools/products: Instructor tools to adapt audio content mix to learner attention (opt-in only).
- Assumptions/dependencies: Strong ethical oversight; privacy & consent; likely limited to specialized populations and research contexts.
- Policy, standards, and governance for neural audio systems
- Sectors: policy/regulation, standardization bodies
- What: Develop standards for AAD evaluation (including ΔPCC reporting), neural data security, consent, and safe human-device interaction in neuro-steered audio products.
- Tools/workflows: Consensus guidelines for datasets, metrics (ΔPCC and accuracy), and minimum performance thresholds; neurodata privacy certifications.
- Assumptions/dependencies: Multi-stakeholder collaboration; harmonization with medical-device and consumer privacy regulations.
- Cross-modality generalization and minimal-sensor deployments
- Sectors: healthcare, consumer electronics, research
- What: Extend ΔPCC-loss training to fNIRS/MEG/ear-EEG or sparse EEG arrays for deployable, comfortable systems.
- Tools/workflows: Domain adaptation, self-supervised pretraining, and robustness to artifacts; architecture exploration for short-window performance.
- Assumptions/dependencies: More research on signal quality trade-offs; new datasets with sparse sensors; optimized hardware-software co-design.
Notes on global assumptions and dependencies across applications:
- Access to candidate speech envelopes: AAD decisions require reference or separated audio streams for correlation; robust source separation/beamforming front-ends are a prerequisite.
- Window-length/latency trade-off: Reported gains are stronger at ~10 s windows; real-world use will need improved performance at shorter windows (≤1–2 s).
- Dataset and architecture sensitivity: Benefits are not universal; careful model selection, hyperparameter tuning, and possibly subject-specific calibration may be needed.
- Signal quality and artifacts: Motion/EMG/ocular artifacts and hardware constraints (dry vs. wet electrodes, sparse channels) materially affect performance.
- Ethics and privacy: Handling neural data mandates consent, minimization, secure processing, and transparent user control, especially outside research settings.
Glossary
- Attended PCC: The Pearson correlation between the reconstructed envelope and the attended speech envelope. "Let the attended PCC be the Pearson correlation coefficient (PCC) between the attended envelope and the reconstructed envelope:"
- Auditory attention decoding (AAD): Inferring which speech stream a listener attends to from neural signals. "Recent advances in reconstructing speech envelopes from Electroencephalogram (EEG) signals have enabled continuous auditory attention decoding (AAD) in multi-speaker environments."
- Auditory scene: An environment with multiple concurrent sound sources/speakers. "where denotes the number of concurrent speakers in the auditory scene."
- Auditory selective attention: The neural focusing on a target sound source while suppressing others. "auditory selective attention enhances cortical tracking of the attended speech envelope"
- Audiovisual spatial-attention paradigm: An experiment that uses both audio and visual cues to direct spatial attention. "The KUL-AV-GC dataset corresponds to the audiovisual spatial-attention paradigm described in \cite{rotaru2024we}."
- Azimuth: The angular direction of a sound source around the listener’s head. "presented simultaneously from azimuth."
- Band-pass filtered: Signal processing that retains only a specific frequency band. "EEG signals were first band-pass filtered between 1 and 32~Hz to retain low-frequency components associated with cortical speech tracking."
- BioSemi ActiveTwo system: A multi-channel EEG acquisition hardware platform. "For these datasets, EEG was recorded using a 64-channel BioSemi ActiveTwo system."
- Brain-assisted target speaker extraction: Using brain signals to aid in isolating the attended speaker from mixtures. "EEG-based decoding has gained traction for AAD and brain-assisted target speaker extraction due to its noninvasiveness and practical setup requirements"
- Contrastive PCC loss: A loss that increases the difference between attended and unattended correlations. "We therefore propose a contrastive PCC loss which represents the difference between the attended PCC and the unattended PCC."
- Cortical tracking: The brain’s temporal alignment of neural activity with rhythmic features of speech. "auditory selective attention enhances cortical tracking of the attended speech envelope"
- Electroencephalogram (EEG): Noninvasive measurement of scalp electrical activity reflecting brain signals. "Recent advances in reconstructing speech envelopes from Electroencephalogram (EEG) signals"
- Electrooculogram (EOG) regression: A method to remove eye-movement artifacts from EEG using EOG signals. "Ocular and muscular artifacts were mitigated using Independent Component Analysis (ICA) and electrooculogram (EOG) regression when available, and bad channels were removed and interpolated."
- Envelope reconstruction: Predicting the amplitude envelope of speech from EEG. "Most DNN-based envelope reconstruction models aim to maximize the Pearson correlation coefficient (PCC) between the attended envelope and the reconstructed envelope"
- ERB gammatone filterbank: An auditory-inspired filterbank spaced by Equivalent Rectangular Bandwidths. "Speech envelopes for all talkers were extracted from the audio waveform using an ERB gammatone filterbank with 17 subbands spanning the frequency range from 50 to 5000~Hz."
- EEG-Deformer: A hybrid CNN–Transformer architecture tailored for EEG tasks. "EEG-Deformer \cite{ding2024eeg} uses a hybrid CNNâTransformer architecture in which shallow and deep representations are produced with fine- and coarse-grain feature extractors."
- EEGMamba: A state-space-model-based EEG architecture referenced among compared models. "Each of the four modelsâVLAAI, LSM, EEGMamba, and EEGDeformerâwas trained independently"
- Head-related impulse responses: Individualized acoustic filters capturing head/ear effects on sound. "two spatially separated speech streams rendered at using individualized head-related impulse responses."
- Independent Component Analysis (ICA): A blind-source-separation method for isolating artifacts and neural sources. "Ocular and muscular artifacts were mitigated using Independent Component Analysis (ICA)"
- Leave-one-trial-out cross-validation: A validation scheme where each trial is held out once as the test split. "All models were trained using a four fold leave-one-trial-out cross-validation scheme."
- LSM-CNN: A CNN that learns spatial mappings of EEG channels to model spatial relationships. "LSM-CNN \cite{zhang2023learnable} introduces a learnable spatial-mapping layer that converts multichannel EEG signal from 2-D to 3-D layout (two channel dimensions), enabling the representation of channel spatial locations and adjacency."
- Mel-spectrogram: A time–frequency representation with frequency scaled on the mel perceptual scale. "SSM2Mel combines selective state-space Mamba blocks with multi-head self-attention, enabling efficient long-range EEG modeling for mel-spectrogram reconstruction."
- PCC difference (ΔPCC): The difference between attended and unattended correlations used as a discriminative metric. "PCC difference between the attended PCC and the unattended PCC ()."
- Pearson correlation coefficient (PCC): A measure of linear correlation between two signals. "The PCC between two signals and is defined as"
- PCC loss: A training objective that maximizes the attended correlation by minimizing negative PCC. "The PCC loss is defined as"
- Power-law nonlinearity: A nonlinear transformation using a fixed exponent to compress envelope amplitudes. "The subband envelopes were obtained by magnitude extraction followed by a power-law nonlinearity with an exponent of 0.6"
- Selective state-space Mamba blocks: Efficient sequence modeling modules based on state-space models. "SSM2Mel combines selective state-space Mamba blocks with multi-head self-attention"
- Speech envelope: The slow-varying amplitude contour of speech over time. "Recent advances in reconstructing speech envelopes from Electroencephalogram (EEG) signals"
- SSM2Mel: A model that maps EEG to mel-spectrograms using state-space and attention mechanisms. "SSM2Mel \cite{fan2025ssm2mel} combines selective state-space Mamba blocks with multi-head self-attention, enabling efficient long-range EEG modeling for mel-spectrogram reconstruction."
- Trial fingerprints: Idiosyncratic patterns in trials that models could overfit to instead of task-relevant features. "This strategy ensured that no training, validation, or test segments originated from the same trial and prevented the model from utilizing trial fingerprints to obtain overestimated decoding results."
- Unattended PCC: The correlation between the reconstruction and non-attended speech envelopes. "While the difference between the attended PCC and the unattended PCC plays an essential role in auditory attention decoding"
- VLAAI: A CNN-based EEG-to-envelope decoder architecture. "VLAAI \cite{accou2023decoding} predicts continuous attended speech envelopes using stacked 1-D convolutions with skip connections."
Collections
Sign up for free to add this paper to one or more collections.

