- The paper establishes precise power-law relationships between data/compute scale and ML-OPF performance metrics, enabling quantifiable resource allocation.
- It demonstrates divergent scaling trends for prediction accuracy versus physical feasibility, highlighting limitations of conventional DNNs compared to PINNs.
- The study verifies consistent scaling across various IEEE grid sizes, providing design insights for optimal neural architecture in OPF tasks.
Scaling Laws of Machine Learning for Optimal Power Flow
Introduction
This paper systematically interrogates how deep learning models for optimal power flow (OPF), both DNNs and PINNs, scale with respect to training dataset size and computational resources. While ML-based approaches have rapidly accelerated real-time OPF by learning mappings from grid states to generator setpoints, practical deployment is impeded by a lack of quantitative guidance regarding minimal data requirements and the optimal allocation of computational resources. This work closes a critical gap by establishing precise power-law relationships between OPF performance metrics (prediction accuracy, constraint violations, and inference latency) and both data/compute scales across a variety of power system test cases.
Power Law Scaling in Data and Compute
Empirical evidence is provided for power-law scaling of ML-OPF prediction accuracy with both data and training compute. For the ACOPF task on the 118-bus IEEE system, the MAE for active power generation predictions follows MAEPg(D)=1.2D−0.39 (R2=0.99) relative to data size (Figure 1) and MAEPg(C)=2.1C−0.25 (R2=0.59) for total compute expenditure (Figure 2). Comparable power-law exponents are found for voltage predictions and, to a lesser degree, for constraint violation metrics.
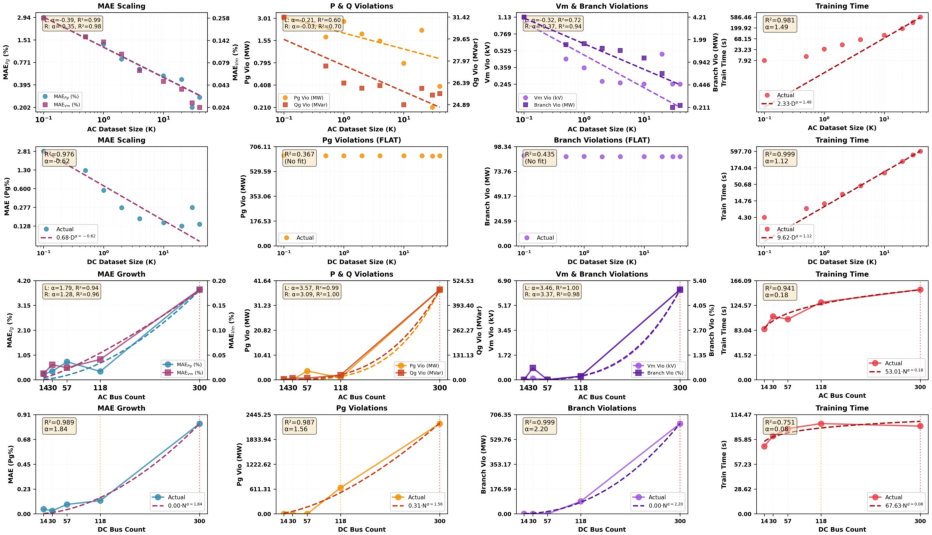
Figure 1: Data and system scaling for ML-based OPF on IEEE test systems, revealing consistent power-law decay of MAE with increasing training samples and system size.
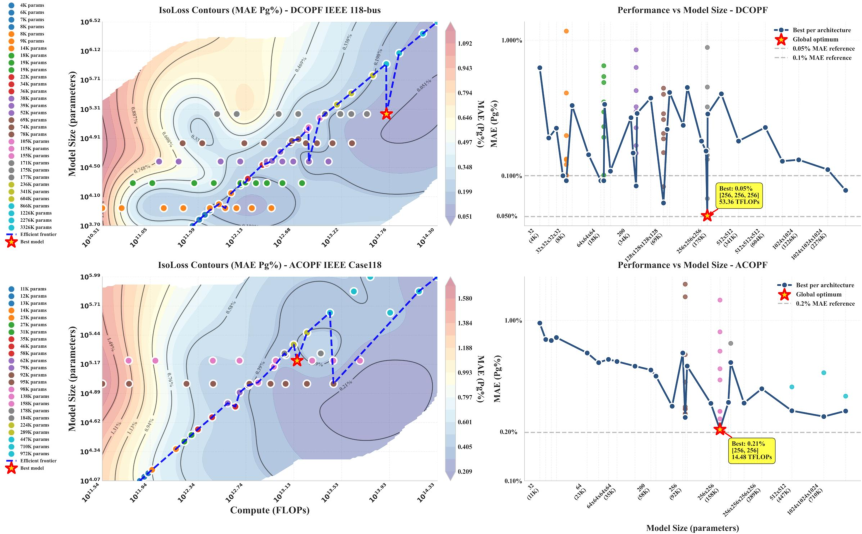
Figure 2: Iso-loss contours for compute scaling: prediction error (MAE for Pg) as a function of FLOPs and model parameters, highlighting the efficiency frontier and best observed points.
The predictability of these scaling trends has several core implications. First, given practical limitations in executing AC power flow (ACPF) simulations for data generation, pipeline designers can now directly estimate the marginal accuracy improvements obtainable for a given data collection effort. Second, compute scaling laws indicate not only the expected error decay rate under increasing model/training budgets, but also characterize the onset of diminishing returns.
Accuracy versus Feasibility: Divergent Scaling and Structural Bottlenecks
A major contribution of the paper is the explicit demonstration that prediction accuracy and physical feasibility scale at different rates. While MAE decays rapidly as a function of data and compute, constraint violation reduction—especially for reactive power and some branch constraints in ACOPF—exhibits substantially slower improvement and weaker scaling exponents. For DCOPF, some constraints become fundamentally unsatisfiable due to limitations of the data-driven surrogate—no amount of data or compute achieves physical feasibility, indicating structural model mismatch.
The DNNs trained purely on MSE loss prioritize regression fit, improving forecasts while often leaving constraint violations nearly intact (e.g., DCOPF branch and generator limit violations remain flat as dataset size grows). In contrast, physics-informed NNs (PINNs) with explicit loss terms for KKT conditions and feasibility constraints achieve much lower physical violations but at the expense of higher MAE. The research quantitatively places both paradigms on a Pareto front, with neither dominating across all metrics.
System and Architecture Scaling
The analysis further extends to multiple IEEE grid sizes (14, 30, 57, 118, and 300 buses), verifying that the empirical power laws persist across system complexities. Importantly, the optimal neural architecture—depth and width under a fixed compute budget—shifts with OPF type and system regime. In ACOPF, shallower wider nets outperform deeper models for fixed FLOPs, attributed to the polynomial structure of AC power flow equations being well-approximated by shallow geometry. This finding contradicts the common intuition that deeper architectures are always preferable for complex engineering tasks and provides design guidance for OPF-specific neural network selection.
Practical Implications and Theoretical Significance
The existence of steep power-law scaling (exponents ∣α∣≫0.05 typical in NLP) implies that ML-OPF has yet to hit fundamental bottlenecks found in other, unconstrained ML domains—substantial improvements are available through responsible resource increase. However, the slow scaling for feasibility highlights the intrinsic challenge in translating accurate forecasts into operationally admissible solutions within the physics and safety envelope of power grids.
This quantification enables scenario-driven resource allocation: stakeholders can now predict the effects of increased compute or data before investing in expensive simulation or hardware acquisition. Furthermore, the identification of flat or poor scaling for feasibility in DCOPF implies a need for further architectural innovation or hybridization with domain optimization solvers if strict constraint enforcement is required.
Outlook and Future Directions
The results suggest several theoretical and applied avenues:
- Architecture search for feasibility-optimal models: Investigating losses and regularization mechanisms that effectively bridge the MAE/violation trade-off could yield architectures on the true Pareto frontier.
- Scaling studies for more general OPF variants: Generalizing discovered laws to multi-period and stochastic OPF, or incorporating topology optimization and security constraints.
- Efficient data- and compute-sensitive training protocols: Leveraging the scaling curves to design automated pipelines that stop training or data collection at the optimal point for a given accuracy or feasibility threshold.
Conclusion
This work establishes the first empirical scaling laws for neural network surrogates in both DC and AC optimal power flow, offering power system operators and ML practitioners a foundation for principled resource allocation in model development. While prediction accuracy can be driven down rapidly by dataset and compute expansion, feasible OPF solutions in practice require new advances to overcome the slow improvement in physical constraint satisfaction. These findings both clarify immediate ML-OPF design and training questions and motivate future research into constraint-compliant deep learning for complex cyber-physical systems.