Unified Embodied VLM Reasoning with Robotic Action via Autoregressive Discretized Pre-training
Abstract: General-purpose robotic systems operating in open-world environments must achieve both broad generalization and high-precision action execution, a combination that remains challenging for existing Vision-Language-Action (VLA) models. While large Vision-LLMs (VLMs) improve semantic generalization, insufficient embodied reasoning leads to brittle behavior, and conversely, strong reasoning alone is inadequate without precise control. To provide a decoupled and quantitative assessment of this bottleneck, we introduce Embodied Reasoning Intelligence Quotient (ERIQ), a large-scale embodied reasoning benchmark in robotic manipulation, comprising 6K+ question-answer pairs across four reasoning dimensions. By decoupling reasoning from execution, ERIQ enables systematic evaluation and reveals a strong positive correlation between embodied reasoning capability and end-to-end VLA generalization. To bridge the gap from reasoning to precise execution, we propose FACT, a flow-matching-based action tokenizer that converts continuous control into discrete sequences while preserving high-fidelity trajectory reconstruction. The resulting GenieReasoner jointly optimizes reasoning and action in a unified space, outperforming both continuous-action and prior discrete-action baselines in real-world tasks. Together, ERIQ and FACT provide a principled framework for diagnosing and overcoming the reasoning-precision trade-off, advancing robust, general-purpose robotic manipulation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching robots to both “think” and “act” well in the real world. The authors want robots that can understand complex instructions and situations (good reasoning) and also move their arms and tools very precisely (accurate actions). Today’s Vision-Language-Action (VLA) models often do one of these well but not both. This paper introduces a new way to measure a robot’s reasoning and a new method to turn robot movements into “tokens” that help the robot learn precise actions without losing its reasoning skills. Together, these ideas create a system called GenieReasoner that gets better results in real robot tasks.
What are the main goals?
- Measure a robot’s “embodied reasoning” (how well it understands space, plans, checks for mistakes, and understands human intent) separately from its physical actions.
- Show that better reasoning helps robots generalize to new tasks and places.
- Create a new action “tokenizer” (called FACT) that converts smooth, continuous robot motions into compact, discrete tokens and back, preserving precision.
- Build a unified model (GenieReasoner) that learns reasoning and actions together without one hurting the other.
- Test the model on real-world robots and prove it beats existing methods.
How did they do it?
ERIQ: A benchmark to test robot reasoning
It’s hard to tell why a robot fails: did it misunderstand the task, or did it move badly? To solve this, the authors made ERIQ (Embodied Reasoning Intelligence Quotient), a large test set with over 6,000 question–answer pairs. Each question is based on real robot videos and scenes, and answers are multiple choice or yes/no, so scoring is clear and fair. ERIQ focuses on four areas:
- Spatial perception and grounding: Can the robot understand the scene and find the right objects and their positions?
- Planning and monitoring: Can it plan steps and recognize if a task is done?
- Error detection and recovery: Can it spot mistakes (like slips) and suggest fixes?
- Human intent understanding: Can it guess what a human is trying to do and plan to cooperate?
By testing reasoning separately, ERIQ lets researchers diagnose whether a problem is about thinking or about moving.
FACT: Turning actions into tokens without losing precision
Robots usually need smooth, continuous control signals (like “move the arm 2.3 cm”), but LLMs work best with discrete tokens (like words). Many methods that discretize actions either lose precision or become unstable. The authors propose FACT (Flow-matching Action Tokenizer):
- Encoder (discretization): It compresses a chunk of actions into a small set of tokens, similar to how a song can be compressed into a file format. Think of these tokens like Lego pieces that describe the motion.
- Decoder (flow-matching): It uses a method called “flow matching” to turn those tokens back into smooth, high-fidelity motions. Imagine starting with random noise and “flowing” it toward the target motion, step by step, guided by the tokens. This preserves the fine details needed for precise movement.
In everyday terms: FACT is like writing a recipe with short, simple steps (tokens), then having a skilled chef turn those steps into exact cooking motions (precise control) without losing quality.
GenieReasoner: Learning reasoning and actions together
With ERIQ and FACT, the authors train an autoregressive transformer (a kind of large AI model) that:
- Takes in images and instructions.
- Predicts both the high-level reasoning steps and the compact action tokens.
- Uses the FACT decoder to turn tokens into real robot movements.
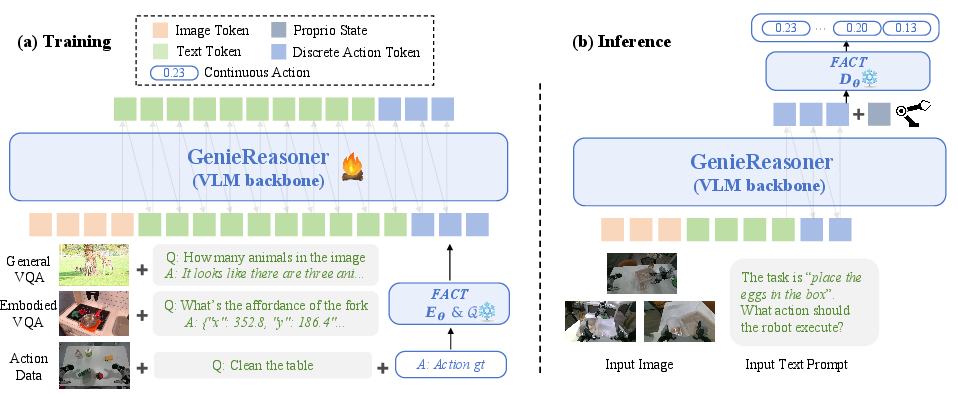
They use a three-stage training process:
- Train FACT to tokenize and reconstruct actions well.
- Jointly train the model on general vision-language data (to keep broad knowledge), embodied VQA (to improve robot-specific reasoning), and tokenized action data.
- Post-train on task-specific mixes of embodied VQA and action data, so the model stays aligned and doesn’t forget its reasoning.
What did they find and why does it matter?
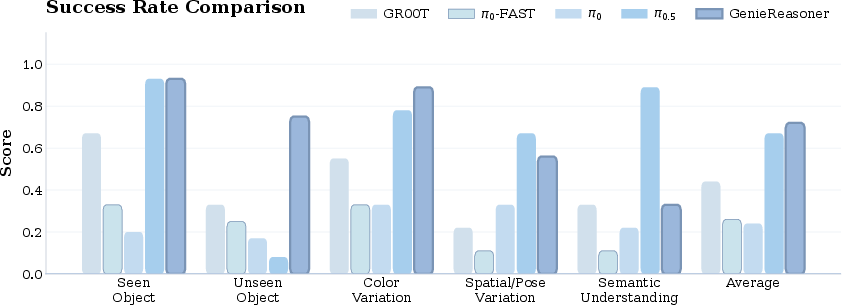
- ERIQ reveals a strong positive correlation: Models that score higher on reasoning tend to perform better in real robot tasks. This supports the idea that good “thinking” improves generalization.
- GenieReasoner improves embodied reasoning: The paper reports a large accuracy gain on ERIQ (about 41% improvement in the figure summary) and strong scores across its four dimensions, especially in understanding actions and human intent.
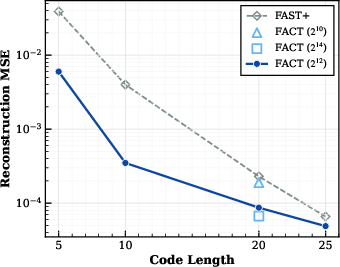
- FACT achieves high-precision control: Compared to prior discrete tokenizers like FAST, FACT reconstructs actions with lower error (better fidelity) at the same code lengths. It also avoids instability issues common in variable-length schemes.
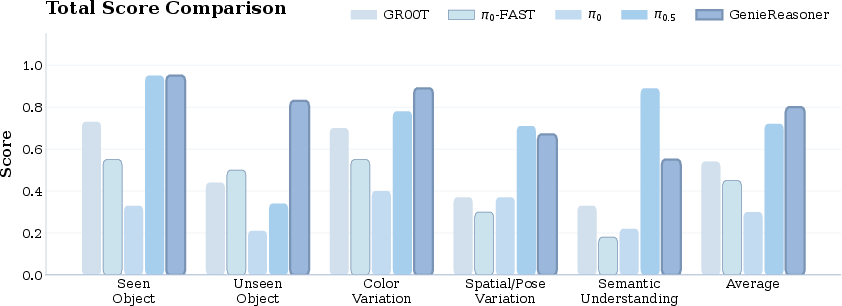
- Unified training beats baselines: GenieReasoner outperforms both continuous-action models (like π0.5) and discrete-action models (like π0-FAST) in real-world robot manipulation. It balances strong reasoning with precise movement.
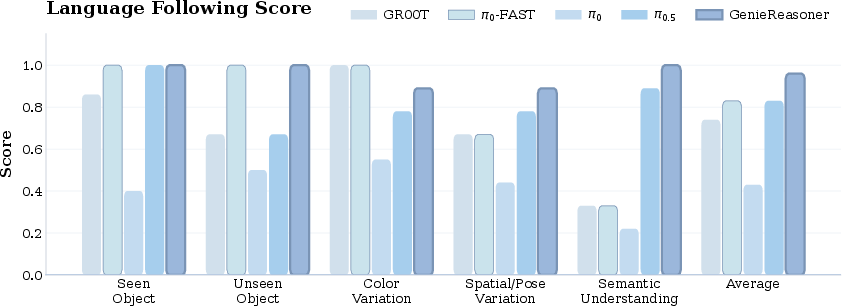
- Ablations show the recipe matters: Mixing embodied VQA with action alignment in both pre-training and post-training improves language following and task success rates, showing that keeping reasoning and action training aligned is key.
These results matter because real-world robots need to be smart and careful at the same time. This paper shows a practical path to get both.
What’s the impact?
If widely adopted, ERIQ can become a standard way to test and improve robot reasoning. FACT offers a powerful bridge between language-style learning and precise control, making it easier to train unified models that don’t trade off thinking for accuracy. GenieReasoner demonstrates that a single system can plan, understand, and move precisely, which is essential for robots working in homes, hospitals, factories, and stores.
In simple terms: This research helps build robots that can understand complex instructions, spot and fix mistakes, cooperate with humans, and move with the precision needed to safely handle real tasks in messy, unpredictable environments.
Knowledge Gaps
Unresolved Gaps and Open Questions
Below is a single, concrete list of limitations, knowledge gaps, and open questions left unresolved by the paper that future researchers can address.
- ERIQ benchmark scope: Does not directly evaluate closed-loop, interactive, on-robot error detection and recovery; only multiple-choice QA. Add embodied, online evaluation where detected errors are corrected through actual control.
- Causality of correlation: “Strong positive correlation” between ERIQ scores and VLA success is claimed without detailed statistics (e.g., coefficient values, confidence intervals), confound controls (model size, data volume, training compute), or causal tests. Provide rigorous correlation/causation analysis and sensitivity studies.
- Benchmark bias and generality: ERIQ uses data from five domains but lacks coverage of deformable objects, contact-rich manipulation (insertion, force control), tool use, bimanual tasks, mobile manipulation, and safety-critical scenarios. Expand domains and task types to stress test embodied reasoning under complex physics and safety constraints.
- Multiple-choice format limitations: Deterministic MC evaluation may permit guesswork and pattern exploitation; no open-ended, graded, or programmatic reasoning checks. Introduce calibrated distractors, confidence scoring, and open-ended or programmatic tasks to reduce guessing and measure reasoning depth.
- Human intent: Evaluated via QA only; no interactive HRI experiments (turn-taking, intent disambiguation, safety). Integrate real human-robot collaboration tasks and measure alignment, timing, and safety outcomes.
- Data provenance and leakage: The paper aggregates many public datasets but does not report overlap checks with ERIQ or downstream tasks. Audit data overlaps and publish contamination checks to ensure fair generalization claims.
- Reproducibility: It is unclear whether ERIQ, FACT, and GenieReasoner training code, models, and evaluation scripts are released and versioned. Provide full reproducibility assets, seeds, and protocol documentation.
- Fairness of baselines: Comparisons to pi0 / pi0.5 and FAST lack matched data budgets, training schedules, and compute. Run controlled, resource-matched baselines with standardized training recipes for fair head-to-head comparisons.
- Scaling laws and model size: Results emphasize a 3B model; scaling behavior (data/model size vs. reasoning and control quality) is unknown. Establish scaling laws for embodied reasoning and action fidelity across parameter counts.
- Runtime and latency: FACT requires ODE integration; the impact on real-time control latency, jitter, and closed-loop stability is not quantified. Benchmark inference speed, integration step budgets, and on-robot responsiveness under tight control cycles.
- Determinism and repeatability: Flow-matching decoding starts from Gaussian noise; repeatability and variance across seeds for robotic execution are not reported. Add deterministic decoding modes or variance-reduction strategies and quantify execution variance.
- Tokenizer design space: FACT uses bitwise sign quantization and a VQ-style encoder; no ablation versus multi-bit codes, learned codebooks, hierarchical tokenizers, or alternative conditional decoders (diffusion, normalizing flows). Systematically study quantizer and decoder design trade-offs.
- Fidelity vs. compression: MSE comparisons vs. FAST are shown, but the compression–precision curve, task success sensitivity to reconstruction error, and acceptable error budgets for contact-rich tasks remain uncharacterized. Map action success rates to reconstruction error thresholds at varying code lengths.
- Long-horizon control: Autoregressive token sequences may accumulate error; robustness over long horizons (H) is not analyzed. Evaluate drift, compounding errors, and corrective strategies (closed-loop replanning, token resynchronization).
- Physical feasibility and safety: No explicit enforcement of kinematic/dynamic constraints or safety (velocity/acceleration limits, collision avoidance, control barrier functions). Integrate constraint-aware decoding and safety monitors, and quantify safety incidents.
- Observation modalities: Primarily image–text; absence of proprioception, tactile/force, audio, depth/3D, or state estimation inputs. Add multimodal sensing to evaluate reasoning under partial observability and enhance precision in contact tasks.
- Control space coverage: Action representation appears focused on end-effector pose and gripper state; torque/impedance control and compliance are not considered. Test FACT with richer action spaces and controllers (e.g., torque-level or hybrid position–force).
- Cross-embodiment generalization: Qualitative transfer is shown, but quantitative zero-shot generalization to unseen robots (different kinematics, actuation, workspace) is not reported. Design standardized cross-embodiment benchmarks with metrics for adaptation vs. zero-shot transfer.
- Robustness to perturbations: No evaluation under sensor noise, occlusions, lighting changes, calibration drift, or adversarial instructions. Stress-test robustness and add uncertainty-aware reasoning and control.
- Chain-of-Thought (CoT): CoT is visualized but not quantitatively linked to execution gains or measured for faithfulness. Evaluate whether CoT improves task success and detect hallucinated or post-hoc rationalizations.
- Training schedule and mixing ratios: Co-training mixes general VQA, embodied VQA, and action data, but optimal mixtures, curriculum strategies, and catastrophic forgetting analyses are missing. Ablate curriculum ordering, ratios, and replay strategies; measure interference and retention.
- Generalization to novel tasks: Open-source spatial benchmarks are covered, but broader embodied tasks (e.g., non-spatial reasoning, tool-use sequences) are limited. Include comprehensive, diverse embodied reasoning tasks beyond spatial perception.
- Token–reasoning interference: Unified gradient space may induce interference between token-based language reasoning and action token prediction; no gradient/router analysis. Measure interference via representational similarity, gradient alignment, and apply routing or adapters if needed.
- Controller integration: FACT decoding outputs are executed directly; integration with industrial control stacks (trajectory smoothing, servo constraints) and compatibility with different controllers is not examined. Evaluate controller-specific integration and downstream control quality.
- Safety and ethics: No discussion of safety protocols for real deployments (fail-safes, human-override, risk assessment) or ethical implications of general-purpose manipulation. Define deployment safety frameworks and ethical guidelines for embodied VLMs.
- Sample efficiency: The paper hints at small-number trajectory fine-tuning improving success but provides no quantitative sample-efficiency curves. Measure performance gains vs. number of trajectories and identify diminishing returns.
- Memory and state: Long-horizon reasoning likely benefits from persistent memory/state tracking; the architecture lacks explicit memory modules or world models. Explore memory-augmented policies and world-state representations to sustain multi-step tasks.
- Interpretability of action tokens: The semantics of action tokens are not analyzed; no mapping to interpretable subskill libraries or planners. Investigate token interpretability and alignment with hierarchical planners for transparent control.
- Failure mode analysis: Beyond aggregate metrics, there is no taxonomy of failure modes (perception errors, reasoning mistakes, decoding drift, control limits). Provide granular failure analyses and targeted mitigation strategies per mode.
Practical Applications
Below is an overview of practical, real-world applications derived from the paper’s contributions—ERIQ (Embodied Reasoning Intelligence Quotient), FACT (Flow-matching Action Tokenizer), and the unified GenieReasoner training/inference pipeline—mapped to sectors, potential tools/workflows, and feasibility assumptions.
Immediate Applications
- Embodied reasoning evaluation and QA for VLM/VLA systems (ERIQ)
- Sectors: Robotics R&D, academia, integrators, platform vendors
- What: Use ERIQ’s deterministic, multiple-choice evaluation to decouple and quantify embodied reasoning (spatial grounding, planning/monitoring, error detection/recovery, human intent) independent of execution.
- Tools/workflows: ERIQ Runner (batch evaluation scripts, model adapters), a lab/CI “reasoning gate” for model releases, leaderboard-style internal benchmarking.
- Assumptions/dependencies: Access to ERIQ data and consistent evaluation protocols; camera viewpoints aligned with “robo view”; compute to batch-evaluate large models.
- Model selection and procurement for robotics deployments
- Sectors: Manufacturing, logistics/warehousing, retail, hospitality, field robotics
- What: Use the paper’s finding (strong correlation between embodied reasoning and end-to-end success) to establish a pre-deployment screening protocol: shortlist models by ERIQ, then run minimal on-robot trials.
- Tools/workflows: “Reasoning-first” down-select pipeline; KPI dashboard linking ERIQ sub-scores to on-site success/failure modes; vendor SLAs referencing ERIQ thresholds.
- Assumptions/dependencies: ERIQ scores generalize to the target environment; availability of small-scale pilot runs; standardized test scenes.
- Drop-in discrete action head upgrade (FACT) for existing VLAs
- Sectors: Robotics, software/ML tooling, cloud robotics
- What: Replace/augment variable-length or continuous heads (e.g., FAST-like or diffusion heads) with FACT to improve decoding stability and maintain reasoning performance while preserving high-fidelity control.
- Tools/products: FACT SDK (encoder/decoder modules, ROS 2 nodes), tokenization services, migration guides for existing VLA stacks.
- Assumptions/dependencies: Access to training data for FACT pretraining; real-time ODE/flow integration performance on available hardware (edge GPU); compatibility with the host backbone.
- Token-efficient action streaming and logging
- Sectors: Cloud robotics, teleoperation/tele-assist, fleet management
- What: Use compact action tokens for low-bandwidth streaming, audit trails, and reproducible action replays with high-fidelity flow-based reconstruction.
- Tools/workflows: Token logger/replayer, compression-aware telemetry, on-device decoder microservice.
- Assumptions/dependencies: Deterministic decoding; secure, low-latency links; synchronization between token streams and sensory data.
- Failure analysis and error-recovery playbooks
- Sectors: Manufacturing cells, warehouse picking/packing, retail back-of-house, micro-fulfillment
- What: Map real failures to ERIQ’s “mistake existence/classification/recovery” taxonomy to generate corrective action suggestions and accelerate root-cause analysis.
- Tools/workflows: Ops dashboard with ERIQ-aligned error labels; post-mortem templates; retraining loops prioritizing observed error categories.
- Assumptions/dependencies: High-quality incident logs; human-in-the-loop oversight for initial labeling and validation.
- Human–robot collaboration screening
- Sectors: Cobotics, hospitality, light assembly, education
- What: Validate human intent understanding and interaction safety via ERIQ’s intention/interaction subsets before floor deployment.
- Tools/workflows: Pre-floor “collab check” suite; scenario scripts with humans; pass/fail certification tied to ERIQ thresholds.
- Assumptions/dependencies: Sensing stack captures human pose/gestures; handling cultural/environmental variability in intent cues.
- Curriculum and coursework in embodied AI
- Sectors: Academia, training providers, robotics bootcamps
- What: Use ERIQ for labs/assignments; replicate training recipes (joint VQA + embodied VQA + tokenized actions) for projects studying reasoning–control trade-offs.
- Tools/workflows: Course kits, baseline checkpoints, ablation recipe templates.
- Assumptions/dependencies: Accessible compute and datasets; clear licensing for instructional use.
- Simulation-to-real evaluation pipeline
- Sectors: Robotics R&D, simulation vendors, integrators
- What: Combine ERIQ reasoning tests with sim-world manipulation trials to reduce risk before real robot trials; use FACT for robust sim logging/replay.
- Tools/workflows: “Reasoning → Sim E2E → Real E2E” pipeline; sim adapters for tokenized actions; scenario libraries aligned with ERIQ categories.
- Assumptions/dependencies: Sim fidelity and camera/viewpoint alignment to real; domain randomization; calibration transfer.
Long-Term Applications
- General-purpose household and service robots with robust open-world generalization
- Sectors: Consumer robotics, eldercare, hospitality, facilities
- What: Deploy GenieReasoner-like unified reasoning–control stacks to execute diverse, long-horizon tasks (tidying, meal prep assistance, restocking) with error detection/recovery and intent awareness.
- Tools/products: Home-service robot platforms, app/task store with tokenized skill packs.
- Assumptions/dependencies: Safety certifications; reliable on-device inference; large, diverse embodied datasets; cost-effective hardware.
- Sector-wide certification standards for embodied AI reasoning
- Sectors: Policy/regulation, standards bodies, insurance
- What: Formalize ERIQ-like suites as certification gates for cobots/service robots (minimum reasoning scores per domain, e.g., error recovery and intent).
- Tools/workflows: Public benchmark consortium, third-party test labs, compliance documentation.
- Assumptions/dependencies: Community consensus; continuous benchmark maintenance; correlation to real-world incident rates.
- High-precision dexterous manipulation in advanced manufacturing
- Sectors: Electronics/medical device assembly, small-batch manufacturing
- What: Use FACT-enabled discrete planning with flow-based precision for micro-assembly, insertion, and fine alignment tasks with low scrap rates.
- Tools/workflows: GenieReasoner action heads on line controllers; calibration routines; token-based skill libraries.
- Assumptions/dependencies: Tight cycle-time constraints; haptics/force sensing integration; robust station calibration and tolerance modeling.
- Warehouse autonomy under shifting SKUs and layouts
- Sectors: Logistics/fulfillment
- What: Leverage ERIQ-driven model selection and GenieReasoner control to handle layout/packaging changes, long-horizon picking, and recovery from slips/misgrasp.
- Tools/workflows: Continual evaluation and redeployment loop; ERIQ “shift-readiness” scorecards; token-based policy updates to fleets.
- Assumptions/dependencies: Continuous data collection; robust perception under occlusions; scalable fleet orchestration.
- Human-in-the-loop shared autonomy and tele-assist with tokenized control
- Sectors: Field robotics, inspection/maintenance, disaster response
- What: Combine autonomy with human guidance where operators send sparse tokenized intents/corrections, while FACT reconstructs fine motor control onsite.
- Tools/workflows: Shared-control UI; intent-to-token translator; safety overrides and explainability via reasoning traces.
- Assumptions/dependencies: Reliable low-latency communications; interpretable intermediate reasoning; robust fail-safes.
- Assistive and healthcare robotics
- Sectors: Healthcare, rehabilitation, home care
- What: Task assistance (fetch-and-carry, tray handling), with strong planning/monitoring and error recovery; intent-aware interaction with patients/clinicians.
- Tools/workflows: Hospital-grade integrations; sterile-safe action libraries; ERIQ-derived clinical scenario evaluations.
- Assumptions/dependencies: Clinical validation and regulation; hygiene and safety standards; privacy-compliant data pipelines.
- Multi-embodiment, cross-fleet generalist policies
- Sectors: Robotics platform vendors, AMR/cobot fleets
- What: Train once and deploy across arms/bases with adaptor layers; use ERIQ to validate reasoning invariance across embodiments and domains.
- Tools/workflows: Embodiment adapters; calibration-in-the-loop training; fleet telemetry aligning tokens and outcomes.
- Assumptions/dependencies: Standardized action spaces or reliable mapping layers; ample multi-embodiment datasets.
- On-device, low-power inference for mobile manipulators
- Sectors: Consumer/service robotics, hospitality
- What: Token-efficient planning and decoding to meet edge compute and battery constraints while retaining high-fidelity motion.
- Tools/workflows: Optimized FACT decoder kernels; quantized backbones; adaptive token budgets per task phase.
- Assumptions/dependencies: Hardware acceleration for flow-based decoders; thermal and latency budgets; robust power management.
- Safety assurance, auditing, and insurance pricing
- Sectors: Risk/insurance, compliance, enterprise IT/OT
- What: Use ERIQ sub-scores and operational metrics to predict failure modes, set premiums, and determine deployment boundaries.
- Tools/workflows: Risk dashboards; continuous compliance checks; KPI-to-policy mapping.
- Assumptions/dependencies: Longitudinal incident data; accepted risk models linking reasoning metrics to loss events.
- Utilities, energy, and infrastructure inspection/repair
- Sectors: Energy/utilities, construction, infrastructure
- What: Intent-aware, error-recovering manipulation for valves, breakers, panels; tokenized action replays for forensic analysis.
- Tools/workflows: Task packs for common interventions; ruggedized perception; anomaly-aware planning and recovery.
- Assumptions/dependencies: Environmental robustness (dust, rain, EMI); safety interlocks; standards compliance.
Notes on cross-cutting assumptions and dependencies
- Data and compute: High-quality, diverse embodied datasets (including egocentric views) and significant compute for multi-stage training; clear licensing.
- Real-time constraints: FACT’s flow-based decoding must meet latency budgets; may require GPU/accelerator optimization and careful ODE step sizing.
- Integration: ROS 2 or equivalent middleware integration; calibration of cameras/end-effectors; safety-certified controllers and interlocks.
- Generalization limits: ERIQ’s coverage is broad but not exhaustive; site-specific domain shift and rare events require continual data and adaptation.
- Governance and safety: Human oversight, incident logging, and rollback mechanisms are needed during early deployments; policy adoption will lag technical readiness.
Glossary
- AdaLN modulation: A technique that injects conditioning (like time) into transformer blocks via Adaptive LayerNorm to guide model behavior. "Architecturally, is injected into the MM-DiT blocks via AdaLN modulation, allowing the model to adapt its predictions across the integration trajectory."
- Affordance: Object properties that suggest possible actions for a robot (e.g., graspable, pourable), used to guide manipulation. "augment sub-task planning with auxiliary information—including affordance estimation and detection results—to better guide low-level control."
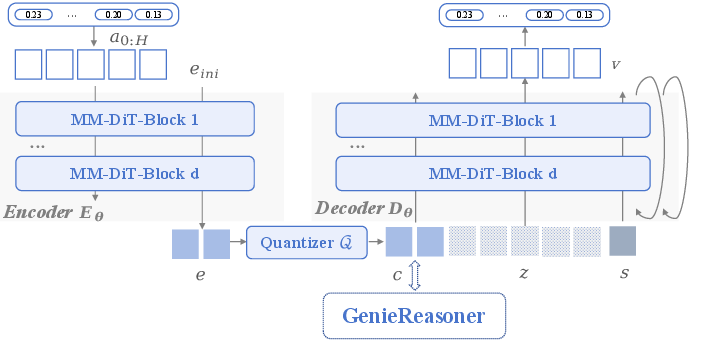
- Autoregressive transformer: A transformer model that predicts the next token step-by-step, enabling sequence generation for reasoning and actions. "(Left) Our system leverages large-scale general and embodied multimodal data to co-optimize high-level reasoning and low-level control within a unified autoregressive transformer."
- Bitwise quantizer: A quantization method that maps continuous embeddings to discrete codes using element-wise binary signs. "To obtain a discrete representation, we employ a bitwise quantizer following the lookup-free quantization method~\cite{magvit_v2}."
- Byte-Pair Encoding (BPE): A tokenization algorithm that compresses sequences by merging frequent symbol pairs, used here for action tokens. "Recent attempts like FAST \cite{pertsch2025fast} utilize byte-pair encoding (BPE) to achieve compact action compression"
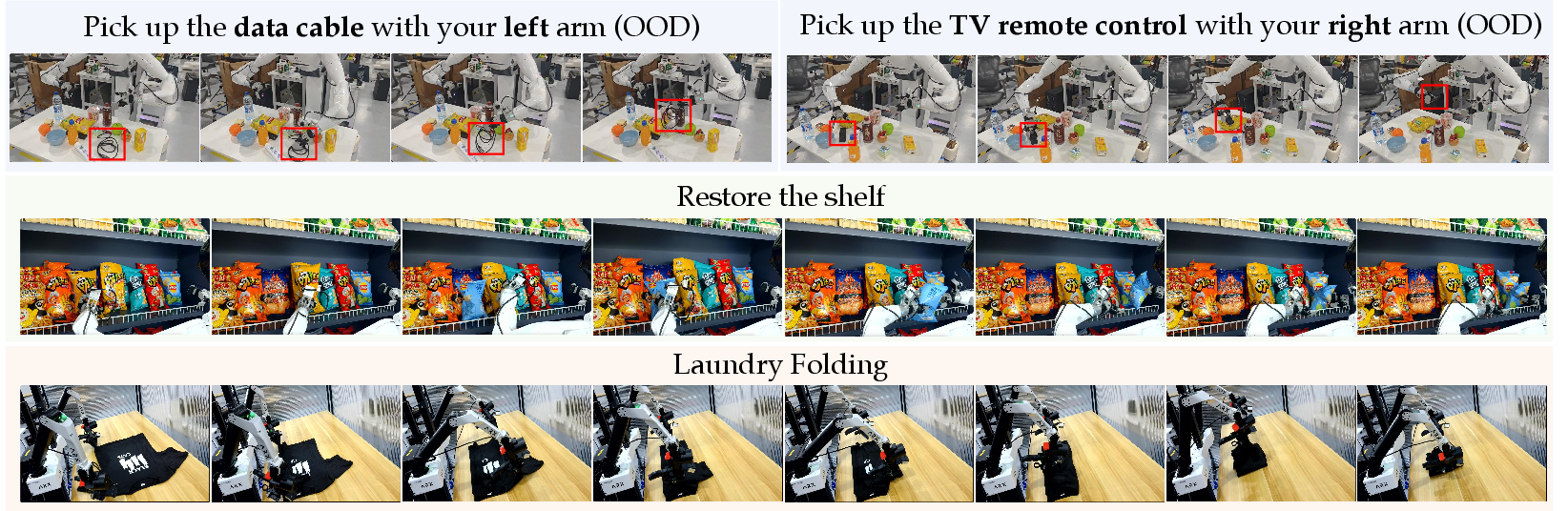
- Chain-of-Thought (CoT): An approach where models generate explicit intermediate reasoning steps before producing final outputs. "We display spatial reasoning, subtask planning, and Chain-of-Thought (CoT) inference across diverse embodiments (AgiBot G01, AgiBot Genie Simulation, AgileX, ARX)."
- Commitment loss: A VQ-VAE regularizer that keeps continuous embeddings close to their quantized codes to stabilize training. "The commitment loss ensures the continuous embedding stays close to its quantized value:"
- Co-training: Jointly training a model on multiple objectives or modalities to align capabilities (e.g., language and actions). "One class of methods discretizes continuous robotic actions to enable co-training with VLM tokens."
- Diffusion (generative modeling): A generative method that learns to denoise noisy inputs to produce precise continuous outputs (e.g., actions). "several recent works have integrated continuous action representations using diffusion or flow-matching objectives"
- Egocentric perception: Understanding scenes from the robot’s first-person viewpoint to reason and act effectively. "Some benchmarks have focused on isolated embodied reasoning facets, such as egocentric perception"
- Embodied Chain-of-Thought (ECoT): A method that teaches VLA models to produce multi-step embodied reasoning traces before actions. "Embodied Chain-of-Thought (ECoT)~\cite{zawalski2024robotic} trains VLAs to generate explicit multi-step reasoning outputs before predicting actions."
- Embodied reasoning: The synthesis of spatial, temporal, and causal understanding to plan and correct physical actions. "we introduce Embodied Reasoning Intelligence Quotient (ERIQ), a large-scale embodied reasoning benchmark in robotic manipulation,"
- End-effector: The robot’s tool or gripper at the tip of its manipulator that interacts with objects. "(e.g., end-effector pose and gripper state)"
- Entropy loss: A regularizer that encourages diverse use of quantized codes (codebook entries) during training. "The entropy loss maximizes codebook usage over the empirical distribution of codes within a batch, denoted as :"
- FACT (Flow-matching Action Tokenizer): A tokenizer that discretizes actions and uses flow-matching decoding to reconstruct high-fidelity continuous trajectories. "To tackle this problem, we present FACT (Flow-matching Action Tokenizer), a discrete action tokenizer that leverages flow-matching to reconstruct high-fidelity continuous trajectories from compact token sequences."
- Flow-matching: A generative method that learns a velocity field to transport noise to data, enabling precise trajectory reconstruction. "leverages flow-matching to reconstruct high-fidelity continuous trajectories from compact token sequences."
- Generative heads: Continuous-output modules attached to VLM backbones that generate actions via objectives like diffusion/flow. "While these generative heads offer superior precision, they often face significant optimization conflicts when paired with discrete VLM backbones."
- Knowledge Insulation: A training strategy that blocks gradients from action heads into the backbone to preserve pre-trained reasoning. "Driess et al. \cite{driess2025knowledge} propose ``Knowledge Insulation'' to block gradient flow into the backbone"
- Lookup-free quantization: A quantization approach that directly computes codes (e.g., via sign) without searching a codebook index. "following the lookup-free quantization method~\cite{magvit_v2}"
- Multimodal Diffusion Transformer (MM-DiT): A transformer architecture tailored for diffusion-style generation across modalities. "For the backbone of both components, we employ the Multimodal Diffusion Transformer (MM-DiT) architecture"
- Ordinary Differential Equation (ODE): A continuous-time equation solved during decoding to reconstruct actions from learned velocity fields. "Technically, we solve the Ordinary Differential Equation (ODE) defined by the learned velocity field,"
- Probability flow ODE: The deterministic ODE counterpart of diffusion that transports noise to data along a learned flow. "By solving the probability flow ODE, the decoder ensures high-precision manipulation that is semantically grounded in the task instruction."
- Rectified Flow: A flow-matching training objective that learns constant-velocity transport from noise to data along straight paths. "We train the decoder network using the Rectified Flow objective."
- Symbol grounding: Mapping language instructions to specific objects or locations in the physical world. "and to solve the symbol grounding problem in cluttered scenes."
- Variable-length encodings: Token sequences whose length changes with content, which can destabilize autoregressive decoding. "variable-length encodings, where the non-deterministic structure frequently leads to decoding failures"
- Vector-Quantized Variational Autoencoder (VQ-VAE): A model that discretizes latent representations via a learned codebook for compact tokenization. "learned quantization (e.g., VQ-VAE~\cite{vqvla, szot2024grounding}) offers compact codes but lacks high-precision control"
- Vision-Language-Action (VLA) models: Models that unify perception, language reasoning, and action prediction for robotics. "These advances have led to Vision-Language-Action (VLA) models that extend VLMs' reasoning capability to directly predict robotic actions,"
- Vision-LLMs (VLMs): Models that process and reason over visual inputs and text jointly. "Recent advances in Large Vision-LLMs (VLMs), pre-trained on extensive internet-scale datasets,"
- Visual Question Answering (VQA): A task where models answer questions about visual inputs to evaluate understanding. "ERIQ employs a standardized Visual Question Answering (VQA) protocol to quantify embodied comprehension"
- Zero-shot: Evaluating a model on tasks without task-specific fine-tuning or training examples. "These results are generated in a zero-shot setting,"
Collections
Sign up for free to add this paper to one or more collections.