- The paper presents an empirically-grounded taxonomy of 32 security issues and 24 solutions organized across four core themes in the AI supply chain.
- It employs a hybrid methodology combining keyword matching and a fine-tuned distilBERT classifier, achieving MCC = 0.79 and F1 = 0.89.
- The study uncovers exponential trends in developer security reports and reveals gaps in practical mitigations for model and data vulnerabilities.
Securing the AI Supply Chain: Empirical Insights from Developer-Reported Security Issues and Solutions
Introduction
The paper "Securing the AI Supply Chain: What Can We Learn From Developer-Reported Security Issues and Solutions of AI Projects?" (2512.23385) presents a comprehensive, empirically-grounded analysis of security vulnerabilities and resolution strategies in AI-enabled projects. By systematically mining and classifying developer discussions from Hugging Face (HF) and GitHub (GH)—central platforms for collaborative AI model, data, and code distribution—the study captures real-world security challenges within the AI supply chain. The authors develop a hybrid pipeline based on keyword matching and an optimally fine-tuned distilBERT classifier, generating a corpus of 312,868 security-related posts enabling extensive thematic analysis. The research advances both practical and theoretical understanding by surfacing a fine-grained taxonomy of 32 security issues and 24 solutions organized across four core themes: System and Software, External Tools and Ecosystem, Model, and Data.
Methodological Framework
The study adopts a robust, multi-stage methodology designed to maximize the fidelity and coverage of AI supply chain security discourse. Extraction begins with curation of active HF projects, followed by parsing of GH linkage and extensive crawls of both issue and discussion threads. Subsequent identification of security-related records leverages strict keyword-based sampling augmented through manual validation, then substantially expanded via fine-tuned deep learning models and LLM benchmarking.
The classifier evaluation phase substantiates that task-specific DL models outperform open-domain LLMs for this application, with distilBERT achieving MCC = 0.79 and F1 = 0.89 on the combined dataset. This classification pipeline enables derivation of a massive, representative dataset facilitating both quantitative pattern analysis and in-depth qualitative, codebook-driven thematic synthesis.
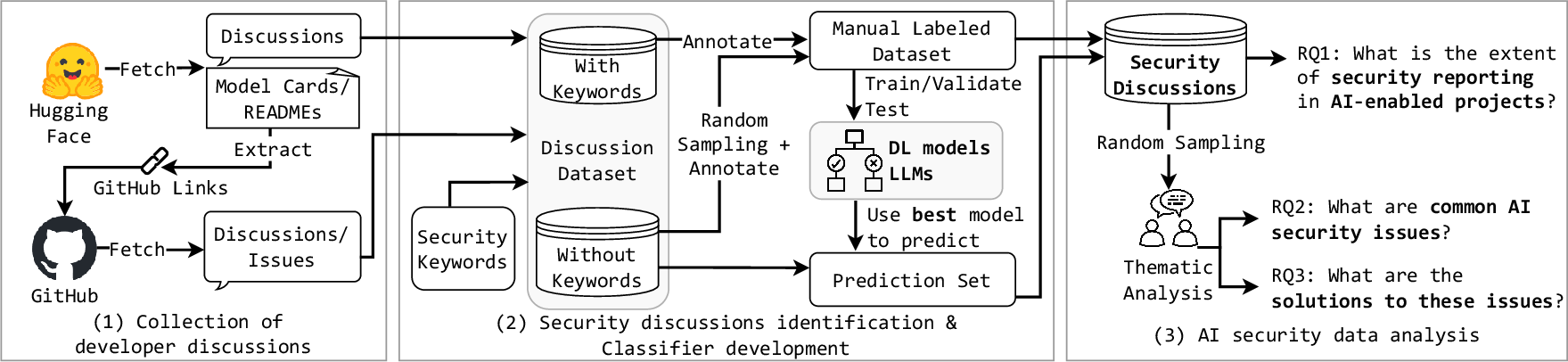
Figure 1: Research workflow outlining data collection, security discussion classification, and taxonomy development for fine-grained analysis.
Scale, Trends, and Pattern Analysis of Security Reporting
The dataset reveals exponential growth in developer security reporting on both platforms. GH security reports more than doubled yearly, peaking at 83,561 in 2024, while HF Discussions increased nearly tenfold in the same period. Strikingly, fewer than 0.1% of security discussions reference a formal CVE-ID, underscoring the critical gap between real-world developer experiences and the scope of formal vulnerability tracking.
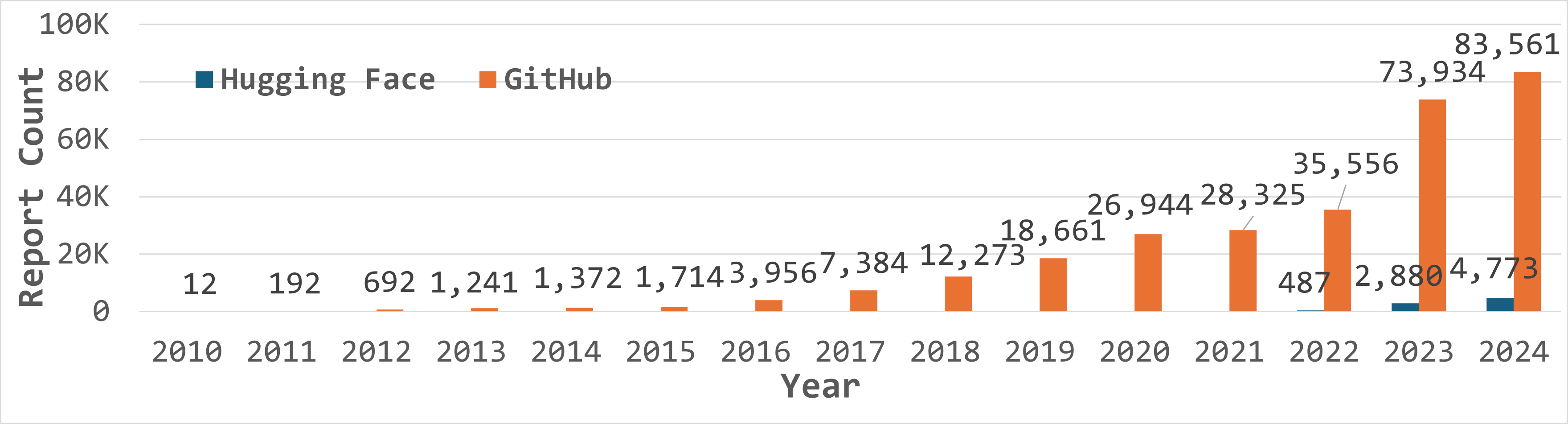
Figure 2: Temporal trends illustrating the rapid escalation in the number of AI security reports on GitHub and Hugging Face from 2022–2024.
Distributional analyses demonstrate that security concerns are most concentrated in text generation and foundation models—those commonly reused as bases for downstream tasks—where attention centers on potential generative risks and systemic impact propagation.
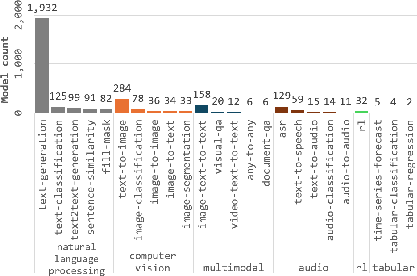
Figure 3: Task/domain breakdown showing predominance of security-related issues in generative NLP models, followed by vision and speech domains.
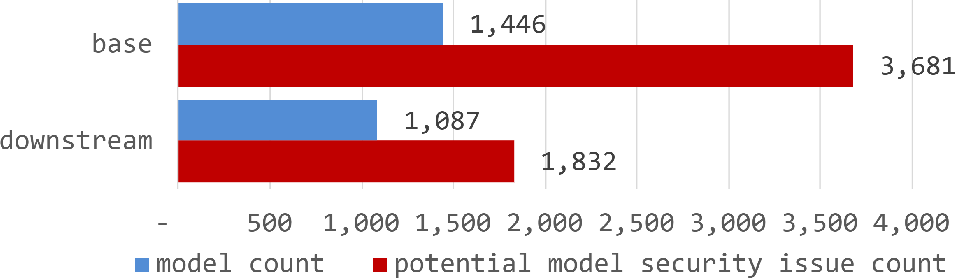
Figure 4: Comparative analysis of security issue frequency per model type, highlighting increased risk concentration in foundational models.
Taxonomy of Security Issues
The manually validated sample and classifier-augmented dataset supports the construction of a detailed taxonomy with four principal themes:
System and Software
These issues mirror traditional software vulnerabilities but manifest in the AI context with high frequency. Runtime compatibility problems, unsafe code execution (especially via insecure deserialization), deployment misconfigurations, resource exhaustion, and communication failures are prominent. The prevalence of serialization-based exploits and misconfigured environments, notably with pickle use and open network bindings, is bold and strongly supported by developer reporting.
Supply chain risk emerges through reliance on external dependencies and platforms. Developers report persistent exposure to outdated or malicious libraries, poorly managed authentication, reliability failures in external APIs, and both false positives and negatives from security scan tools, confirming the cross-surface nature of supply chain vulnerabilities.
Model
Security risks unique to model artifacts surface in both output and input phases. Notably, developers detail models generating unsafe code, producing infinite output due to tokenization errors, and failing to reliably filter malicious prompts. Prompt injection and adversarial manipulation are frequent but lack robust, practical countermeasures in developer discussions.
Data
Data-centric issues focus on leakage/exposure (including training artifacts leaking sensitive information), integrity problems (poisoned or malicious inputs), and trust failures when provenance or isolation is inadequate. Few effective mitigations are observed, highlighting notable gaps in data security operationalization.
Solution Taxonomy and Practical Gaps
Synthesis of developer-proposed interventions reveals an asymmetric landscape: robust solutions exist for System and Software and supply chain problems (e.g., input validation, secure deployment/configuration, dependency management), but Model and Data vulnerabilities remain under-addressed.
System and Software Solutions
Practical solutions are grounded in secure coding, execution sandboxing, infrastructure hardening, and runtime checks. Defensive deserialization (favoring formats such as safetensor over pickle), explicit configuration management, and secure communication protocols are promoted and frequently adopted.
Ecosystem Interventions
Supply chain security is managed via dependency upgrades/removal, strict source control, checksum validation, and runtime isolation. Improved scan tools and explicit vulnerability disclosure practices are leveraging community best practices.
AI-Specific Surface Defenses
Model and data solutions are sparse; suggestions focus on secure prompt techniques, output filtering, and rudimentary data anonymization. These lack deep integration or formalization, and practical adoption remains limited, often resorting to workaround strategies.
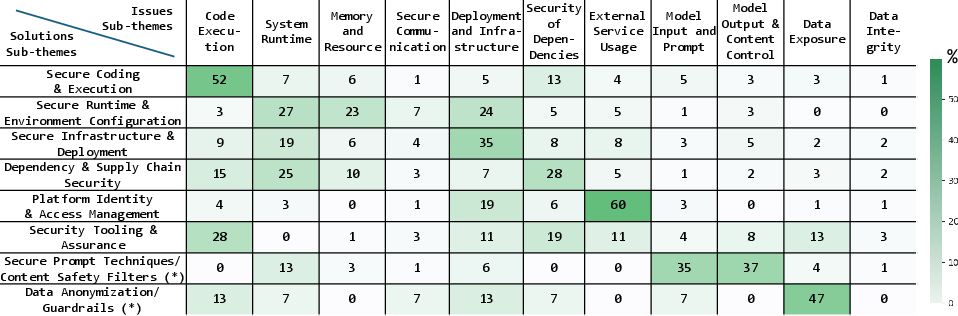
Figure 5: Heatmap visualizing the distribution of security issues and the corresponding solution coverage, emphasizing disparity between surface areas, especially for Model and Data.
Implications and Theoretical Contributions
The study evidences a critical mismatch between the rapid escalation of AI-specific vulnerabilities and the maturity of practical solutions, particularly for model and data artifacts. The findings challenge the sufficiency of current security frameworks, underscoring the need for empirical augmentation. The weak presence of Model and Data mitigations—contrary to the core threat surface—constitutes a bold claim that the AI community must address. The authors advocate for the formalization of AI Bill of Materials (AIBOM) schemas to capture vulnerability provenance across software, model, and data layers, recommending targeted transparency and automated extraction for downstream risk mitigation.
The cross-cutting nature of solutions highlights that effective supply chain security necessitates a holistic approach—tools and interventions must bridge software and AI-specific vulnerabilities rather than operate in isolation. Translation of academic defense strategies (e.g., adversarial training, provenance tracking) into operational practices and toolchains is identified as a key challenge for future research.
Future Outlook
Operationalizing advanced model and data layer defenses, integrating holistic supply chain transparency frameworks, and bridging the gap between formal CVE tracking and developer-driven security discourse will critically inform both the resilience and trustworthiness of future AI systems. The proposed taxonomy and empirical insights lay groundwork for ongoing research in vulnerability lifecycle modeling, real-time threat intelligence, and meta-framework development for supply chain security in the AI domain.
Conclusion
This work provides a rigorous, evidence-based mapping of the security issues and solution landscapes across the AI supply chain, based on a large-scale, multi-platform corpus of developer discussions. Key numerical results include the identification of 312,868 security-related posts with fewer than 0.1% referencing CVEs, and quantitative confirmation that practical solutions are heavily skewed towards traditional software problems, leaving AI-specific surfaces exposed. The research compels the community to proactively re-align theoretical frameworks and practical toolchains to address the emergent, complex realities of AI supply chain risk.

