AI-Generated Code Is Not Reproducible (Yet): An Empirical Study of Dependency Gaps in LLM-Based Coding Agents
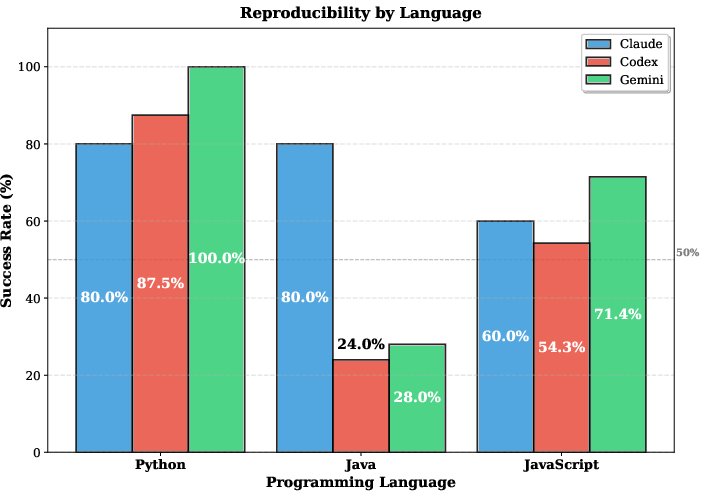
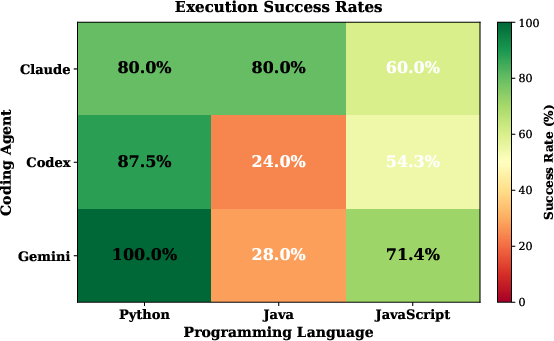
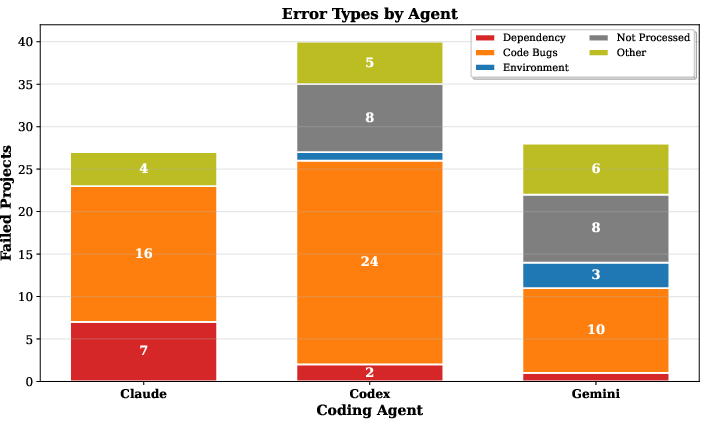
Abstract: The rise of LLMs as coding agents promises to accelerate software development, but their impact on generated code reproducibility remains largely unexplored. This paper presents an empirical study investigating whether LLM-generated code can be executed successfully in a clean environment with only OS packages and using only the dependencies that the model specifies. We evaluate three state-of-the-art LLM coding agents (Claude Code, OpenAI Codex, and Gemini) across 300 projects generated from 100 standardized prompts in Python, JavaScript, and Java. We introduce a three-layer dependency framework (distinguishing between claimed, working, and runtime dependencies) to quantify execution reproducibility. Our results show that only 68.3% of projects execute out-of-the-box, with substantial variation across languages (Python 89.2%, Java 44.0%). We also find a 13.5 times average expansion from declared to actual runtime dependencies, revealing significant hidden dependencies.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Glossary
- Agent-Language Specialization Matrix: A comparative grid showing each agent’s success across different programming languages. "Agent-Language Specialization Matrix"
- AWS EC2: Amazon’s elastic compute cloud service used to provision standardized virtual machines for experiments. "We deployed AWS EC2 instances (t2.large with 4 vCPUs and 16GB RAM running Ubuntu 22.04 LTS)"
- Claimed Dependencies: The set of packages explicitly specified by the LLM as required for a project. "The first layer consists of Claimed Dependencies , which the LLM explicitly tells us we need."
- Completeness gap: The difference between declared and actually needed dependencies discovered during reproduction. "The completeness gap (Equation 6) tells us how many dependencies the LLM forgot to mention:"
- Dependency closure: The full set of direct and indirect packages required to run code. "fail to specify the dependency closure required for reproduction."
- Dependency scopes: Maven’s classification of dependencies by purpose (e.g., compile, runtime, test). "multiple dependency scopes (compile, runtime, test, provided)"
- Dependency tree: A hierarchical representation of direct and transitive dependencies for a project. "And for Java, we extracted Maven's dependency tree to see how one library pulls in dozens of others"
- devDependencies: JavaScript packages needed for development but typically not for production runtime. "complicated by the distinction between dependencies and devDependencies"
- Executable Reliability: The probability that a project runs successfully in a clean environment using only the LLM-provided specs. "we introduce Executable Reliability: the likelihood that a project executes successfully in a clean environment using only the dependencies and instructions the AI provides."
- HumanEval: A benchmark assessing code generation functional correctness. "Current benchmarks like HumanEval and MBPP evaluate functional correctness assuming reproducible environments exist."
- Iterative Dependency Resolution: A stepwise procedure to identify and install missing packages until execution succeeds. "Iterative Dependency Resolution"
- Iterative Resolution Protocol: The evaluation workflow that emulates developer debugging after initial execution failure. "Iterative Resolution Protocol"
- JUnit: A widely used Java testing framework. "Java projects most commonly lack test framework specifications (particularly JUnit)"
- LiveCodeBench: A benchmark that mitigates memorization by providing complete environments. "LiveCodeBench prevents memorization but still provides complete environments"
- Maven: Java’s build and dependency management tool. "Maven's complex transitive dependency resolution"
- MBPP: A benchmark for evaluating program synthesis on multiple tasks. "Current benchmarks like HumanEval and MBPP evaluate functional correctness assuming reproducible environments exist."
- npm: JavaScript’s package manager used to resolve and inspect dependency trees. "For JavaScript, we parsed npm's dependency tree to understand the full cascade of package requirements"
- pip resolver: Python’s dependency resolution mechanism used by pip to manage package installations. "mature pip resolver with clear error messages"
- pom.xml: Maven’s project configuration file specifying dependencies, plugins, and build settings. "complex XML configuration in pom.xml"
- Provenance: Recorded metadata describing what occurs during execution (e.g., loaded dependencies). "SciUnit Provenance Analysis"
- ReproZip: A tool that captures execution environments to enable reproducibility. "While tools like ReproZip and SciUnit capture execution environments for reproducibility"
- requirements.lock: A locked dependency file documenting exact versions required for reproducible runs. "publishing requirements.lock files with exact versions of all 37+ packages actually needed"
- requirements.txt: A Python file listing required packages (and versions) for a project. "requirements.txt listing dependencies."
- Runtime Dependencies: All packages actually loaded during execution, including transitive ones. "The third and deepest layer exposes Runtime Dependencies - everything that actually gets loaded when the code runs, including all transitive dependencies."
- Runtime multiplier: The ratio of runtime dependencies to claimed dependencies, quantifying hidden complexity. "the runtime multiplier (Equation 7) reveals the hidden complexity beneath the surface:"
- SciUnit: A Python tool that captures imports and runtime package usage for provenance. "For Python, we used SciUnit, which hooks into Python's import system to capture every package that gets loaded (Equation 11):"
- SOTA agents: State-of-the-art LLM-based coding systems compared in the study. "To ensure a fair comparison across SOTA agents, we created a dataset of 300 projects"
- Transitive closure: The complete set of dependencies reachable through repeated transitive relations. "runtime dependencies after executing (the complete transitive closure)."
- Transitive dependencies: Packages indirectly required by direct dependencies and loaded at runtime. "including all transitive dependencies."
Collections
Sign up for free to add this paper to one or more collections.