- The paper introduces GCLSS, a framework that combines contrastive learning with spectral seriation to derive robust ordinal rankings in semi-supervised regression tasks.
- It employs a memory-based feature selection module and Laplacian eigenvector analysis to stabilize feature similarity and improve ranking accuracy.
- Experiments validate that GCLSS outperforms existing methods in age estimation, operator learning, and audio quality tasks, achieving notable improvements in R² and MAE.
Contrastive Learning for Semi-Supervised Deep Regression with Generalized Ordinal Rankings from Spectral Seriation
Introduction
This work introduces Generalized Contrastive Learning with Spectral Seriation (GCLSS), a semi-supervised deep regression framework that integrates contrastive learning and ordinal ranking via spectral seriation. The method enables effective utilization of both labeled and unlabeled data, mitigating the reliance on extensive labeled datasets—a critical bottleneck in regression tasks, especially within domains such as medical imaging, age estimation, and operator learning. GCLSS extends prior methods by employing a generalized spectral seriation approach that incorporates labeled data for regularization, yielding robust ordinal pseudolabel supervision for regression on unlabeled samples.
Methodology
Contrastive learning typically leverages label-based pairwise supervision to encode label distance into feature similarity relationships. However, the applicability of existing methods is constrained in semi-supervised regimes due to the scarcity of labeled data. GCLSS confronts this by constructing a composite feature similarity matrix using both labeled and unlabeled samples. Spectral seriation is then applied to recover ordinal rankings, using a Laplacian eigenvector (Fiedler vector) approach to approximate the latent order of unlabeled data.
Unlike standard seriation, the proposed generalization considers the confounding influence of labeled samples on ordinal rank recovery. The Laplacian is partitioned into labeled/unlabeled blocks, and a closed-form ranking solution is obtained by projecting the label-informed Fiedler vector onto the unlabeled sample space. Ranking regularization for unlabeled samples is enforced through a differentiable unsupervised contrastive loss (LUC) and additional pseudo-ranking supervision (LUR), resulting in more congruent ordinal structure of the learned embedding.
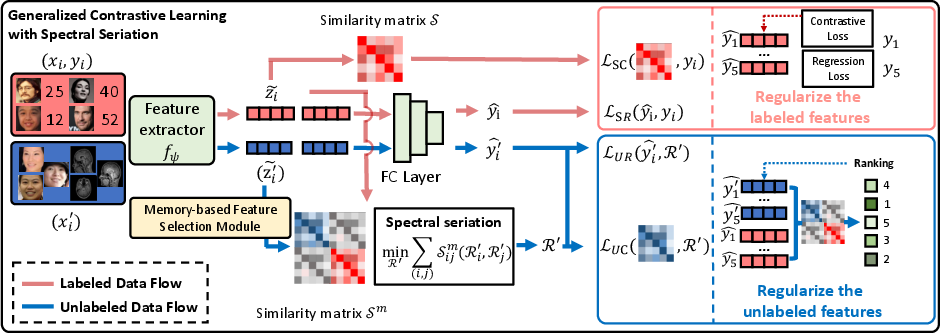
Figure 1: The GCLSS framework enables spectral seriation over mixed labeled/unlabeled batches, yielding robust ranking supervision for unlabeled samples.
To counter instability in the feature similarity matrix, GCLSS integrates a memory-based feature selection module (MFSM), employing dynamic programming to select features with minimal cross-propagation variance. This dampens ordinal ranking errors arising from noise in unlabeled sample representations, further stabilizing contrastive training.
Theoretical Guarantees
The paper provides formal robustness analyses of the generalized spectral seriation solution, offering perturbation bounds on both the similarity matrix and the feature representations. Theorems establish that, under bounded perturbations (quantified via Laplacian eigenstructure and singular values), the ordinal ranking recovered from spectral seriation remains invariant to certain levels of input noise. These theoretical results support the use of spectral seriation-derived ranks as reliable pseudo-supervision, even in high-variance semi-supervised regimes.
Experimental Evaluation
GCLSS is rigorously validated on four representative regression tasks:
Ablation studies confirm that both the incorporation of labeled data into ordinal ranking and the MFSM are independently contributory. Increasing the batch size of unlabeled samples and the total number of selected features yields non-monotonic effects—there exists an optimal threshold for maximal ranking reliability, aligning with theoretical perturbation bounds.
Implications and Future Directions
GCLSS demonstrates practical efficacy in reducing annotation dependence while preserving ordinal structure in regression embeddings. The method generalizes across images, audio, and synthetic data, highlighting its extensibility beyond standard metric regression. The use of spectral seriation as a backbone for ranking-based pseudo-supervision introduces a promising avenue for future research—potentially applicable to other tasks requiring robust ordinal inference under weak supervision.
Theoretical perturbation invariance motivates further exploration toward large-scale semi-supervised learning, potentially integrating more sophisticated uncertainty modeling or kernelized seriation. Additionally, GCLSS may be adapted to integrate multimodal or hierarchical ranking inferencing, benefiting broader domains in scientific and industrial regression scenarios.
Conclusion
GCLSS advances semi-supervised deep regression by combining contrastive learning with generalized ordinal ranking recovery from composite batches. Through spectral seriation regularized by ground-truth labeled samples and feature-level memory-based selection, it achieves state-of-the-art regression performance under stringent labeling constraints. Theoretical analyses and cross-domain experiments validate its robustness and generalizability, substantiating GCLSS as a practical framework for scalable, annotation-efficient regression modeling.
