- The paper proposes a depth-only approach employing sparse 3D voxel representations and staged heatmap strategies for high-resolution 6D pose estimation.
- The methodology integrates a Sparse Transformer Block with dual-branch attention, enhancing detection of occlusions and clutter in industrial bin picking.
- Experiments demonstrate robust performance on challenging datasets, highlighting a balanced trade-off between precision and computational efficiency.
Introduction
The paper introduces a novel depth-only approach for 6D pose estimation tailored to industrial multi-view bin picking scenarios, a process fraught with challenges such as occlusions, cluttered environments, and reflective surfaces. By leveraging sparse 3D encodings and a staged heatmap strategy, the proposed SDT-6D framework effectively focuses computational resources on areas of interest, achieving high-resolution pose estimation while maintaining computational efficiency. This paper's contributions lie in balancing fidelity and operational efficiency through adaptive, scene-dependent processing.

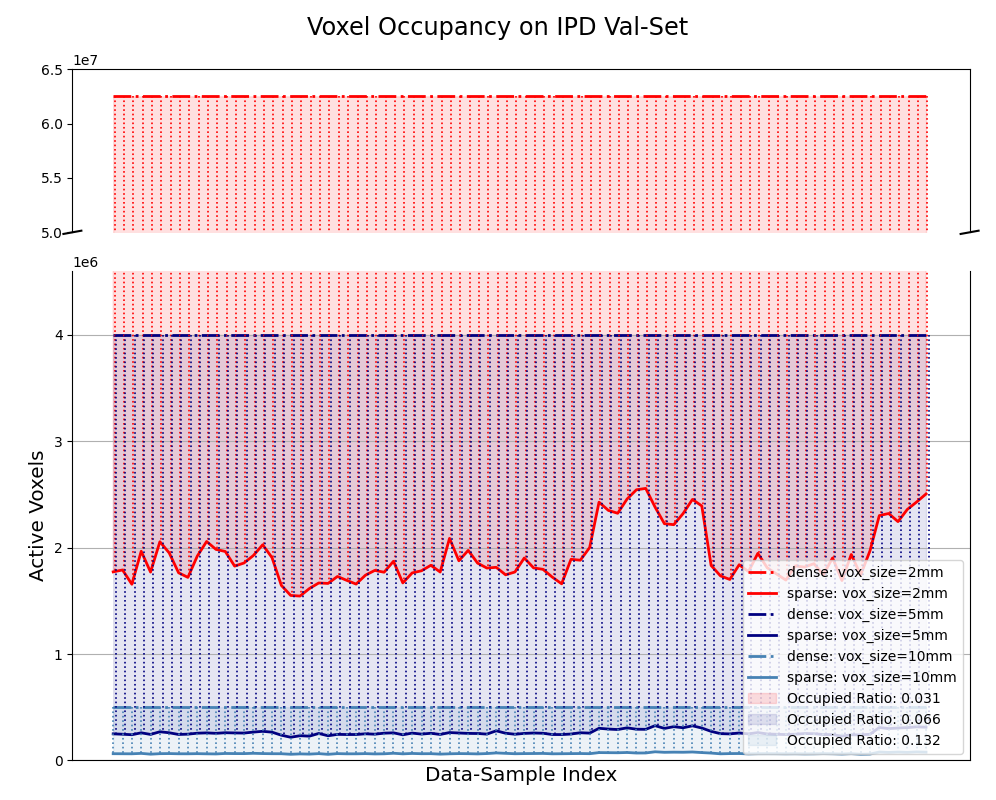
Figure 1: Voxel occupancy statistics on the IPD dataset demonstrating efficient 3D sparse representation.
Methodology
Sparse 3D Representation
The SDT-6D framework begins by fusing multi-view depth maps into a sparse voxel grid. This fusion can be implemented either through a fine-grained 3D point cloud or a sparse TSDF. The sparse representation, when coupled with a high-resolution voxel grid, captures intricate spatial details crucial for pose identification without the prohibitive memory costs typical of dense grid structures (Figure 1).
RoI and Objectness Heatmap
A dual-stage heatmap strategy hierarchically extracts foreground regions of interest. The RoI Heatmap leverages a sparse U-Net architecture to provide global context features and importance scores, facilitating the focus on significant voxels while eliminating irrelevant background data (Figure 2). The Objectness Heatmap operates on these filtered features, identifying target object voxels and further refining the data to maintain necessary geometrical details through soft attention and adaptive thresholding techniques.
Figure 2: Overview of the proposed framework architecture demonstrating high-resolution voxel processing and key feature extraction.
The system incorporates a Sparse Transformer Block, enhancing its ability to address the inherent challenges in cluttered bin-picking tasks. This block uses dual-branch attention mechanisms with varying window sizes to extract and integrate fine-grained and contextual information. This design facilitates the resolution of occlusions and the distinguishing of overlapping artifacts present in cluttered environments (Figure 3).
Figure 3: A Sparse Transformer Block executes multi-head self-attentions capturing both fine details and neighborhood contexts.
Experimental Evaluation
The proposed SDT-6D framework shows competitive performance on both the IPD and MV-YCB-SymMovCam datasets, excelling in accurately estimating poses in crowded industrial scenes. The experiments validate the framework's efficacy, particularly its robust adaptation to high-resolution inputs and its proficiency in maintaining geometric detail in adverse conditions. The results highlight substantial improvements over traditional dense and indiscriminate scene reduction techniques, demonstrating SDT-6D's formidable balance between precision and computational efficiency.
Limitations and Future Work
While effective, the current depth-only approach may encounter difficulties with objects lacking geometric expressiveness or those significantly affected by sensor noise. The inclusion of RGB data to supplement the depth information could potentially overcome these limitations, offering a broader application spectrum and increased robustness in varying visual conditions.
Conclusion
SDT-6D offers an innovative solution to 6D pose estimation, efficiently integrating sparse data processing techniques with a sophisticated staged heatmap strategy to manage the challenges of bin-picking scenes. With immediately practical applications in robotics and industrial automation, the SDT-6D framework marks a substantive advancement in pose estimation strategies, paving the way for further developments that integrate color data for enhanced performance.


