JEPA as a Neural Tokenizer: Learning Robust Speech Representations with Density Adaptive Attention
Abstract: We introduce a two-stage self-supervised framework that combines the Joint-Embedding Predictive Architecture (JEPA) with a Density Adaptive Attention Mechanism (DAAM) for learning robust speech representations. Stage~1 uses JEPA with DAAM to learn semantic audio features via masked prediction in latent space, fully decoupled from waveform reconstruction. Stage~2 leverages these representations for efficient tokenization using Finite Scalar Quantization (FSQ) and a mixed-radix packing scheme, followed by high-fidelity waveform reconstruction with a HiFi-GAN decoder. By integrating Gaussian mixture-based density-adaptive gating into the JEPA encoder, the model performs adaptive temporal feature selection and discovers hierarchical speech structure at a low frame rate of 2.5~Hz. The resulting tokens (47.5 tokens/sec) provide a reversible, highly compressed, and language-model-friendly representation that is competitive with, and often more efficient than, existing neural audio codecs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching a computer to listen to speech and turn it into simple, reusable “tokens” (think small building blocks), without needing any text labels. These tokens are compact, reversible back into sound, and easy for LLMs to work with. The authors combine two ideas:
- JEPA, which learns to predict hidden parts of a representation instead of rebuilding the raw sound, and
- DAAM, a special kind of attention that focuses on the most informative moments in audio based on statistics.
Together, they make a strong speech “neural tokenizer” that compresses speech into a small number of tokens per second while keeping enough detail to rebuild high-quality audio later.
Key Objectives
The paper sets out to answer simple but important questions:
- How can we learn speech features that capture meaning (like words and intonation) without being distracted by tiny waveform details?
- Can we make tokens that are small, reversible, and friendly for LLMs to use?
- Does using density adaptive attention (DAAM) help the model focus on the right parts of speech?
- Can we reconstruct good-sounding audio from these compact tokens?
How They Did It
The method has two stages. Here’s an everyday way to think about each stage:
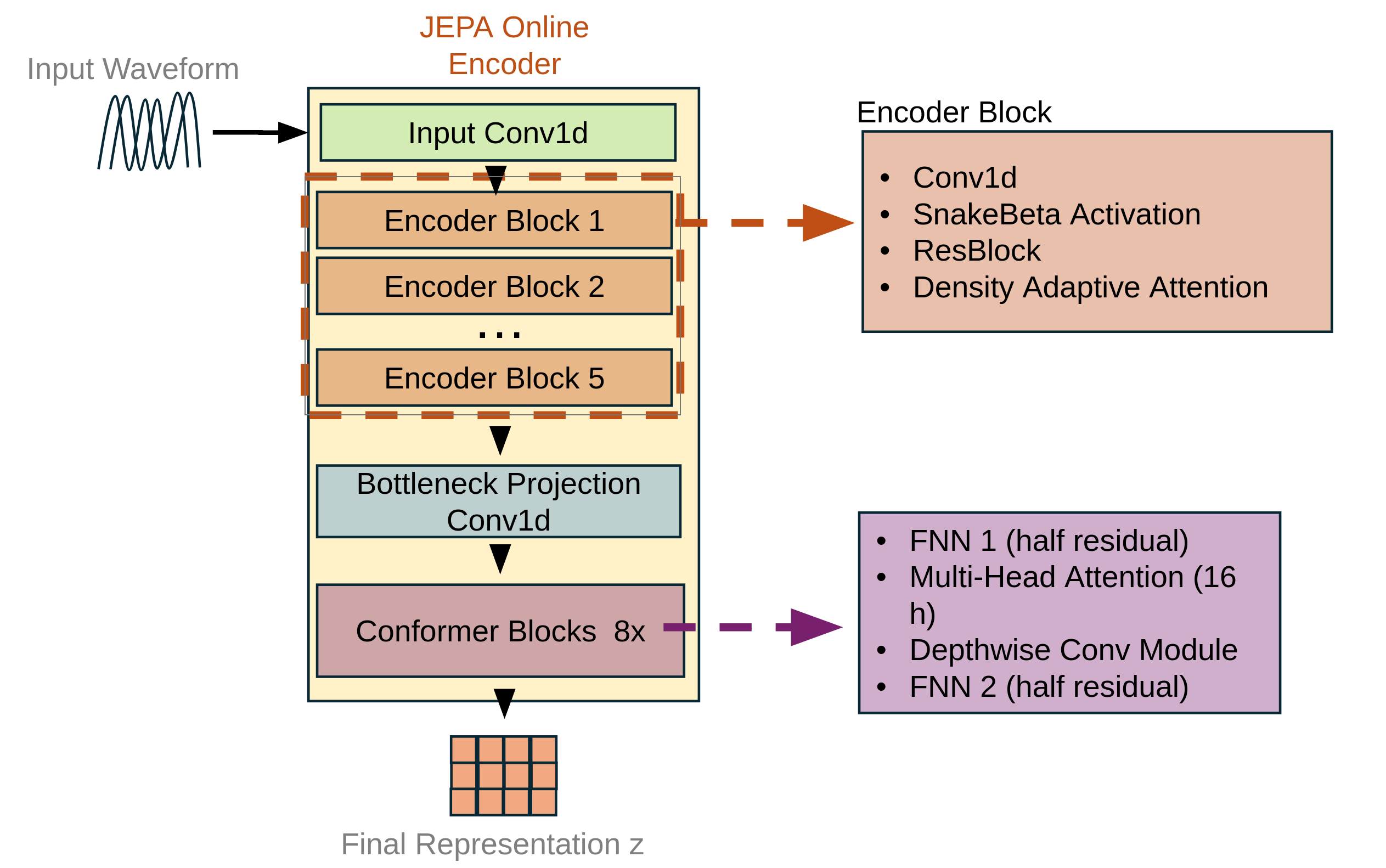
Stage 1: Learning meaningful speech features (JEPA + DAAM)
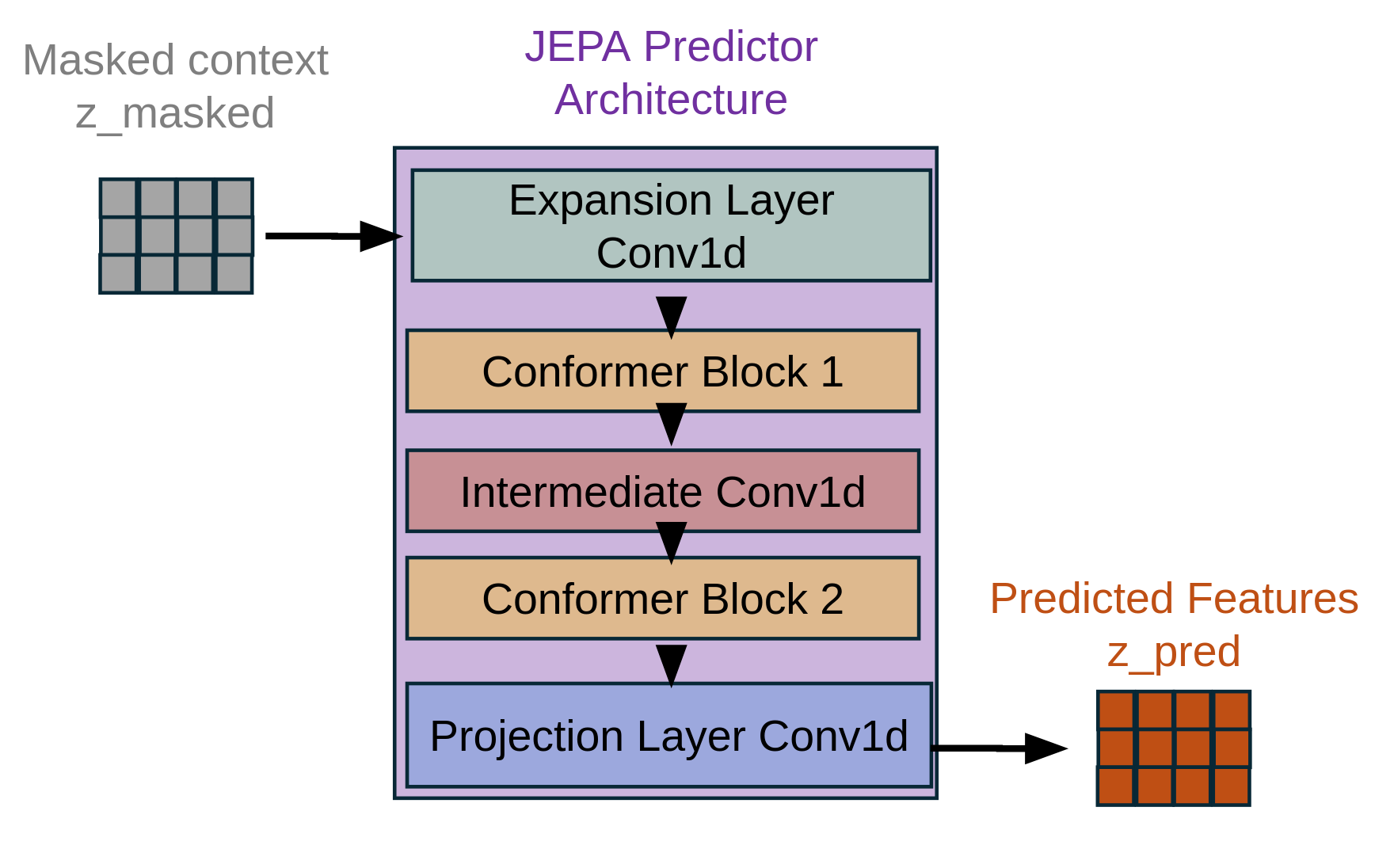
- Imagine you have a comic strip and you cover some panels with sticky notes. Your task is to guess what’s underneath by looking at the surrounding panels. That’s what JEPA does: it “masks” parts of an internal representation and learns to predict them from the visible parts. This trains the encoder to understand the speech’s meaning and structure.
- Instead of rebuilding the raw waveform right away, the model works in a simpler “feature space” (like a summary of the sound), which helps it learn semantic content (what’s being said and how) rather than fine-grained noise.
- DAAM acts like a smart spotlight that brightens time segments that look statistically “interesting” or informative. Instead of comparing every moment to every other moment (which can be slow and noisy), DAAM looks for patterns that stand out using a learned mix of Gaussian distributions (you can think of these as bell-shaped curves that describe common vs. unusual signal behaviors).
- A “teacher–student” setup keeps training stable: the online encoder learns and updates normally, while a target encoder is updated slowly (like a calm mentor) using an exponential moving average. The student predicts the masked parts to match the mentor’s features.
Result: The encoder ends up with low-rate, high-level speech features at about 2.5 frames per second, which is extremely compact.
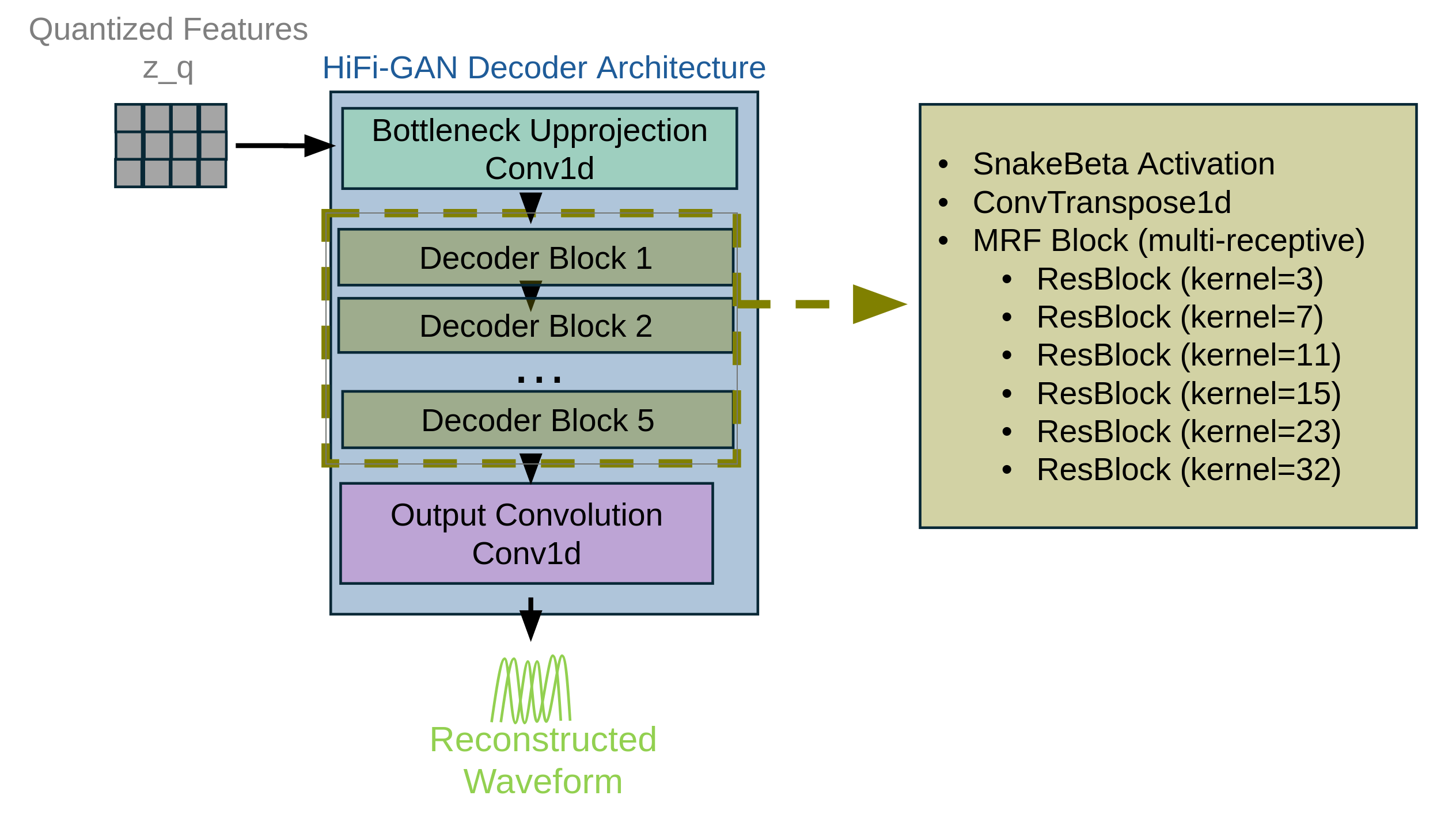
Stage 2: Turning features into tokens and back into sound (FSQ + mixed-radix packing + HiFi-GAN)
- FSQ (Finite Scalar Quantization) is like snapping numbers to the nearest step on a ruler. It turns continuous features into discrete levels without learning a big codebook, which keeps things simple and stable.
- Mixed-radix packing is like putting several small dials into one big number. It bundles groups of FSQ indices together to reduce how many tokens we need every second.
- With the chosen settings, the system produces about 47.5 tokens per second, each token chosen from a 16,384-item vocabulary. This is small enough for LLMs to handle efficiently.
- To go back from tokens to sound, they use HiFi-GAN, a high-quality audio generator that upsamples features into a waveform. Think of it as a smart audio “builder” that reconstructs full speech from the compact instructions.
Main Findings and Why They Matter
Here are the most important observations from the paper:
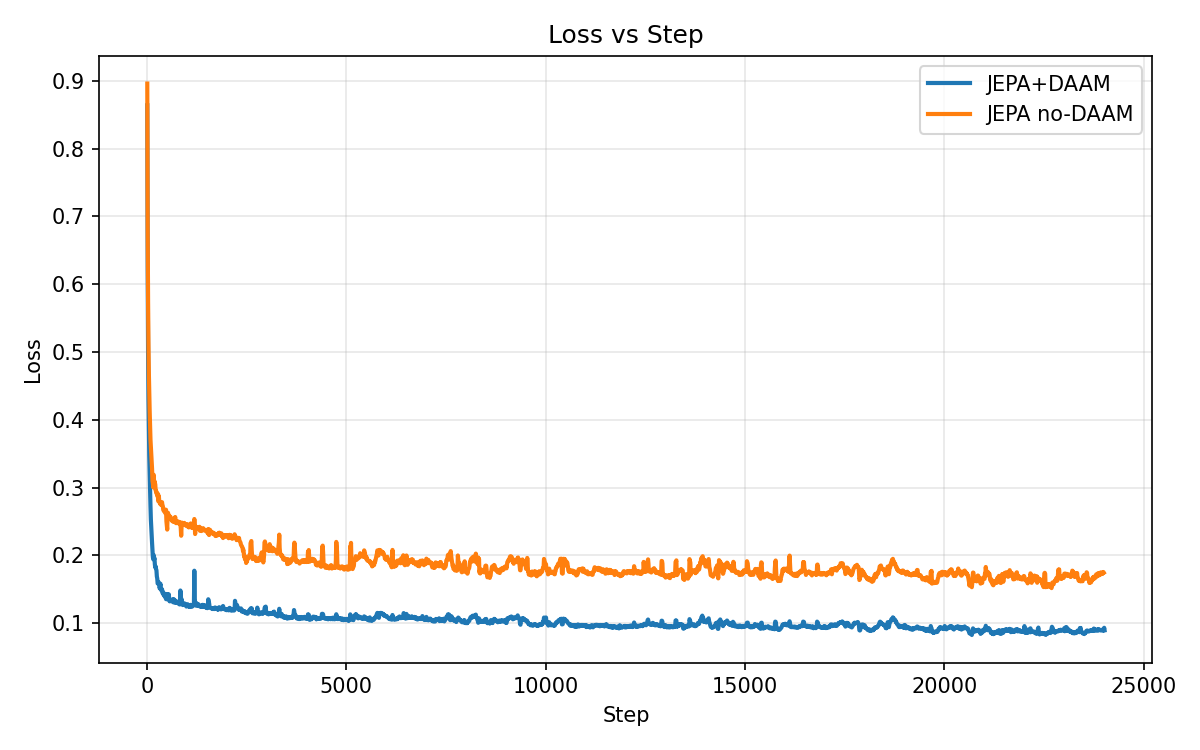
- DAAM helps JEPA learn faster and better: When DAAM is added, the training loss drops more and more quickly compared to JEPA alone. This suggests the model is focusing on the most useful parts of the signal.
- Very low frame rate, but still rich: Features are stored at just 2.5 frames per second, which is much lower than many popular audio codecs (often 75+ frames/sec). This makes the tokens more compact and efficient.
- Tokens are reversible and language-model-friendly: The packed tokens can be turned back into the original quantized features exactly, and their vocabulary size is similar to subword vocabularies used in text models. That makes them easy to plug into language-model-based speech systems.
- Good reconstruction using a standard decoder: HiFi-GAN, guided by reconstruction and spectral losses (plus a small adversarial “GAN” component), produces high-quality audio from the tokens.
Why this matters:
- Compact tokens reduce storage and speed up modeling.
- Separating “understand speech” from “rebuild audio” avoids mixing goals and leads to cleaner, more useful representations.
- The approach works without labeled data, so it can scale to huge unlabeled speech collections.
Implications and Impact
In simple terms, this work shows how to turn speech into clean, compact tokens that:
- Make it easier to build speech systems powered by LLMs (like talking assistants or text-to-speech that understand context).
- Save bandwidth and storage for streaming or communication while keeping quality high.
- Generalize across tasks, because the learned features focus on meaning rather than just the raw waveform.
- Encourage future research on smarter attention (like DAAM) and on low-rate token streams for audio, which could make voice applications faster, cheaper, and more accurate.
In short, the paper offers a practical recipe for learning robust speech features and compact, reversible tokens. It suggests a path toward speech models that are both efficient and easy to combine with powerful LLMs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps, uncertainties, and unexplored directions left unresolved by the paper. Each item is framed to be actionable for future research.
- Quantitative benchmarking is absent: no objective rate–distortion curves or standardized audio quality metrics (e.g., PESQ, STOI, SI-SDR, MUSHRA/MOS), making it impossible to verify claims of competitiveness vs. state-of-the-art codecs.
- Effective bitrate is not reported: with 16,384-way tokens (≈14 bits/token) at 47.5 tokens/sec, the implied raw rate is ≈665 bits/sec, but the paper does not compute or validate the actual bitrate (including packing, headers, or streaming overhead) or compare it to typical codec bitrates (e.g., 6–24 kbps).
- No controlled baseline comparisons at matched bitrates/frame rates: missing head-to-head evaluations against EnCodec, SoundStream, DAC, DualCodec, Mimi, and U-Codec under identical conditions (dataset, bitrate, sample rate, latency).
- No downstream task evaluations: the usefulness of JEPA+DAAM tokens is untested for ASR (phoneme/word error rates), TTS (MOS, prosody metrics), voice conversion (speaker similarity), or speaker ID/diarization.
- Prosody and temporal fidelity at ultra-low frame rate remain unverified: impact on F0 tracking (F0 RMSE, V/UV error), timing (duration/phone boundary accuracy), and fine acoustic events (coarticulation, consonant bursts) is not measured.
- Token semantics and alignment are unknown: whether tokens correspond to phonemes, syllables, or higher-level units is not analyzed (e.g., via forced alignment, ABX tests, mutual information with text).
- Content–speaker disentanglement is untested: the claim that decoupling representation learning from reconstruction improves semantic content is not validated by measuring speaker leakage or content/speaker separability in tokens.
- Language and domain generalization are unassessed: only LibriLight (English) is used; performance on tonal, morphologically rich languages, noisy/far-field recordings, varied microphones, and telephony (8/16 kHz) is unknown.
- Robustness to non-speech audio is not examined: behavior on music, environmental sounds, and mixed speech/non-speech content is unreported.
- Mixed-radix packing design trade-offs are unexplored: the effects of group size G, radix choices, and the presence of radix-1 “padding” groups on compression efficiency, LM sequence length, and vocabulary utilization are not analyzed.
- Error resilience in decoding is unaddressed: no strategy for detecting or correcting invalid or out-of-range tokens, nor mechanisms for checksum/CRC, entropy coding, or robustness to LM-prediction errors.
- FSQ configuration lacks justification and ablation: the choice of levels [4,4,4,4], code dimension C=128, and tanh projection are not motivated; sensitivity analyses on quantization levels, code dimension, and pre-/post-projection are missing.
- Dimensionality reduction details are unclear: the paper does not specify how encoder features of 512 channels are mapped to the 128-dimensional FSQ code (e.g., learned linear projection, bottleneck design), hindering reproducibility.
- JEPA masking hyperparameters are fixed and unstudied: effects of mask ratio, span length distribution, and boundary-aware/adaptive masking (e.g., syllable/phoneme boundaries) on learned representations are not evaluated.
- DAAM design choices are not ablated: number of Gaussians K, modulation strength α, gating placement (pre/post Conformer) and a noted textual inconsistency about where DAAM is applied require clarification and systematic ablation.
- Training stability and collapse prevention are insufficiently analyzed: Stage 1 uses only MSE with EMA; beyond a simple std-dev monitor, there is no investigation of collapse modes, augmentation strategies, or regularizers (e.g., variance/moment constraints).
- Efficiency and latency are not measured: real-time factor (RTF), GPU/CPU throughput, memory footprint, and end-to-end/streaming latency (given 0.4 s frame hops) are not reported, especially under mixed precision with FP32 DAAM ops.
- Streaming and causal operation are not addressed: how to tokenize and decode with low latency (e.g., overlap-add, shorter hops, causal encoders/decoders) while preserving quality remains open.
- HiFi-GAN decoder DAAM usage is not evaluated: the impact of DAAM in decoder residual blocks on reconstruction quality and stability is not quantified via ablation.
- Loss design in Stage 2 lacks exploration: the choice and weighting of L1, multi-resolution STFT, GAN, and feature matching losses are not ablated nor compared to perceptual/psychoacoustic objectives.
- Parameter count inconsistencies need clarification: reported counts (e.g., JEPA encoder 121.7M vs. “JEPA encoder 240.2M” in Stage 2) and the final 191.0M inference model require reconciliation and detailed breakdowns.
- LLM integration is proposed but not demonstrated: no experiments on training decoder-only LMs over the token stream (perplexity, NLL, sample quality), text-conditioned generation, or multimodal prompting are provided.
- Privacy and safety are not studied: tokens are reversible; risks of speaker identity leakage and potential for anonymization or privacy-preserving variants (e.g., de-identification) are not evaluated.
- Dataset curation and augmentation are minimal: there is no analysis of how data quality, noise augmentation, speed/pitch perturbations, or speaker balancing influence representation robustness.
- Reproducibility details are missing or ambiguous: certain modules (e.g., “GAttnGateG,” SnakeBeta hyperparameters, exact Conformer configurations, dropout rates) and training schedules lack precise specification.
- Cross-modal JEPA extensions are only suggested: concrete architectures, datasets, and objectives for audio–text or audio–visual joint embeddings are not explored experimentally.
- Token utilization and entropy are unmeasured: no report on token frequency distribution, entropy, redundancy, or compression efficiency (e.g., via entropy coding) across datasets and speakers.
- Failure cases and qualitative diagnostics are limited: the paper lacks error analyses (e.g., where reconstruction fails, which phonetic classes degrade), making targeted improvements difficult.
- Generalization with larger compute/data scale is unknown: results are based on relatively small training budgets; scaling laws (performance vs. data/model size) are not studied.
Practical Applications
Practical, Real-World Applications of “JEPA as a Neural Tokenizer: Learning Robust Speech Representations with Density Adaptive Attention”
Below are actionable use cases derived from the paper’s methods and findings. Each item includes sector(s), examples of tools/products/workflows that could emerge, and key assumptions/dependencies affecting feasibility.
Immediate Applications
These can be prototyped or deployed now, leveraging the released code and established components (JEPA+DAAM encoder, FSQ with mixed-radix packing, HiFi-GAN decoder).
- Neural speech tokenizer SDK for generative audio models (software, media/entertainment)
- What: Use JEPA+DAAM as a plug-in “speech tokenizer” to produce discreet, language-model-friendly tokens (47.5 tokens/sec; 16,384 vocabulary via mixed radix) for TTS and speech generation.
- Tools/workflows: “Audio-to-tokens” API; training recipe for decoder-only Transformers on packed FSQ tokens; inference pipeline tokens → dequantization → HiFi-GAN.
- Assumptions/dependencies: English-only pretraining (LibriLight); quality of HiFi-GAN reconstruction; training data alignment if conditioning on text; GPU/accelerator availability for real-time decoding.
- Low-bandwidth voice streaming and archival codec (telecom, media/CDN, storage)
- What: Replace higher frame-rate neural codecs (e.g., 75 Hz) with mixed-radix FSQ tokens at 2.5 Hz frames to reduce bandwidth/storage while remaining reversible.
- Tools/workflows: WebRTC integration (encoder at client, decoder at edge/server); “voice memo” compression in apps; archival pipelines that store tokens and keep decoder checkpoints for future playback.
- Assumptions/dependencies: Latency budgets (encoding/decoding throughput); end-user hardware (mobile/edge GPU) for decoding; robust packetization and error resilience in transport.
- Feature extractor for ASR, diarization, and voice analytics (software, education, accessibility, enterprise analytics)
- What: Use the JEPA+DAAM encoder’s semantic features (decoupled from waveform losses) to fine-tune downstream tasks: ASR, speaker diarization, keyword spotting, topic segmentation.
- Tools/workflows: Frozen or partially fine-tuned encoder feeding task-specific heads; minimal labeled data fine-tuning due to self-supervised pretraining; batch inference over call logs or lectures.
- Assumptions/dependencies: Task-specific labeled data for fine-tuning; domain adaptation beyond LibriLight; evaluation/benchmarking to quantify gains vs. WavLM/other SSL baselines.
- Salience-driven audio analytics via DAAM gating (customer support, finance, compliance operations)
- What: Use DAAM’s density-adaptive gates to identify statistically salient regions in speech for surfacing “interesting” segments (disfluencies, emphasis, anomalies).
- Tools/workflows: Segment highlighting in call center QA dashboards; triage of long audio streams for review; automatic chaptering of podcasts/webinars.
- Assumptions/dependencies: Threshold tuning for gates; domain/calibration to reduce false positives; privacy safeguards in regulated industries.
- Voice conversion and style transfer (prototype-level) (media, creator tools)
- What: Tokens capture semantic content; combining with speaker/style conditioning enables voice conversion and style transfer (JEPA+FSQ → conditioned HiFi-GAN).
- Tools/workflows: Studio plug-ins to change timbre/prosody; A/B auditioning tools for narrator selection; internal experimentation in creative pipelines.
- Assumptions/dependencies: Sufficient conditioning signals for speaker/style; ethical and consent frameworks; decoder quality sufficient for production.
- Efficient dataset compression for research and product telemetry (academia, MLOps, enterprise)
- What: Store tokenized representations instead of raw waveforms to reduce data footprint while keeping reversibility for future model improvements.
- Tools/workflows: Data lake tiering (tokens + metadata + checkpoints); batch reconstruction tools; traceability to training versions.
- Assumptions/dependencies: Long-term retention of decoder versions/checkpoints; governance for reversible compression in sensitive domains.
- Robotics and embedded command understanding (feature-only) (robotics, IoT)
- What: Use JEPA encoder features to feed lightweight command recognition (wake word, intent) without decoding to waveform.
- Tools/workflows: On-device inference pipelines that run encoder → intent classifier; streaming salience cues to prioritize processing.
- Assumptions/dependencies: Model size (191M inference) is large; require pruning/quantization/distillation; domain adaptation for noisy far-field audio.
- Academic prototyping and curriculum use (academia)
- What: Immediate use of the open-source repo to study JEPA, DAAM, FSQ, and mixed-radix packing; build course labs on self-supervised speech.
- Tools/workflows: Repro-friendly scripts; ablation studies (with/without DAAM); token packing experiments; cross-task probing.
- Assumptions/dependencies: Compute availability (A100 or equivalent recommended); familiarity with PyTorch/DeepSpeed; limited to English unless retrained.
Long-Term Applications
These require further research, scaling, productization, and/or validation (e.g., multilingual training, latency/quality guarantees, regulatory frameworks).
- Standardization of JEPA-based neural speech codecs (telecom standards, policy)
- What: Move toward standardized low-frame-rate codecs compatible with LLM workflows and reversible token streams.
- Tools/workflows: 3GPP/ITU proposals; error-resilient packetization; reference decoders; performance benchmarks across languages and codecs.
- Assumptions/dependencies: Broad multi-vendor evaluation; real-world QoS testing; royalty/licensing clarity for deployment.
- Multilingual, code-switching, and tonal language support (global products, education, accessibility)
- What: Train/validate JEPA+DAAM on diverse corpora; ensure robustness across speech rates, prosody, morphology.
- Tools/workflows: Large-scale multilingual self-supervised pretraining; language-specific fine-tuning heads; cultural/linguistic evaluation suites.
- Assumptions/dependencies: Extensive multilingual datasets; compute for scaling; fairness and bias audits.
- Streaming voice LLMs (voice-to-voice agents) (software, customer support, personal assistants)
- What: Autoregressive models that “think in audio tokens,” doing direct speech-to-speech dialog generation at ~47.5 tokens/sec, reducing compute vs. higher-rate codecs.
- Tools/workflows: End-to-end pipeline: encoder → tokens → LM → tokens → decoder; promptable prosody/emotion control; streaming low-latency generation.
- Assumptions/dependencies: Efficient decoding on-device; tight latency budgets; robust alignment for instruction-following; safety moderation for synthetic speech.
- Healthcare voice biomarkers and longitudinal monitoring (healthcare)
- What: Use DAAM-enhanced features to track vocal markers potentially associated with neurological or mental health conditions.
- Tools/workflows: Clinical pipelines for standardized collection; feature stability studies; prospective trials; regulatory submissions.
- Assumptions/dependencies: Clinical validation; IRB/ethics; robust performance across demographics, dialects, comorbid conditions; privacy and informed consent.
- Privacy, safety, and watermarking for synthetic speech (policy, trust & safety)
- What: Token-space watermarking/signatures to flag synthetic speech; de-identification filters (speaker attribute obfuscation) at the feature/token level.
- Tools/workflows: Token-index watermark schemes; speaker attribute suppression modules; audit tools for provenance.
- Assumptions/dependencies: Reliable watermark robustness against post-processing; standards for disclosure; social/legal acceptance.
- Hearing aids and embedded DSP (distilled variants) (healthcare devices, embedded systems)
- What: Distilled/quantized JEPA+DAAM encoders for on-device noise suppression, intent detection, and low-bandwidth transmission to companion devices.
- Tools/workflows: Model compression (pruning, INT8/FP8 quantization); hardware co-design with edge accelerators; battery-life studies.
- Assumptions/dependencies: Significant model shrinkage required; comfort and latency constraints; diverse acoustic environments.
- Cross-modal JEPA (audio–visual/text) (multimodal AI, media)
- What: Joint token spaces for audio+video (lip reading, dubbing) or audio+text (prosody-aware TTS), using the JEPA paradigm to decouple modalities.
- Tools/workflows: Multimodal encoders/predictors; co-tokenization strategies; synchronized decoders for AV alignment.
- Assumptions/dependencies: Large synchronized datasets; training stability in multimodal JEPA; evaluation in real-world tasks.
- Federated/self-supervised learning on unlabeled edge audio (IoT, smart homes)
- What: JEPA pretraining across distributed devices to improve local models without centralizing raw audio.
- Tools/workflows: Federated training with secure aggregation; token-level telemetry; privacy-preserving protocols.
- Assumptions/dependencies: Efficient on-device training; robust privacy guarantees; heterogeneous hardware support.
- Regulatory frameworks for neural codecs and synthetic voice (policy)
- What: Guidelines for disclosure, consent, and provenance when compressing, storing, and generating human-like speech.
- Tools/workflows: Compliance toolkits; audit logging linking token archives to model versions; standardized labels for synthetic audio.
- Assumptions/dependencies: Multi-stakeholder consensus (industry, regulators, civil society); international harmonization.
- Creator tools and post-production suites (media/entertainment)
- What: Professional-grade voice editing (semantic cuts, style transfer, prosody control) built on token-level manipulations.
- Tools/workflows: DAW plug-ins for “token editing”; APIs for automated ADR/dubbing; prosody sliders bound to token features.
- Assumptions/dependencies: Production-quality decoding; user-friendly interfaces; ethics/consent and talent contracts.
In summary, this work’s separation of representation learning (JEPA+DAAM) from reconstruction, coupled with reversible mixed-radix FSQ tokenization at a very low frame rate, enables immediate prototyping of efficient speech tokenizers and codecs, while opening longer-term pathways to standardized, multilingual, privacy-aware, and multimodal voice AI systems. Key feasibility factors include multilingual training, decoder fidelity/latency, model compression for edge, robust evaluation vs. existing codecs, and governance for synthetic speech.
Glossary
- AdamW: An optimizer that decouples weight decay from gradient updates for better training stability. "Optimizer: AdamW with , ."
- Block Masking Algorithm: A procedure that creates contiguous masked spans in time for self-supervised prediction tasks. "Block Masking Algorithm."
- Conformer: A convolution-augmented Transformer architecture tailored for speech modeling. "We use 8 Conformer layers with 16 attention heads."
- Convolutional--Transformer Hybrid Design: An encoder architecture that combines strided convolutions with Transformer-like blocks. "Convolutional--Transformer Hybrid Design"
- Conv1D: One-dimensional convolution used to process temporal audio signals. "passes through Conv1D blocks with stride"
- ConvTranspose1D: A transposed convolution used for upsampling in the decoder. "are upsampled via ConvTranspose1D blocks"
- DAAM (Density Adaptive Attention Mechanisms): Attention mechanisms that modulate features based on learned density (Gaussian mixture) statistics. "Density Adaptive Attention Mechanisms (DAAM)"
- DeepSpeed: A library for efficient distributed training of large models. "DeepSpeed integration for distributed training."
- DensityAdaptiveAttention: A module that computes attention gates via a mixture of Gaussians over temporal statistics. "the DensityAdaptiveAttention module"
- Depthwise convolution: A convolution that operates separately on each input channel, reducing computation in attention/convolution blocks. "depthwise convolution"
- EnCodec: A neural audio codec for high-fidelity compression and reconstruction. "EnCodec (24\,kHz) \citep{Defossez2022EnCodec}"
- Exponential Moving Average (EMA): A momentum-based parameter update that stabilizes target networks during training. "Parameters are updated via exponential moving average (EMA)."
- EMA Target Update: The training step that updates the target encoder via EMA after each optimization step. "EMA Target Update"
- Finite Scalar Quantization (FSQ): A fixed scalar quantization scheme that avoids learned codebooks for efficient tokenization. "FSQ provides efficient discrete tokenization without codebook learning \citep{Mentzer2023FSQ}."
- GAttnGateG modules: Gating modules that project features and apply DAAM-based scaling after Conformer blocks. "features pass through GAttnGateG modules that:"
- Gaussian mixture-based density-adaptive gating: A gating mechanism that uses a mixture of Gaussians to scale features based on temporal salience. "By integrating Gaussian mixture-based density-adaptive gating into the JEPA encoder"
- Hann window: A windowing function used in STFT computation to reduce spectral leakage. "Window: Hann."
- HiFi-GAN: A GAN-based neural vocoder/decoder for high-fidelity waveform synthesis. "high-fidelity waveform reconstruction with a HiFi-GAN decoder."
- Horner's method: An efficient algorithm for evaluating polynomials, used here for mixed-radix token encoding. "Using Horner's method \citep{MixedRadixKnuth1997}:"
- Joint-Embedding Predictive Architecture (JEPA): A self-supervised framework that predicts masked latent representations rather than reconstructing inputs. "combines the Joint-Embedding Predictive Architecture (JEPA) \citep{Assran2023IJEPA} with Density Adaptive Attention Mechanisms (DAAM)"
- LibriLight: A large-scale unlabeled speech dataset used for self-supervised training and evaluation. "LibriLight (large-scale unlabeled English speech corpus) \citep{Kahn2020LibriLight}."
- logsumexp: A numerically stable operation aggregating log-probabilities, used to combine Gaussian components. "\text{logsumexp}({\log p_1(x_t), \ldots, \log p_K(x_t)}) - \log K."
- Mask token: A learned embedding used to replace hidden feature timesteps before prediction. "by replacing hidden timesteps with a learned mask token before the predictor."
- Mixed precision: Training with lower-precision arithmetic (e.g., FP16) for speed and memory efficiency while preserving critical ops in FP32. "Mixed precision: FP16 for forward/backward, FP32 for critical ops."
- Mixed-Radix Token Packing: A method that compacts multiple quantized indices into a single integer token using mixed bases. "Mixed-Radix Token Packing"
- Multi-period discriminator (MPD): A discriminator that evaluates audio across different periodicities in GAN-based training. "$\sum_{d \in \{\text{MPD}, \text{MSD}\}\ \mathbb{E}[(D_d(\hat{x}) - 1)^2].$"
- Multi-receptive-field (MRF) residual blocks: Residual modules with varied kernel sizes to capture multi-scale temporal patterns in the decoder. "Multi-receptive-field (MRF) residual blocks with (optionally) DAAM gating."
- Multi-resolution STFT loss: A reconstruction objective that compares generated and reference audio across multiple STFT configurations. "Multi-resolution STFT loss \citep{Yamamoto2020ParallelWaveGAN}."
- Multi-scale discriminator (MSD): A discriminator that evaluates audio at different time scales in GAN training. "$\sum_{d \in \{\text{MPD}, \text{MSD}\}\ \mathbb{E}[(D_d(\hat{x}) - 1)^2].$"
- SnakeBeta activations: Periodicity-friendly activation functions aiding high-fidelity audio generation. "SnakeBeta activations provide periodic inductive bias for high-fidelity audio generation \citep{Ziyin2020Snake}."
- Spectral convergence: A metric in STFT loss measuring the relative error of reconstructed spectrogram magnitudes. "with spectral convergence"
- Stop-gradient operation: A training operation that prevents gradient flow through certain tensors, stabilizing target representations. " denotes the stop-gradient operation."
- Straight-through estimator: A gradient approximation used to train models with non-differentiable quantization. "Straight-through estimator."
- U-Codec: An ultra low frame-rate neural speech codec optimized for LLM-TTS scenarios. "U-Codec \citep{Yang2025UCodec} & 5~Hz"
- VQ-VAE: A vector-quantized variational autoencoder that uses learned codebooks for discrete representation learning. "Unlike VQ-VAE, which maintains learnable codebooks, FSQ uses fixed scalar quantization per dimension."
- WavLM-Large: A large self-supervised speech model used as a baseline for representation comparisons. "WavLM-Large \citep{Chen2021WavLM}: pre-trained self-supervised model."
Collections
Sign up for free to add this paper to one or more collections.

