- The paper presents a novel framework, MatchGS, that exploits geometry-improved 3D Gaussian Splatting to achieve robust zero-shot semi-dense image matching.
- It introduces a synthetic data generation pipeline with advanced plane-based surface modeling and monocular depth priors, reducing epipolar error by up to 40×.
- The study demonstrates significant zero-shot generalization and competitive performance on benchmarks, improving mean AUC scores by up to 17.7%.
Unlocking Zero-shot Potential of Semi-dense Image Matching via Gaussian Splatting
Introduction
The paper presents MatchGS, a comprehensive framework that leverages and extends 3D Gaussian Splatting (3DGS) for robust, zero-shot semi-dense image matching. The core challenge addressed is the generation of large-scale, geometrically faithful pixel correspondences under significant viewpoint diversity, which is critical for generalizable image matching but insufficiently supported by current datasets and data generation techniques. MatchGS introduces two main technical contributions: a highly controlled synthetic data pipeline based on geometry-improved 3DGS and a novel 2D-3D representation alignment strategy. These capabilities enable the training of 2D matchers exhibiting significantly improved zero-shot generalization and structural robustness.
High-fidelity Free-viewpoint Data Generation
MatchGS utilizes 3DGS as a foundation for generating virtually unlimited image pairs with controlled geometry and photometric properties. The authors systematically address the geometric inconsistencies inherent in standard 3DGS reconstructions—particularly the visual-surface misalignment and rendering-biased depth artifacts—by devising a geometry refinement pipeline. This pipeline integrates advanced plane-based surface modeling, monocular depth prior regularization, and adaptive pre-rendering validation.
The data generation process begins with scene reconstruction using 3DGS refined with monocular depth priors and ℓ1 surface regularization for accurate depth maps. Augmented camera viewpoints are sampled using a perturbation-based scheme, simulating challenging conditions such as extreme baselines and scale variations, followed by stringent pre-rendering checks that automatically reject outlier views.
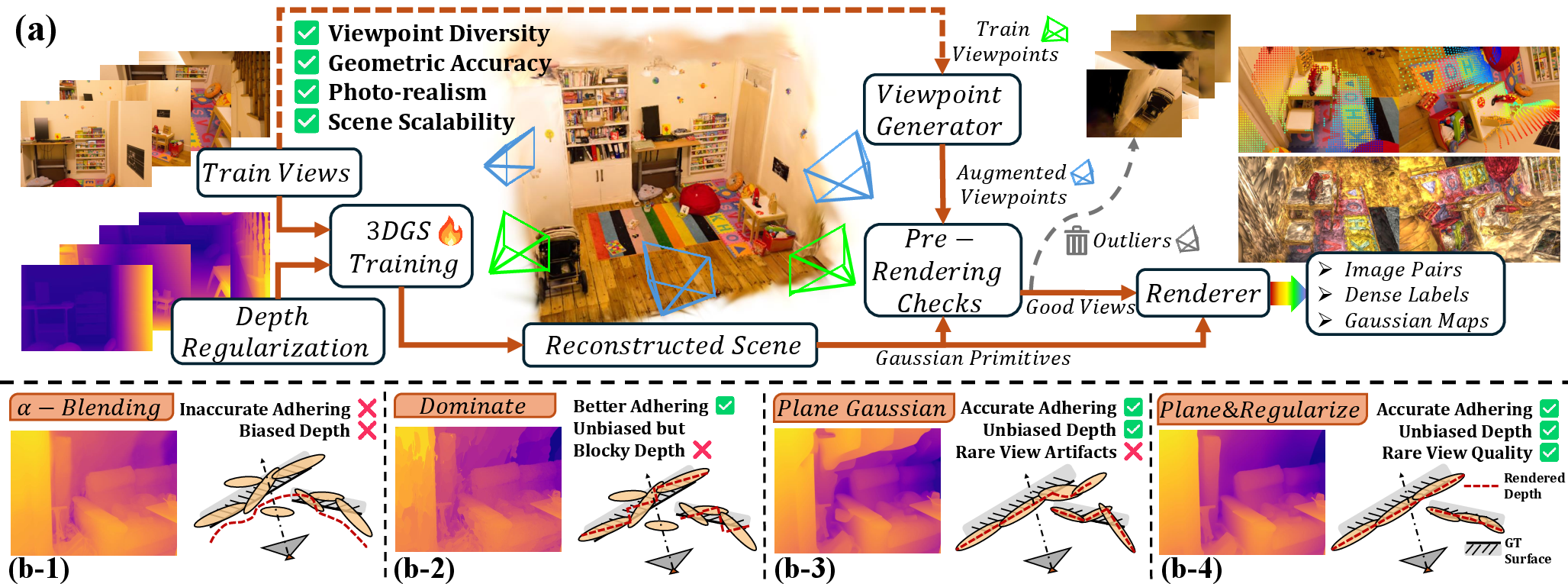
Figure 1: Overview of the MatchGS data generation pipeline and comparison of depth rendering methods.

Figure 2: Visualization of high-density, accurate correspondence labels generated across broad viewpoint and scale changes.
This pipeline produces dense, unbiased, and photorealistic novel views with guaranteed geometric quality. Quantitatively, MatchGS-generated ground-truth pairs demonstrate up to 40× reduction in epipolar error over prevalent datasets such as MegaDepth and ScanNet. This is achieved without requiring any fine-tuning or pre-training on the target evaluation distributions.
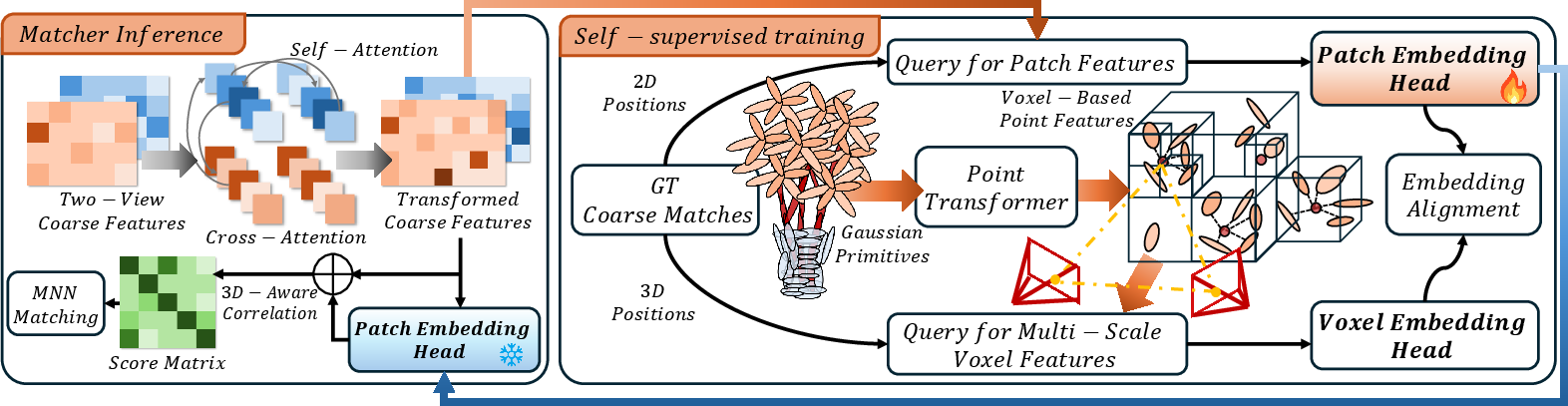
2D-3D Representation Alignment
To further ensure that learned image matchers internalize viewpoint-invariant, physically grounded features, the framework incorporates explicit 2D-3D alignment at both coarse and fine scales. The approach uses transformer-based matchers (e.g., LoFTR, ELoFTR) and introduces two complementary strategies:
This dual-level alignment is shown—through ablation—to strongly enhance the viewpoint invariance and geometrical coherence of the resulting matchers. Notably, coarse-level patch-to-voxel alignment yields the strongest gains in practical robustness due to its stability against Gaussian attribute noise and scene-level scale variation.
Experimental Results
Data Pipeline Evaluation
The authors empirically demonstrate that the refined 3DGS pipeline yields annotations with orders-of-magnitude lower geometric error. By comparing variants of depth rendering (standard alpha blending, dominant primitive, plane-fitting, plane regularization), they establish that their "Plane + regularization" method achieves epipolar errors more than one order lower than MegaDepth and ScanNet.
Zero-shot Generalization
On standard image matching benchmarks, models trained solely on MatchGS data outperform or rival state-of-the-art methods trained with in-domain or hybrid pseudo-label data. Zero-shot evaluation yields:
- Up to +17.7% mean AUC improvement on ScanNet and +16.2% on ZEB (generalization benchmarks) compared to MegaDepth-trained or GIM-trained matchers.
- Superior performance relative to approaches whose training set directly includes the test distribution, highlighting the benefit of genuinely unbiased, yet highly diverse and precise synthetic supervision.
Qualitative results (Figure 4) indicate these models exhibit increased robustness under extreme viewpoint conditions compared to prior art.

Figure 4: Qualitative comparison showing MatchGS matcher stability under extreme viewpoint change in indoor/outdoor imagery.
Downstream Transfer
Without any domain-specific fine-tuning, the MatchGS-trained matchers generalize effectively to homography estimation and 6DoF visual localization, matching or exceeding the performance of specialized alternatives.
Ablation and Failure Analysis
Ablation confirms the importance of both sample diversity (via increased scene count and viewpoint augmentation) and representation alignment. Notably, the fine-scale Gaussian attribute losses do not provide consistent gains due to high intra-scene and inter-scene attribute variance. Failure cases are analyzed on MegaDepth, where the current pipeline's inability to simulate complex real-world lighting and extremely large zoom-factors is explicitly shown as a limitation.

Figure 5: Visualization of success and failure cases on MegaDepth—failures predominantly occur under extreme lighting/scale changes beyond training set diversity.
Statistical Analysis
Scene scale normalization is also addressed, mitigating inter-scene ambiguity by standardizing the logarithm of Gaussian primitive scale factors, thus supporting alignment across non-metric reconstruction scales.
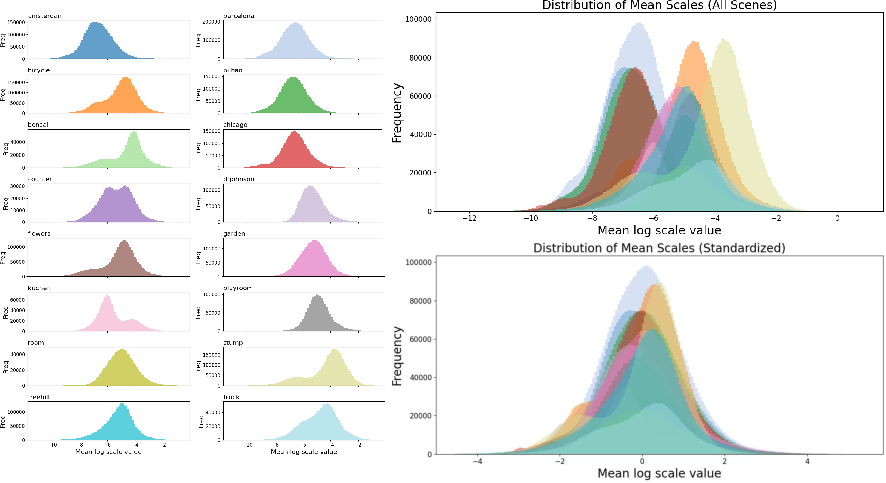
Figure 6: Distribution of Gaussian primitive mean scale factors before and after scene-level standardization, showing reduced inter-scene variance.
Discussion and Implications
MatchGS demonstrates that, when carefully regularized and exploited, explicit 3D geometry from photorealistic generative models provides an unprecedented source for supervisory signals in correspondence learning. This approach not only negates the reliance on hand-crafted or pseudo-labeled real datasets but also enables training protocols that are scalable, automatic, and richly parameterized for difficulty curriculum selection.
Practically, the implications are significant for robust SfM, SLAM, and vision models deployed in unstructured environments. Theoretically, the work affirms that hierarchical 2D-3D alignment can close the gap between data-driven feature extraction and genuine geometric understanding, offering a path towards fully scene-agnostic, zero-shot matching.
Limitations remain in MatchGS's ability to simulate the full continuum of scene illuminations and scale ranges present in the real world. The authors identify relighting and curriculum-based data synthesis as promising directions, together suggesting that future work can further expand the capacity of 3D-aware synthetic data for universal correspondence learning.
Conclusion
MatchGS provides a principled, scalable, and empirically validated framework for zero-shot semi-dense image matching via geometry-improved 3D Gaussian Splatting and 2D-3D representation alignment. The framework establishes new state-of-the-art generalization performance and offers extensive insights into the critical role of explicit geometry and viewpoint diversity in robust matcher development. The broader impact includes a shift towards large-scale, physically grounded synthetic data as a backbone for next-generation vision and robotics systems.
(2511.21265)