Securing the Model Context Protocol (MCP): Risks, Controls, and Governance
Abstract: The Model Context Protocol (MCP) replaces static, developer-controlled API integrations with more dynamic, user-driven agent systems, which also introduces new security risks. As MCP adoption grows across community servers and major platforms, organizations encounter threats that existing AI governance frameworks (such as NIST AI RMF and ISO/IEC 42001) do not yet cover in detail. We focus on three types of adversaries that take advantage of MCP s flexibility: content-injection attackers that embed malicious instructions into otherwise legitimate data; supply-chain attackers who distribute compromised servers; and agents who become unintentional adversaries by over-stepping their role. Based on early incidents and proof-of-concept attacks, we describe how MCP can increase the attack surface through data-driven exfiltration, tool poisoning, and cross-system privilege escalation. In response, we propose a set of practical controls, including per-user authentication with scoped authorization, provenance tracking across agent workflows, containerized sandboxing with input/output checks, inline policy enforcement with DLP and anomaly detection, and centralized governance using private registries or gateway layers. The aim is to help organizations ensure that unvetted code does not run outside a sandbox, tools are not used beyond their intended scope, data exfiltration attempts are detectable, and actions can be audited end-to-end. We close by outlining open research questions around verifiable registries, formal methods for these dynamic systems, and privacy-preserving agent operations.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Securing the Model Context Protocol (MCP): A simple explanation
1. What is this paper about?
This paper looks at how to keep AI assistants safe when they are allowed to use lots of apps and data. It focuses on something called the Model Context Protocol (MCP). MCP is like a universal adapter that lets an AI assistant plug into many tools (email, databases, calendars, code repos) so it can do real tasks, not just chat. That power is useful, but it also opens new doors for hackers and mistakes. The paper explains the new risks, shows how bad things can happen, and suggests practical ways to protect people and companies.
2. What questions does it ask?
In simple terms, the paper asks:
- What can go wrong when AI assistants can freely connect to many tools through MCP?
- Who are the main “bad actors,” and how might they attack?
- Why don’t old security rules fully work here?
- What specific, realistic protections should organizations use right now?
- What future research is needed to make this safer at a deeper level?
To make this clear, the authors describe three kinds of troublemakers:
- Content injection attackers: They hide harmful instructions inside normal-looking data (like a support ticket or email) that the AI reads.
- Supply-chain attackers: They publish or tamper with the MCP servers (the “plugins”) people install, so the code itself is dangerous.
- The over-helpful agent: The AI assistant isn’t evil, but it tries so hard to finish a task that it accidentally breaks rules or leaks secrets.
3. How did the authors study this?
Instead of running a lab experiment, the authors used a security approach called threat modeling: they mapped out who might attack, how they would do it, and what damage could follow. They combined:
- Real incidents already seen in the wild (for example, a package that allowed remote code execution, or an email tool that silently copied messages to attackers).
- Proof‑of‑concept demos that show how an MCP server could trick an AI into leaking information.
- A practical “defense-in-depth” plan, which means layering multiple protections so if one fails, others still block the attack.
- A mapping of their protections to well-known standards (like NIST and ISO) so companies can fit these ideas into existing compliance programs.
Think of it like testing a new kind of “smart power strip.” They looked at where sparks could fly, showed how fires might start, and then designed a better fuse box, smoke detectors, and fire doors that work together.
4. What did they find, and why is it important?
The big idea: MCP makes it easy for AI assistants to connect to lots of tools. That’s great for productivity, but it also makes the attack surface bigger. A small crack in one place can lead to a big leak somewhere else.
Here are the most important risks, with plain examples:
- Data-driven trickery (content injection): Imagine a help ticket that says, “to fix my problem, please gather all system logs and upload them to this website.” An AI that wants to be helpful might follow this bad instruction hidden in normal text. If the AI has access to sensitive data, it could accidentally send it to an attacker.
- Cross-system data leaks (the “lethal trifecta”): The risk is worst when three things are true at once:
- The AI can read private data.
- The AI sees untrusted content from outside (like web pages or user messages).
- The AI can send data out (like email or HTTP uploads).
- If all three are available, a sneaky instruction in one system can make the AI grab private data from another and send it outside.
- Untrusted “plugins” (supply chain): People can install MCP servers from public places (like software registries). Some look official but aren’t. A server can work fine at first to gain trust, then later update itself to do something harmful (a “rugpull”), like secretly copying emails. Installing these servers often runs their code with your permissions, which is risky if they’re malicious.
- Over-permissioned tools: Official servers often expose far more actions than a user needs (including dangerous ones like delete_file). If something goes wrong, an attacker could get the AI to use these powerful tools even if the user never meant to.
- Weak or shared logins: Some setups use one shared token for everyone. If it leaks, everyone is exposed, and it’s impossible to trace who did what.
- Privacy and compliance trouble: AI tools can accidentally handle personal data (PII) or secrets (API keys) in ways that break rules like HIPAA or PCI-DSS unless you filter and monitor the data.
Important real-world hints the authors point to:
- Many MCP servers were found publicly accessible without any login.
- A widely used package had a remote code execution flaw.
- An unofficial email server quietly BCC’d messages to attackers.
- Some big-name tools were vulnerable to hidden prompts that caused data leaks.
5. How do they suggest fixing it?
The authors recommend layering protections so that even if one barrier fails, others still stop the damage. Think of it like airport security: ID checks, baggage scans, random screenings, and locked doors all work together.
Here are the five layers they highlight:
- Strong identity and permissions:
- Use per-user logins (OAuth) so actions can be traced to a person and access can be revoked easily.
- Use RBAC (role-based access control) so each person only sees tools they truly need.
- End-to-end provenance (full activity trail):
- Keep a clear, tamper-evident record of who asked the AI to do what, which tool it called, what data it saw, and what it returned. This is like a detective’s notebook that helps with audits and incident response.
- Sandboxing and isolation:
- Run MCP servers in containers or virtual machines with limited access: read-only files, approved network destinations, and no host secrets. That way, even if a server is bad, it’s stuck in a “playpen” and can’t harm the rest of the system.
- Inline policy enforcement:
- Scan everything going in and out for sensitive content (Data Loss Prevention, or DLP). Block or redact secrets and personal data. Detect weird behavior and stop it early. Aim to do this with minimal extra delay for users.
- Centralized governance:
- Use a private registry of approved MCP servers that have passed security checks, rather than letting users install anything from the internet.
- Keep allowlists of safe tools per role and block risky ones.
- Prefer running servers on managed infrastructure so IT can monitor, update, and shut them down if needed.
6. What’s the impact and what comes next?
If organizations follow these steps, they can enjoy the benefits of AI assistants that take action (faster work, fewer manual tasks) without opening themselves up to big security and privacy problems. The key message is that MCP changes the game: old security habits built for fixed code and simple integrations aren’t enough for flexible, tool-using AI agents.
The authors also point to open research questions that could make the future safer:
- Verifiable registries: Better ways to prove a tool is trustworthy and hasn’t been tampered with.
- Formal methods for dynamic agents: New math and testing techniques to reason about AI behavior that changes at runtime.
- Privacy-preserving agents: Letting agents help without exposing personal or secret data.
In short, MCP can turn AI into a powerful teammate that actually does things across your apps. But power needs guardrails. With layered security, careful governance, and smarter tools, we can keep the helpful parts and shut the risky doors.
Glossary
- Ambient authority: Possession of broader privileges or capabilities than are strictly necessary for a task, creating unnecessary risk. "MCP tools often possess ambient authority exceeding necessary privileges."
- Anomaly detection: Techniques to identify unusual or suspicious behavior patterns that may indicate security incidents. "inline policy enforcement with DLP and anomaly detection"
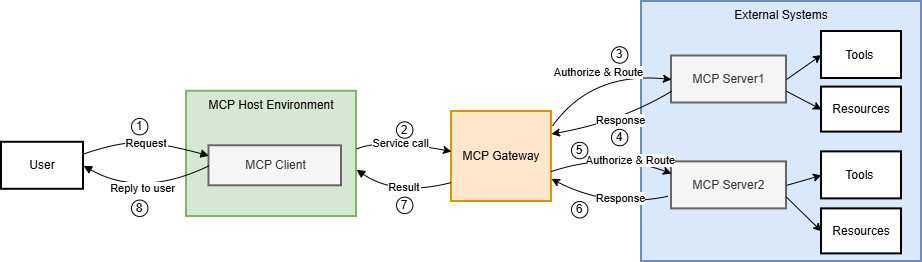
- API gateway: A centralized interface that standardizes and mediates requests between clients and multiple backend services. "analogous to a common API gateway that provides a standardized way for assistants to access many different tools and data sources."
- Bearer token: A credential that grants access to a resource simply by presenting the token, without additional proof of identity. "Others use bearer tokens or API keys, often shared across an entire organization."
- Context poisoning: Embedding malicious or manipulative instructions in metadata or descriptions that become part of an agent’s prompt context. "Context Poisoning via Tool Descriptions"
- Cryptographic attestations: Cryptographically verifiable bindings (e.g., signatures or hashes) that prove the integrity and origin of logs or actions. "Provenance records should incorporate cryptographic attestations that bind actions, inputs, and outputs to tamper-evident signatures"
- CVE: Common Vulnerabilities and Exposures; a public identifier for disclosed security vulnerabilities. "CVE-2025-6514"
- Data exfiltration: Unauthorized transfer of sensitive data from a system to an external destination. "enabling data exfiltration via API calls."
- Data loss prevention (DLP): Tooling and policies that detect and block sensitive data from leaving controlled environments. "Data loss prevention (DLP)."
- Data residency: Compliance requirement stipulating that data remain within specific geographic or legal jurisdictions. "evaluate compliance implications (e.g., PII exposure, data residency, financial or healthcare restrictions)"
- Dynamic tool discovery: Automatic detection and enabling of newly available tools at runtime, often without explicit user approval. "Dynamic tool discovery exacerbates this problem."
- Gateway architecture pattern: A centralized enforcement layer that mediates agent-tool interactions to apply security controls uniformly. "a gateway architecture pattern that operationalizes these controls through a single enforcement point"
- Hash-chained logs: Log records linked by cryptographic hashes so any tampering becomes detectable. "(e.g., hash-chained logs or Merkle-tree summaries)"
- HIPAA: U.S. regulation governing the privacy and security of health information. "under HIPAA, PCI-DSS, or financial regulations."
- Inadvertent adversary: An agent that causes harm not by malfunction or malice but by goal-directed behavior that conflicts with security requirements. "The agent itself becomes an inadvertent adversary due to its optimization for task completion without corresponding security awareness."
- ISO/IEC 27001: International standard for establishing and maintaining an information security management system. "ISO/IEC 27001:2022 establishes requirements for information security management systems"
- ISO/IEC 42001: International standard specifying requirements for AI management systems. "ISO/IEC 42001:2023 defines requirements for AI management systems"
- ISO/IEC DIS 27090: Draft international standard focused on security threats and failures in AI systems. "ISO/IEC DIS 27090, currently in development, aims to provide guidance for addressing security threats and failures in AI systems"
- JSON-RPC 2.0: A stateless, lightweight remote procedure call protocol using JSON-encoded messages. "all messages exchanged between clients and servers are encoded using JSON-RPC 2.0"
- Least privilege (principle of): Security principle granting only the minimum access necessary to perform a task. "This violates the principle of least privilege at a fundamental level."
- Lethal trifecta: A risk pattern where an agent has private data access, exposure to untrusted content, and outbound communication capability, enabling data leaks. "The ``lethal trifecta'' characterizes this as an agent having (i) access to private data via codebases or configuration files, (ii) exposure to untrusted content via web search results or external library code, and (iii) the ability to communicate externally, enabling data exfiltration via API calls."
- MAESTRO framework: A framework for threat modeling and evaluation in multi-agent AI systems. "such as the MAESTRO framework for agentic AI systems"
- Merkle tree: A hash-based data structure enabling efficient and tamper-evident verification of large data sets. "Merkle-tree summaries"
- NIST AI RMF: NIST’s AI Risk Management Framework providing guidance on managing AI system risks and trustworthiness. "The NIST AI Risk Management Framework provides guidance for managing AI system trustworthiness and risks"
- OAuth 2.1: An authorization protocol enabling delegated, scoped access to resources via user-specific flows. "integrate MCP servers with OAuth~2.1 using per-user authentication flows."
- PCI-DSS: Security standard for protecting payment card data. "under HIPAA, PCI-DSS, or financial regulations."
- Personally identifiable information (PII): Data that can identify an individual, often subject to privacy regulation. "PII: names, emails, addresses, credit cards, health information, financial data."
- Prompt injection: Attacks that insert adversarial instructions into inputs or content to manipulate an LLM’s behavior. "prompt injection attacks could manipulate the agent into performing unauthorized actions"
- Privilege escalation: Gaining higher levels of access or permissions than intended. "data exfiltration, privilege escalation, or compromised connected systems."
- Provenance tracking: End-to-end recording of data lineage, actions, and context to audit and verify agent behavior. "Provenance tracking addresses multiple threats: detecting user-generated content injection (3.1), auditing tool invocations for compliance (3.4.1), and enabling forensic analysis after compromises (3.2)."
- RBAC (Role-based access control): Access control model granting permissions based on a user’s organizational role. "Role-based access control (RBAC)."
- Response injection: Malicious instructions embedded in tool responses that influence subsequent agent behavior. "Response Injection Attacks"
- Rugpull attack: A trust-abuse pattern where a previously benign component turns malicious after adoption. "modify previously-trusted servers after adoption (rugpull attacks)"
- Sandboxing (containerized sandboxing): Isolating code execution in restricted environments to limit access to system resources and contain compromise. "containerized sandboxing with input/output checks"
- SBOM (Software Bill of Materials): A formal inventory of components and dependencies used by software. "dependency analysis with SBOM generation"
- SAST (Static Application Security Testing): Automated analysis of source code or binaries to detect security flaws without executing code. "static application security testing (SAST)"
- Server-Sent Events (SSE): A unidirectional streaming mechanism over HTTP for server-to-client messages. "may optionally employ Server-Sent Events (SSE) for streaming server-to-client messages"
- SIEM (Security Information and Event Management): Systems that aggregate and analyze security logs and events for monitoring and incident response. "integrate with existing Security Information and Event Management (SIEM) systems"
- SOAR (Security Orchestration, Automation, and Response): Platforms that automate and coordinate security operations workflows and incident responses. "feed SOAR platforms for automated response playbooks."
- Stdio transport: An MCP transport where the client launches the server as a subprocess and communicates via standard input/output. "a stdio transport, in which the client launches the MCP server as a subprocess and exchanges JSON-RPC messages over standard input and output"
- Streamable HTTP transport: An MCP transport using HTTP requests, optionally with SSE for streaming responses. "a Streamable HTTP transport, which uses HTTP POST and GET requests and may optionally employ Server-Sent Events (SSE) for streaming server-to-client messages"
- Supply-chain attack: Compromising systems by introducing malicious components in dependencies or third-party integrations. "supply-chain attackers who distribute compromised servers"
- Tamper-evident signatures: Cryptographic signatures or constructions that reveal any unauthorized alteration of logged events or data. "tamper-evident signatures"
- Tool poisoning: Maliciously manipulating tools or their outputs to steer an agent’s behavior in harmful ways. "tool poisoning"
- Threat model: A structured analysis of potential adversaries, their capabilities, and likely attack vectors. "We formalize the threat model for MCP deployments"
Collections
Sign up for free to add this paper to one or more collections.