- The paper introduces Seneca, a system that enhances data preprocessing by using model-driven cache partitioning and opportunistic data sampling.
- It demonstrates a 45.23% reduction in makespan and up to a 3.45x increase in data processing throughput across diverse hardware setups.
- By partitioning cache into encoded, decoded, and augmented forms, Seneca efficiently addresses ML training bottlenecks and prevents overfitting.
Efficient Data Preprocessing for ML Training with Seneca
Introduction
Seneca is a data loading system that addresses bottlenecks associated with input data preprocessing in ML training tasks. The system significantly enhances data storage and ingestion (DSI) pipeline efficiency by introducing two core techniques: a performance-driven cache partitioning strategy and opportunistic data sampling.
Seneca optimizes DSI throughput by strategically partitioning the cache into three forms: encoded, decoded, and augmented. By doing so, it mitigates common bottlenecks that arise during the training of multimedia models across multiple concurrent jobs. The implementation of Seneca has been evaluated against state-of-the-art caching systems, showcasing its superior cache utilization and throughput enhancements.
Challenges in Data Preprocessing
The DSI pipeline, a critical component of ML training, involves fetching, decoding, transforming, and loading data into GPUs. Inefficiencies in data preprocessing can bottleneck GPU training performance—a problem exacerbated by the growing disparity between CPU and GPU compute capabilities (Figure 1).
A particular challenge lies in choosing the optimal form of data to cache. Encoded data is storage-efficient but requires extensive preprocessing, while decoded and augmented forms reduce computational overhead at the cost of cache memory. Making trade-offs to achieve the best throughput under different hardware and dataset constraints remains an open problem, which Seneca aims to solve.
Seneca Design
Model-Driven Partitioning (MDP)
MDP employs a high-level performance model to partition cache space optimally. This method predicts DSI throughput based on the training node's capabilities, such as CPU and GPU throughput, as well as the potential bandwidth of cache and storage services. By determining the slowest pipeline component, MDP effectively allocates cache to maximize throughput.
Opportunistic Data Sampling (ODS)
ODS enhances cache efficiency by ensuring increased cache hit rates. It replaces uncached data samples with cached ones, maintaining randomness and pseudo-random sequence requirements crucial for ML model training. This sampling approach prevents overfitting due to redundant data usage, especially in concurrent job scenarios where multiple models train over the same dataset.
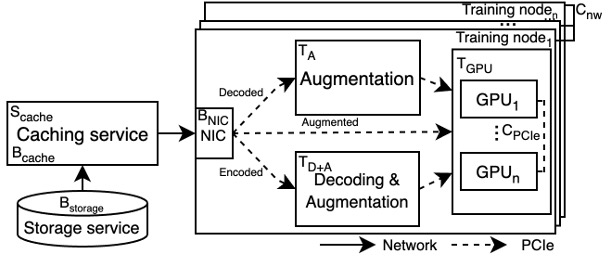
Figure 2: The DSI pipeline model.
Implementation and Evaluation
Seneca is implemented by extending the PyTorch dataloader framework, with caching managed using Redis. The system was rigorously evaluated across different hardware configurations, showing a remarkable improvement in reducing the makespan by 45.23% over PyTorch and increasing data processing throughput by up to 3.45 times compared to the next best dataloader.
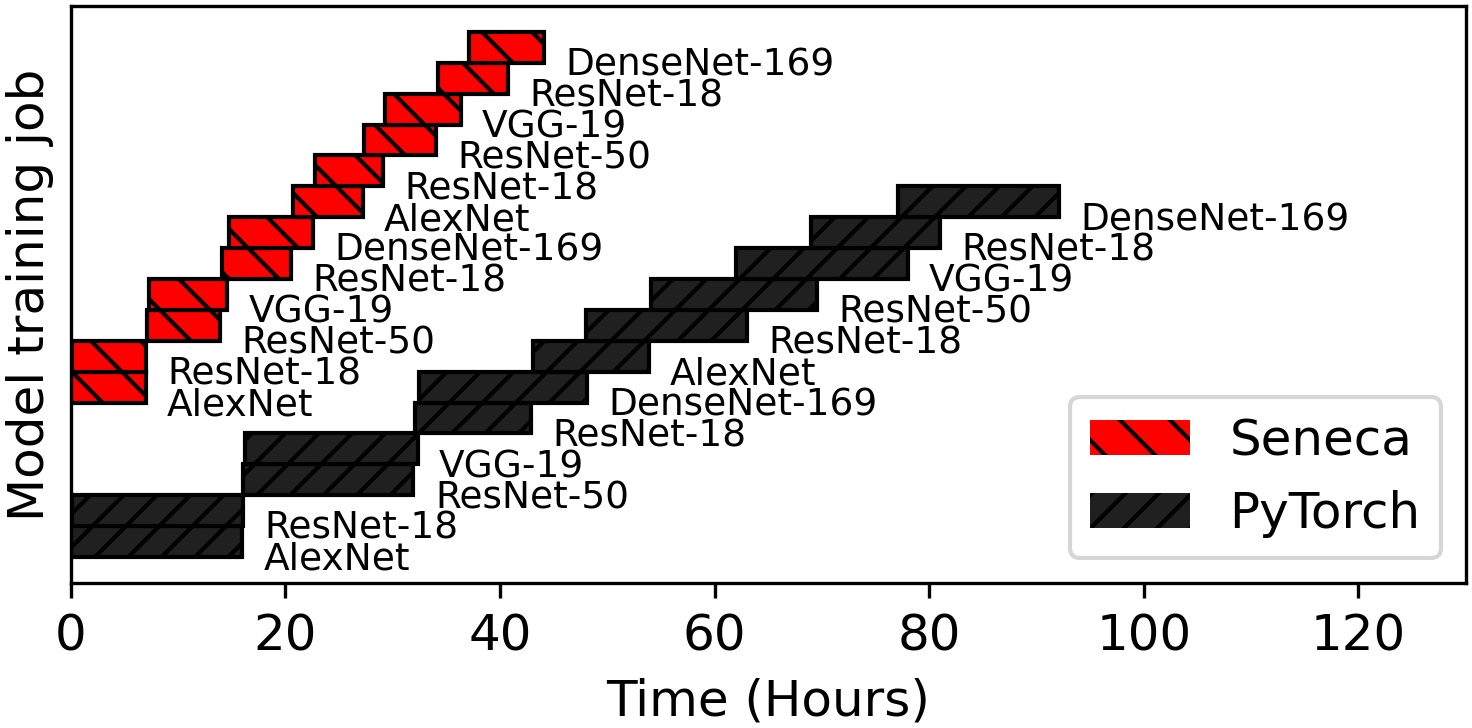
Figure 3: The model training time for 12 image classification jobs (50 epochs each) for 5 different models on the AWS server.
Seneca's performance model was validated against empirical data, achieving a high correlation, as depicted in Figure 4. This validation confirms the model's aptitude for accurately predicting throughput under various configurations, demonstrating that intelligent cache partitioning and opportunistic data sampling can alleviate bottlenecks in ML training.
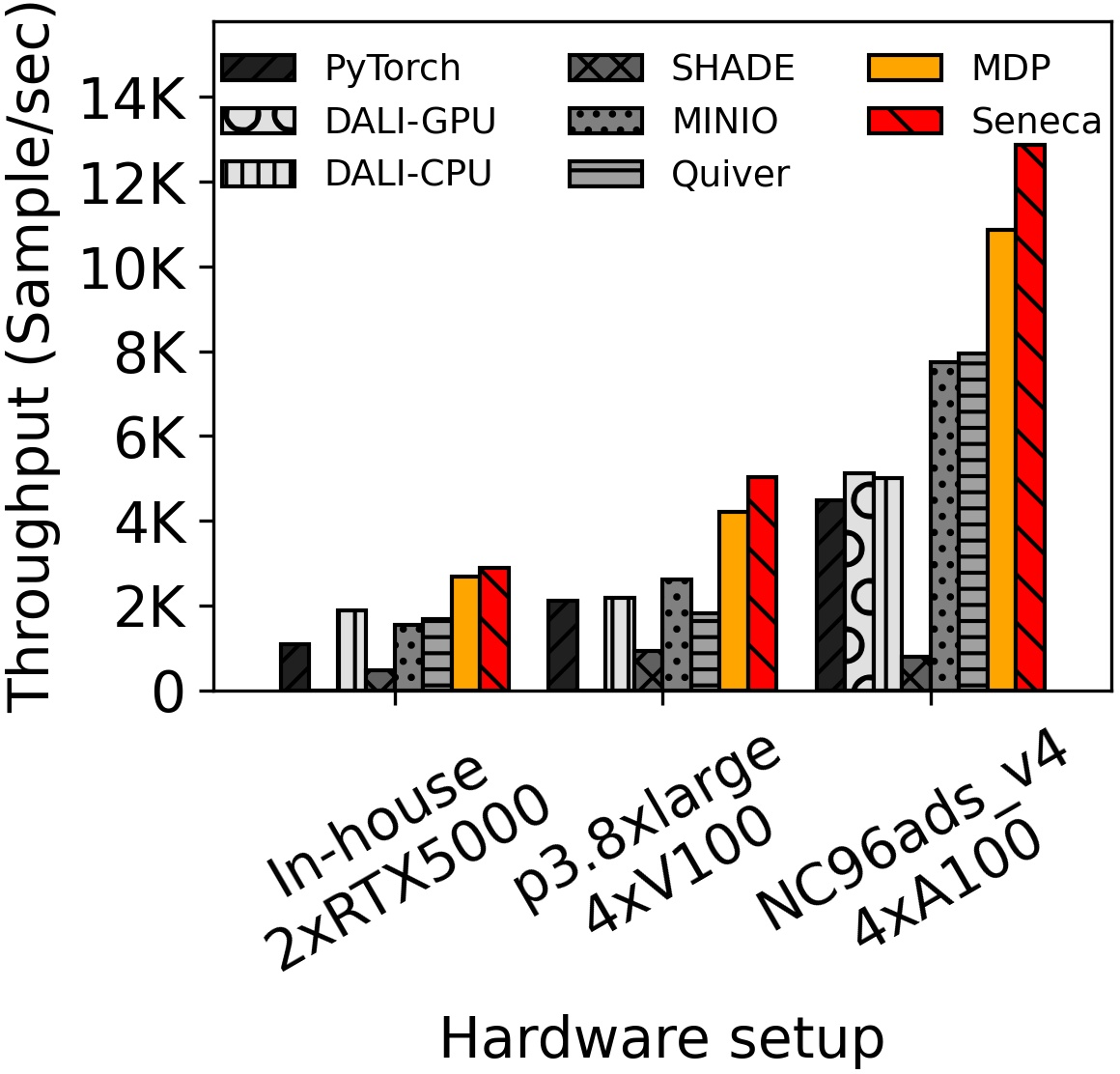
Figure 4: Throughput for training 2 jobs concurrently on different hardware platforms. Seneca performs well across a wide range of system configurations.
Conclusion
Seneca brings substantial improvements to the ML training process, particularly in environments where data-intensive preprocessing tasks constitute a major bottleneck. Through its dual-strategy approach of model-driven cache partitioning and opportunistic caching, Seneca maximizes resource efficiency and accelerates model convergence. The system sets a precedent for further research into dynamic caching strategies tailored to the diverse computational needs of modern machine learning models.

