- The paper proposes a novel framework that co-evaluates controllable video generation and end-to-end driving planners using the Behavior Permutation Test.
- It introduces a diffusion-based model with fine-grained control over scene layout, weather, and time-of-day, validated on a large-scale driving dataset.
- Synthetic data fine-tuning improves planner performance in out-of-distribution conditions, reducing ADE and enhancing generalization in challenging scenarios.
Co-Evaluation of End-to-End Driving and Video Generation Models: An Analysis of Drive&Gen
Introduction
The paper "Drive&Gen: Co-Evaluating End-to-End Driving and Video Generation Models" (2510.06209) presents a unified framework for the systematic co-evaluation of controllable video generation models and end-to-end (E2E) driving planners. The central thesis is that the fidelity and controllability of synthetic driving videos must be assessed not only by visual metrics but also by their impact on downstream planning models. The authors introduce a novel statistical metric, the Behavior Permutation Test (BPT), and demonstrate that high-quality, controllable video generation can both diagnose and improve E2E planner generalization, especially in out-of-distribution (OOD) operational design domains (ODDs).
Framework Overview and Methodology
The proposed framework leverages a diffusion-based video generation model, extended from W.A.L.T., to enable fine-grained control over scene layout (bounding boxes, road maps, ego pose) and operational conditions (weather, time-of-day). This controllability is critical for isolating the effects of specific factors on planner behavior and for generating targeted synthetic data for planner training and evaluation.
The co-evaluation pipeline consists of three main components:
- Controllable Video Generation: The model generates videos conditioned on explicit scene and operational parameters, allowing for systematic manipulation of environmental factors.
- E2E Planner Integration: A VLM-based E2E planner, built on PaLI and EMMA, consumes both real and generated videos, producing trajectory predictions.
- Statistical Evaluation: The BPT quantifies the similarity of planner outputs between real and synthetic videos under matched conditions, providing a direct measure of the sim-to-real gap relevant to planning.
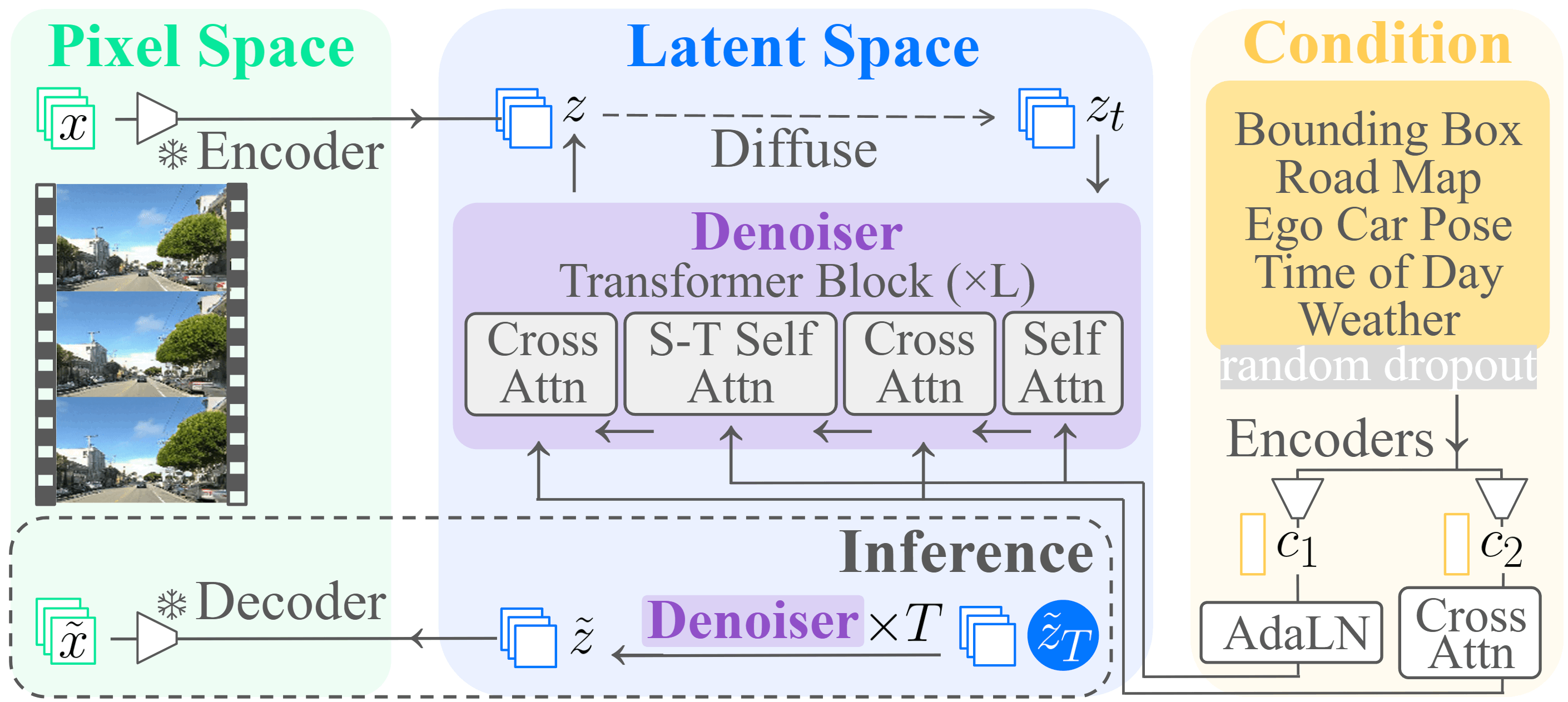
Figure 1: Model architecture of the video generation model, showing multi-modal conditioning and integration with the diffusion transformer.
Controllable Video Generation: Architecture and Capabilities
The video generation model is a latent diffusion transformer, extended to accept a rich set of control modalities:
- Bounding Boxes: 8D vectors per agent, projected and tokenized for efficient representation.
- Road Maps: Line segments with type encoding, reduced via latent query attention.
- Ego-Car Pose: 12D vector (rotation, translation).
- Time-of-Day: Encoded as sun angles (azimuth, elevation) for geographic and seasonal invariance.
- Weather: One-hot encoding for discrete conditions.
All condition embeddings are concatenated and processed via a transformer encoder, with cross-attention and AdaLN mechanisms enabling precise conditioning within the diffusion process. The model is trained on a large-scale real-world driving dataset (10M segments, 17 frames/segment, 128×128 resolution), with random dropout of conditions to enhance robustness.






Figure 2: Generated videos under various conditions, demonstrating control over layout, weather, and time-of-day.
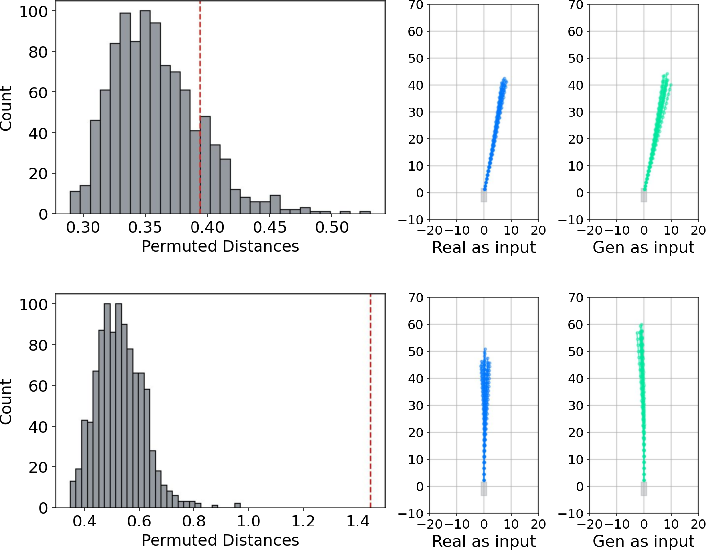
Behavior Permutation Test (BPT): A Planner-Centric Realism Metric
Traditional video generation metrics (e.g., FVD) are insufficient for evaluating the utility of synthetic data in planning contexts. The BPT addresses this by directly comparing the distribution of planner-predicted trajectories from real and generated videos under matched scene layouts.
Empirical Results
Video Generation Quality and Control
- BPT Fail-to-Reject Rate: 69.62% (out of 95% ceiling) when generating videos under the same conditions as real data, indicating substantial behavioral similarity.
- Ablation: Removing scene layout (bounding boxes, road maps) sharply degrades planner performance (ADE increases), while removing operational conditions (weather, time) has a smaller effect.
- Sun Angle Encoding: Outperforms local time encoding in FVD, ADE, and BPT, confirming the importance of physically grounded time-of-day representations.
Planner Evaluation and OOD Analysis
- ADE Sensitivity: Planner performance degrades under rain and nighttime, as measured by increased ADE, but the effect is less pronounced than removing scene layout.
- Controlled ODD Experiments: The framework enables isolation of specific ODD factors (e.g., weather, illumination) without confounding from real-world data distribution shifts.
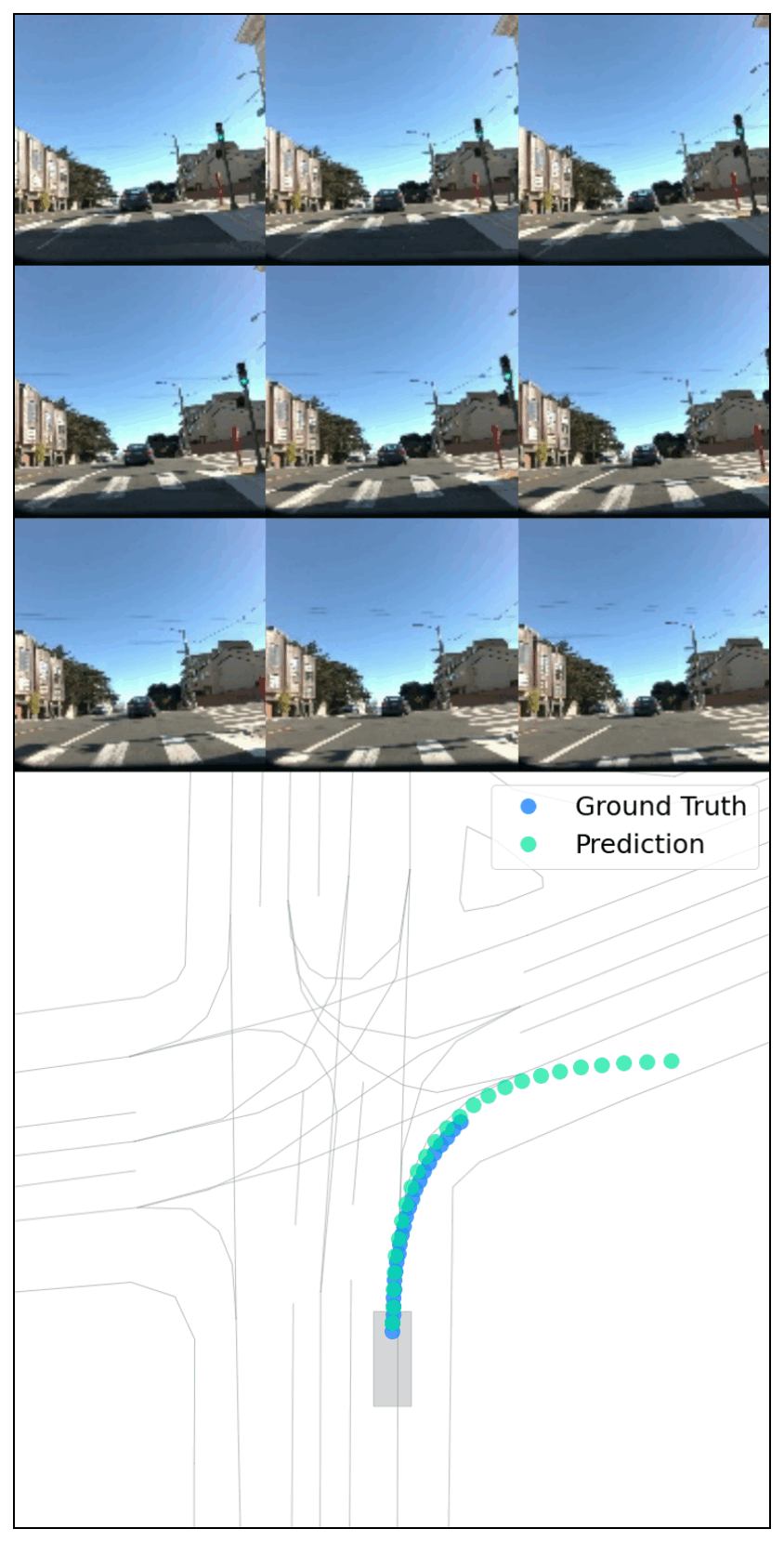
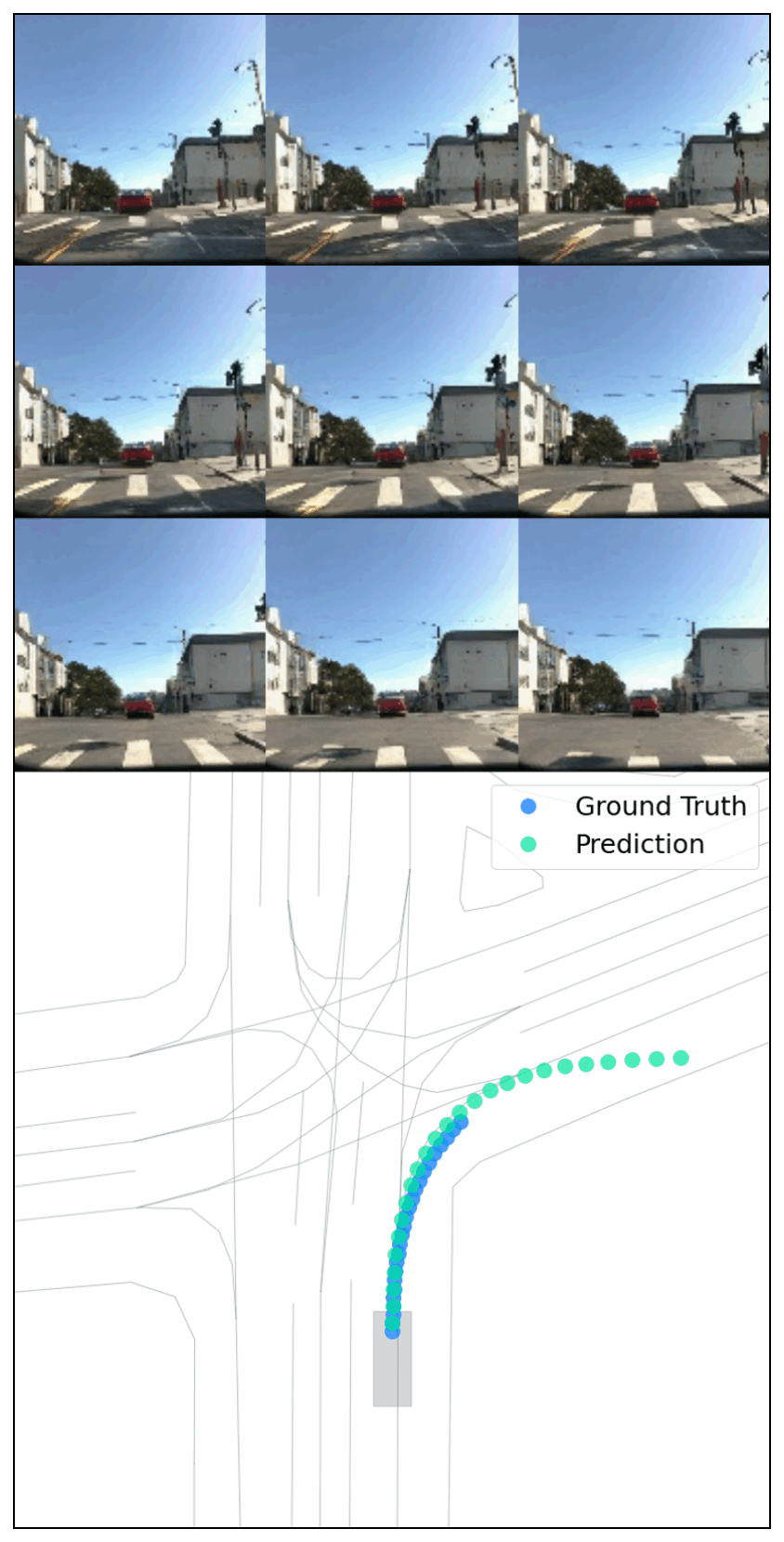
Figure 4: Planner-predicted trajectories are highly similar when given real and generated videos with identical scene layouts.
Synthetic Data for Planner Generalization
- Fine-Tuning with Synthetic Data: Incorporating 1M generated videos in planner fine-tuning reduces ADE@5s from 0.7548 (real only) to 0.7333 (gen+real).
- OOD Scenarios: Gains are more pronounced in rain and nighttime, with ADE@5s improvements of 1–2% over real-only fine-tuning.
- Qualitative Analysis: Synthetic data improves planner responses in challenging scenarios (e.g., green light handling, stopped vehicle bypass).




Figure 5: Qualitative improvement in planner behavior after fine-tuning with synthetic data.
Discussion and Implications
The co-evaluation framework provides a principled methodology for assessing both the realism of generative models and the robustness of E2E planners. The BPT, by focusing on planner behavior, aligns evaluation with the ultimate downstream task, circumventing the limitations of purely perceptual metrics. The demonstrated ability to improve planner generalization with synthetic data, especially in OOD conditions, has direct implications for reducing the cost and risk of real-world data collection and for accelerating the deployment of AV systems in new ODDs.
However, the BPT does not directly assess physical realism or safety-critical aspects; it is agnostic to the semantic correctness of planner outputs. Further work is needed to integrate safety and physical plausibility constraints into the evaluation loop.
Conclusion
This work establishes a comprehensive framework for the co-evaluation of controllable video generation and E2E planning models in autonomous driving. By introducing the BPT and demonstrating the utility of high-fidelity, controllable synthetic data, the paper advances the methodology for both simulation-based evaluation and data-driven planner improvement. The approach enables systematic diagnosis of planner weaknesses, targeted ODD expansion, and efficient synthetic data augmentation, with broad implications for the development and validation of robust AV systems.