- The paper presents a novel Declarative Data Pipeline (DDP) architecture that optimizes ML service scalability and maintainability through modular 'Pipes'.
- The DDP leverages Apache Spark and Scala to minimize network overhead and improve data processing, achieving up to 500x scalability and 10x throughput improvements.
- Performance evaluations demonstrate a reduction in development cycles by 50% and significant efficiency gains, confirming the framework’s practical impact on ML services.
Declarative Data Pipeline for Large Scale ML Services
Introduction
The paper "Declarative Data Pipeline for Large Scale ML Services" (2508.15105) addresses critical challenges in modern distributed data processing systems where high performance and scalability must be balanced with code maintainability and developer productivity. Traditional approaches often struggle to efficiently integrate ML capabilities at scale, particularly in collaborative environments characterized by high communication overhead. The authors present a novel architecture, named the Declarative Data Pipeline (DDP), which processes billions of records with notable improvements in accuracy and efficiency. This architecture departs from traditional microservice-based methods by establishing logical computation units termed "Pipes" within Apache Spark, allowing modular development and system optimization without sacrificing maintainability.
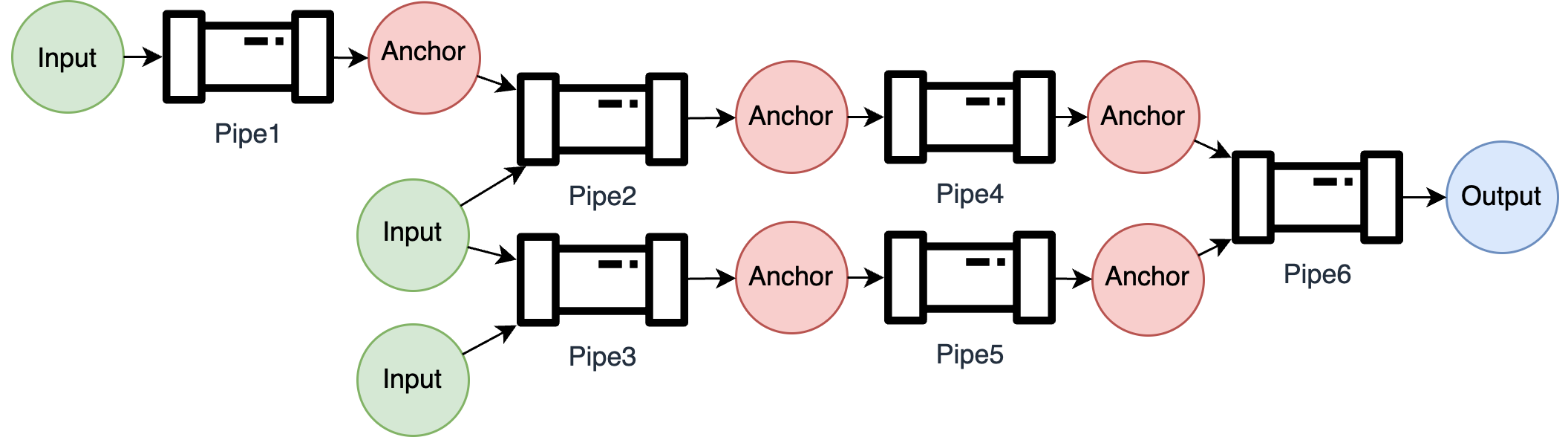
Figure 1: Dataset declarations serve as "anchor" in our pipeline architecture, specifying data attributes like location, schema, and encryption settings. These declarations form interfaces between pipe components, enabling modular development and independent data processing units.
Architecture Design and Implementation
The DDP architecture introduces modular "Pipes" which perform specific data transformations, while being chained together using system memory interfaces instead of network APIs, effectively reducing network overhead. Each "Pipe" functions as a standalone computational unit, interfacing with standardized data schemas and attributes, allowing precise control over data transformations without extensive periphery coding. The Pipes offer standardized modules that encapsulate logic, handle data I/O, encryption, metrics tracking, and execution orchestration, promoting system modularity, code reusability, and simplified testing.
The implementation in Scala provides performance advantages over languages like Python, reducing overhead from serialization/deserialization operations across JVM environments. Additionally, ML models developed in Python can be integrated directly within the Spark cluster using Open Neural Network Exchange (ONNX), mitigating performance impacts associated with microservice integration.
Previous solutions like SystemML [boehm2016systemml], which uses high-level languages for ML algorithm specification and optimization, and Cedar [zhao2024cedar], which employs composable operators for input data pipeline construction, have limitations in dynamic environments or impose significant profiling and optimization overheads. The DDP architecture contrasts these by ensuring predictable behavior with clear component boundaries, fostering parallel development and eliminating complexity typically seen in monolithic architectures.
In the context of workflow orchestration systems such as Apache Airflow and Kubeflow Pipelines, DDP offers predefined data contracts that promote ease of integration and scalability, while also supporting dynamic pipeline composition without altering the underlying framework.
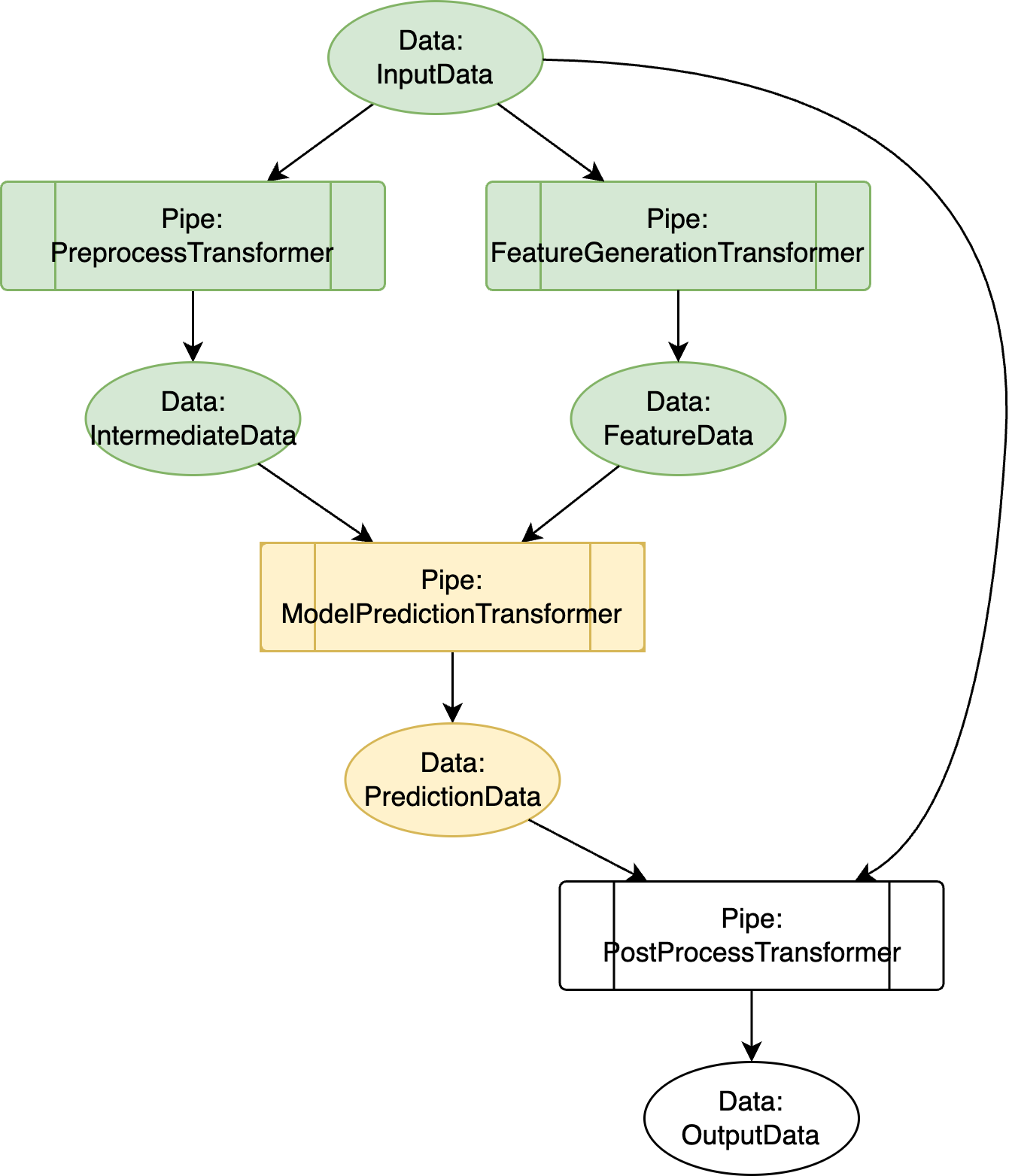
Figure 2: Workflow visualization for an ML data pipeline definition with preprocessing, feature generalization, and model prediction steps. Different colors signify stages: green for completed steps, yellow for in-progress steps, and white for steps not started.
In an enterprise setting, DDP dramatically reduced the development cycle from months to days, with development efficiency improving by 50%. The transformation yielded substantial scalability enhancements, up to 500 times higher, and increased throughput by 10 times compared to previous implementations. Academically, DDP attained at least 5.7 times faster throughput in language detection tasks with 99% CPU usage, outperforming non-framework implementations.
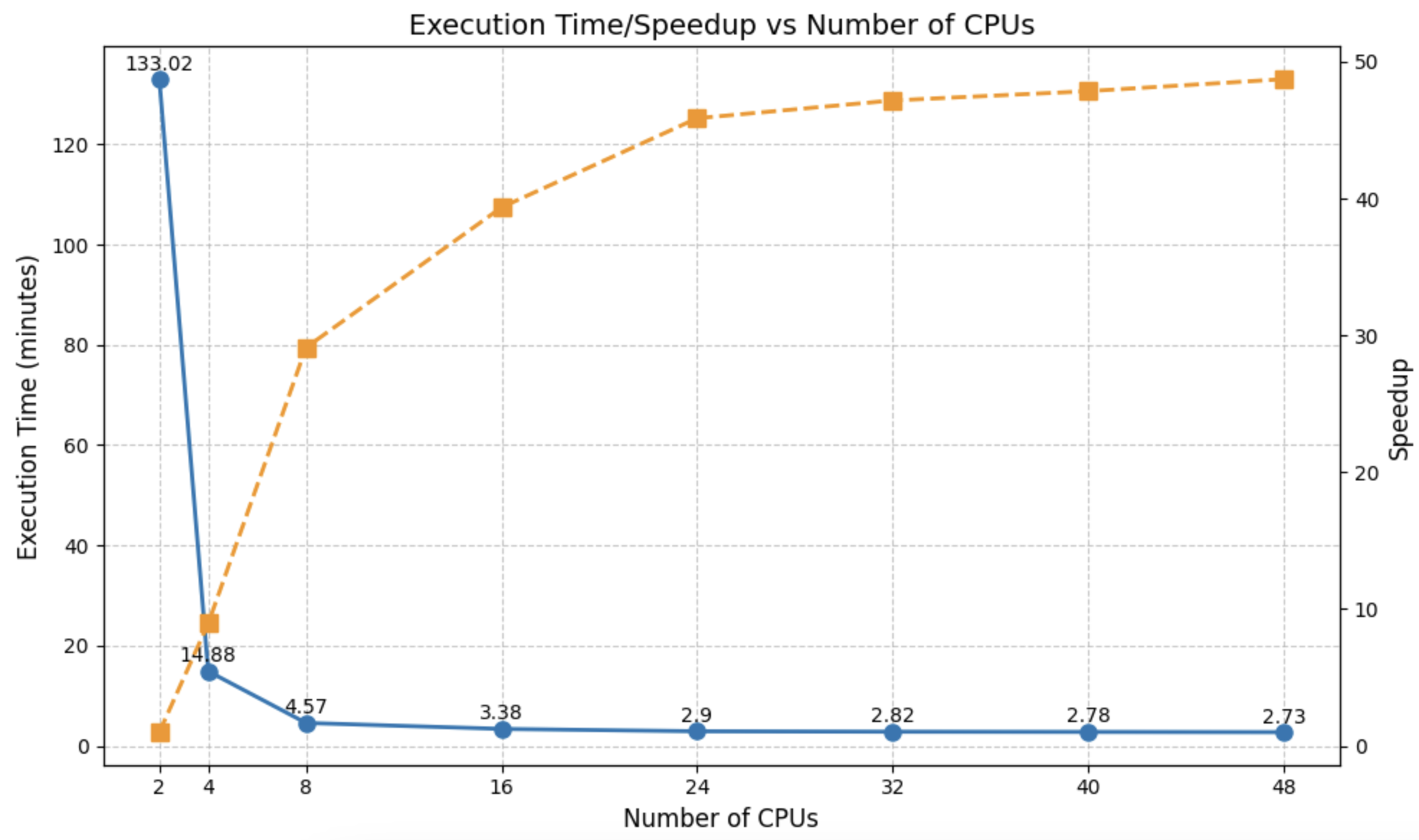
Figure 3: Scalability Evaluation of Distributed Computing.
Conclusion
The "Declarative Data Pipeline for Large Scale ML Services" provides a robust solution to the challenges in distributed data processing systems. The DDP architecture fundamentally redefines how ML capabilities are integrated at scale, offering an efficient blend of modularity, performance, and maintainability. By establishing clear component boundaries, Pipes allow for parallel development and simplified integration, while ensuring efficient utilization of system resources through strategic architectural choices. These outcomes fortify the DDP framework as a compelling approach for managing scalable, maintainable data processing systems.
Future Directions
Future work may extend DDP to encompass streaming data scenarios, enabling real-time analytics and further integration of advanced ML models. Exploring enhanced automated testing strategies for distributed systems and GPU-based task processing could offer additional performance and productivity benefits.

