Harnessing Large Language Models for Training-free Video Anomaly Detection
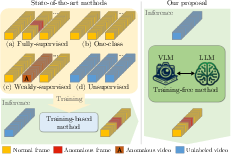
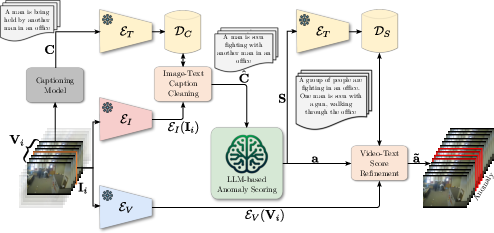
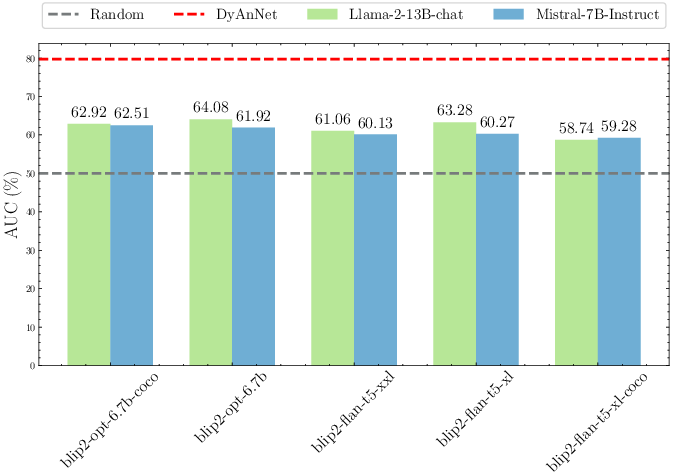
Abstract: Video anomaly detection (VAD) aims to temporally locate abnormal events in a video. Existing works mostly rely on training deep models to learn the distribution of normality with either video-level supervision, one-class supervision, or in an unsupervised setting. Training-based methods are prone to be domain-specific, thus being costly for practical deployment as any domain change will involve data collection and model training. In this paper, we radically depart from previous efforts and propose LAnguage-based VAD (LAVAD), a method tackling VAD in a novel, training-free paradigm, exploiting the capabilities of pre-trained LLMs and existing vision-LLMs (VLMs). We leverage VLM-based captioning models to generate textual descriptions for each frame of any test video. With the textual scene description, we then devise a prompting mechanism to unlock the capability of LLMs in terms of temporal aggregation and anomaly score estimation, turning LLMs into an effective video anomaly detector. We further leverage modality-aligned VLMs and propose effective techniques based on cross-modal similarity for cleaning noisy captions and refining the LLM-based anomaly scores. We evaluate LAVAD on two large datasets featuring real-world surveillance scenarios (UCF-Crime and XD-Violence), showing that it outperforms both unsupervised and one-class methods without requiring any training or data collection.
- Traffic anomaly detection via perspective map based on spatial-temporal information matrix. In CVPRW, 2019.
- Mgfn: Magnitude-contrastive glance-and-focus network for weakly-supervised video anomaly detection. In AAAI, 2023.
- An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
- Semantic anomaly detection with large language models. Autonomous Robots, 2023.
- Mist: Multiple instance self-training framework for video anomaly detection. In CVPR, 2021.
- Imagebind: One embedding space to bind them all. In CVPR, 2023.
- Anomalygpt: Detecting industrial anomalies using large vision-language models. arXiv, 2023.
- Learning temporal regularity in video sequences. In CVPR, 2016.
- Mistral 7b. arXiv, 2023.
- Survey on video anomaly detection in dynamic scenes with moving cameras. Artificial Intelligence Review, 2023.
- Clip-tsa: Clip-assisted temporal self-attention for weakly-supervised video anomaly detection. In ICIP, 2023.
- Unsupervised video anomaly detection based on similarity with predefined text descriptions. Sensors, 2023.
- Scale-aware spatio-temporal relation learning for video anomaly detection. In ECCV, 2022a.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In ICML, 2023.
- Self-training multi-sequence learning with transformer for weakly supervised video anomaly detection. In AAAI, 2022b.
- Isolation-based anomaly detection. ACM TKDD, 2012.
- Improved baselines with visual instruction tuning. arXiv, 2023.
- A hybrid video anomaly detection framework via memory-augmented flow reconstruction and flow-guided frame prediction. In ICCV, 2021.
- Abnormal event detection at 150 fps in matlab. In ICCV, 2013.
- Learning normal dynamics in videos with meta prototype network. In CVPR, 2021.
- Learning memory-guided normality for anomaly detection. In CVPR, 2020.
- Learning transferable visual models from natural language supervision. In ICML, 2021.
- Subspace support vector data description. In ICPR, 2018.
- Real-world anomaly detection in surveillance videos. In CVPR, 2018.
- Hierarchical semantic contrast for scene-aware video anomaly detection. In CVPR, 2023.
- Rareanom: A benchmark video dataset for rare type anomalies. Pattern Recognition, 2023a.
- Dyannet: A scene dynamicity guided self-trained video anomaly detection network. In WACV, 2023b.
- Weakly-supervised video anomaly detection with robust temporal feature magnitude learning. In ICCV, 2021.
- Llama: Open and efficient foundation language models. arXiv, 2023.
- Exploring diffusion models for unsupervised video anomaly detection. In ICIP, 2023a.
- Unsupervised video anomaly detection with diffusion models conditioned on compact motion representations. In ICIAP, 2023b.
- Anomaly candidate identification and starting time estimation of vehicles from traffic videos. In CVPRW, 2019.
- Gods: Generalized one-class discriminative subspaces for anomaly detection. In ICCV, 2019.
- Self-supervised sparse representation for video anomaly detection. In ECCV, 2022.
- Learning causal temporal relation and feature discrimination for anomaly detection. IEEE TIP, 2021.
- Not only look, but also listen: Learning multimodal violence detection under weak supervision. In ECCV, 2020.
- Feature prediction diffusion model for video anomaly detection. In ICCV, 2023.
- Old is gold: Redefining the adversarially learned one-class classifier training paradigm. In CVPR, 2020a.
- Claws: Clustering assisted weakly supervised learning with normalcy suppression for anomalous event detection. In ECCV, 2020b.
- Generative cooperative learning for unsupervised video anomaly detection. In CVPR, 2022.
- Temporal convolutional network with complementary inner bag loss for weakly supervised anomaly detection. In ICIP, 2019.
- Graph convolutional label noise cleaner: Train a plug-and-play action classifier for anomaly detection. In CVPR, 2019.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.