- The paper presents OnIS, a framework that enables one-shot imitation and zero-shot adaptation through multi-modal semantic skill representation.
- It employs a vision-language model with contrastive learning to encode semantic skills and a dynamics-aware module for real-time skill transfer.
- Evaluations in simulated and real-world tasks demonstrate improved success rates and robust generalization compared to prior methods.
One-shot Imitation in a Non-Stationary Environment via Multi-Modal Skill
The paper "One-shot Imitation in a Non-Stationary Environment via Multi-Modal Skill" (2402.08369) presents a novel framework, OnIS, to address the challenge of one-shot imitation and zero-shot adaptation for autonomous agents performing complex tasks in non-stationary environments. This framework leverages semantic skill representation using a vision-LLM, combined with meta-learning techniques, to enable task decomposition and dynamics-aware skill transfer.
Introduction
The paper focuses on tackling the one-shot imitation problem where an autonomous agent can learn a complex new task from only a single demonstration. The approach uses skill-based imitation learning to handle tasks with changing dynamics across various domains in non-stationary environments. The authors propose leveraging the compositionality inherent in control tasks and semantic representations developed by vision-language pretrained models. This method enables the adaptation of the learned skills to various dynamic conditions without explicit task-specific training on each condition.
The problem is formulated within the context of Hidden Parameter Markov Decision Processes (HiP-MDP), allowing for dynamic variation over time without requiring explicit reward signals. The challenge lies in the agent's ability to infer a semantic skill sequence from a demonstration, adapt it dynamically, and execute actions optimized for current environmental conditions. This setup is illustrated using multi-stage tasks requiring sequential execution of subtasks in the Meta-world environment, a simulated robotics manipulation platform.
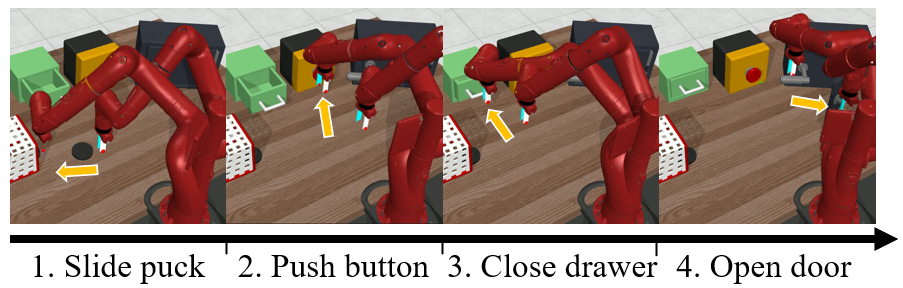
Figure 1: Multi-stage Meta-world task.
Our Approach
Semantic Skill Learning
The OnIS framework includes a semantic skill sequence encoder using a vision-LLM such as CLIP to learn semantic skill representations. The semantic skill sequence encoder employs prompt-based contrastive learning to translate video demonstrations into temporally organized semantic skills.
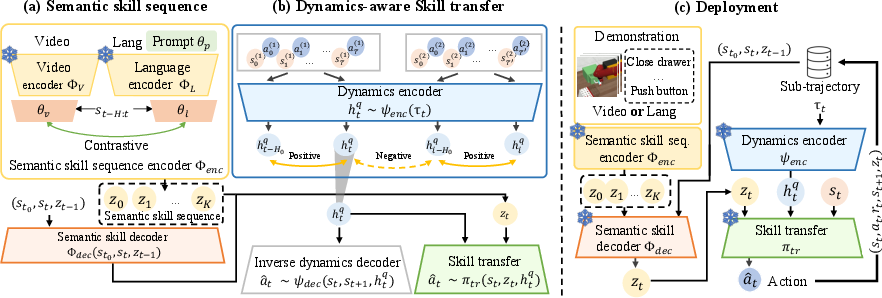
Figure 2: OnIS framework: In (a), the semantic skill sequence encoder Φenc and the semantic skill decoder Φdec are trained offline using the CLIP vision-language pretrained model.
The skills generated hold semantic correspondence with actions required to complete the task, enabling zero-shot adaptation across different task dynamics by employing a dynamic-aware skill transfer scheme.
Dynamics-aware Skill Transfer
The paper introduces a novel dynamics encoder and skill transfer module trained jointly via contrastive learning and behavior cloning, enabling real-time adaptation to changing environmental dynamics. The framework optimizes action sequences based on inferred current dynamics and semantic skills, facilitating reliable execution across diverse conditions.
Evaluations
The framework is evaluated in the Meta-world environment, demonstrating superior performance in tasks where unseen dynamics are presented. Results show significant improvement in task success rates and robust generalization across varied dynamic conditions compared to existing methods such as BC-Z and SPiRL.
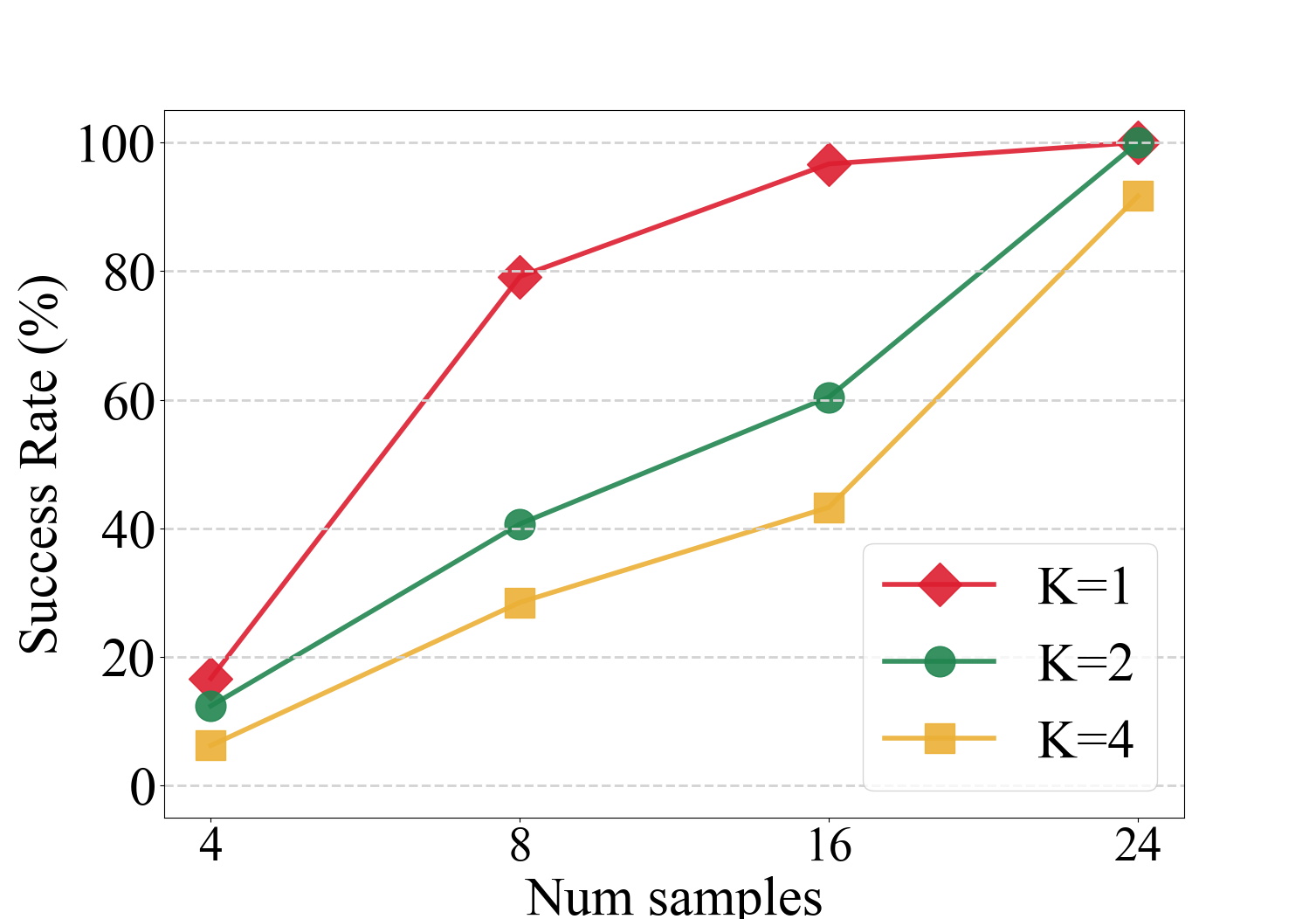
Figure 3: Effect by annotated sample size: the x-axis denotes the number of annotated samples used for training the semantic skill sequence encoder in S-OnIS, and the y-axis denotes the one-shot imitation performance by S-OnIS.
Use Cases
Real-world Demonstrations
The framework successfully handles real-world video demonstrations, validating its robustness and practical applicability. Real-world tests show that OnIS can accurately infer task semantics and perform corresponding actions even with variances in demonstration quality.
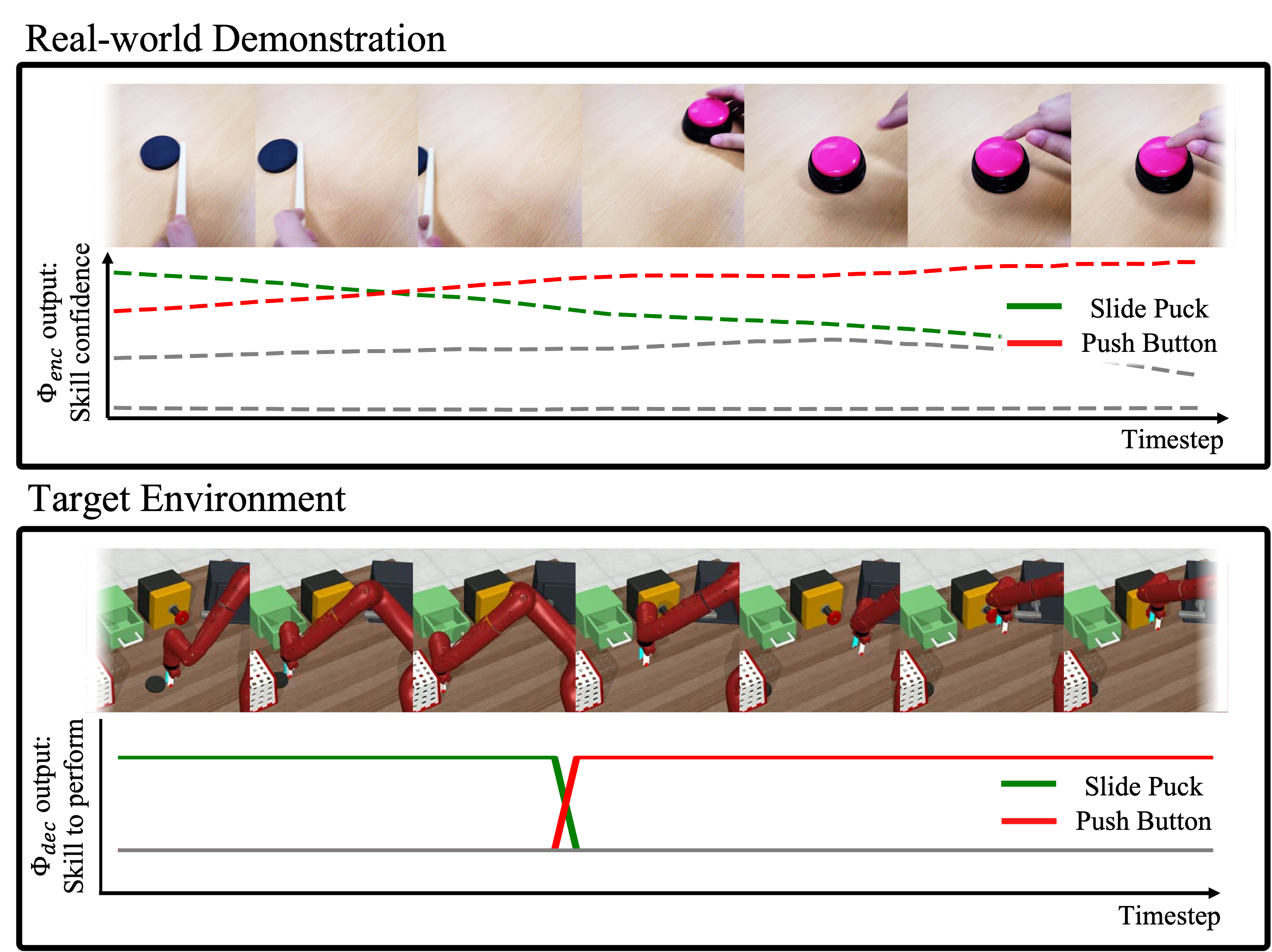
Figure 4: Real-world demonstrations.
The framework's efficacy in handling noisy demonstrations and strict performance requirements is further enhanced by the semantic embedding approach, which aligns demonstrated and executed task trajectories effectively.
Conclusion
OnIS represents a significant step towards enabling one-shot imitation learning in non-stationary environments. By combining semantic skill representation with dynamics-aware adaptation methods, this framework shows not only elevated performance but also promising scalability and versatility in implementing real-world applications. Future work may focus on extending this approach to environments with limited data availability and exploring further enhancements in semantic skill compositionality.

